En este post, vamos a aprender a hacer scraping web con python. Usando python vamos a scrapear Yahoo Finance. Esta es una gran fuente de datos del mercado de valores. Vamos a codificar un scraper para eso. Usando ese scraper serás capaz de raspar datos bursátiles de cualquier compañía desde yahoo finance. Como usted sabe que me gusta hacer las cosas muy simples, para que, también se utiliza un raspador web que aumentará su eficiencia de raspado.
¿Por qué esta herramienta? Esta herramienta nos ayudará a raspar sitios web dinámicos utilizando millones de proxies rotativos para que no nos bloqueen. También proporciona una facilidad de limpieza. Utiliza headerless chrome para scrapear sitios web dinámicos.
Generalmente, el web scraping se divide en dos partes:
- Obtención de datos haciendo una petición HTTP
- Extracción de datos importantes analizando el HTML DOM
Bibliotecas &Herramientas
- Beautiful Soup es una biblioteca de Python para extraer datos de archivos HTML y XML.
- Las solicitudes permiten enviar peticiones HTTP muy fácilmente.
- herramienta de raspado web para extraer el código HTML de la URL de destino.
Configuración
Nuestra configuración es bastante sencilla. Sólo tiene que crear una carpeta e instalar Beautiful Soup & solicitudes. Para crear una carpeta e instalar las bibliotecas escriba los comandos dados a continuación. Estoy asumiendo que usted ya ha instalado Python 3.x.
mkdir scraper
pip install beautifulsoup4
pip install requests
Ahora, crear un archivo dentro de esa carpeta por cualquier nombre que te gusta. Yo estoy usando scraping.py.
Primero, tienes que registrarte en la API de scrapingdog. Te proporcionará 1000 créditos GRATIS. A continuación, sólo la importación de Beautiful Soup & solicitudes en su archivo. como este.
from bs4 import BeautifulSoup
import requests
Lo que vamos a raspar
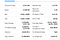
Aquí está la lista de campos que vamos a extraer:
- Cierre anterior
- Apertura
- Oferta
- Venta
- Rango del día
- Rango de 52 semanas
- Volumen
- Volumen medio
- Capitalización bursátil
- Beta
- Razón PE
- EPS
- Tasa de ganancia
- Dividendo adelantado &Rendimiento
- Ex.Dividendo &Fecha
- 1y objetivo EST
. Volumen
Preparando la comida
Ahora, ya que tenemos todos los ingredientes para preparar el scraper, debemos hacer una petición GET a la URL de destino para obtener los datos HTML en bruto. Si no estás familiarizado con la herramienta de scraping, te recomiendo que consultes su documentación. Ahora vamos a raspar Yahoo Finance para los datos financieros utilizando la biblioteca de solicitudes como se muestra a continuación.
r = requests.get("https://api.scrapingdog.com/scrape?api_key=<your-api-key>&url=https://finance.yahoo.com/quote/AMZN?p=AMZN&.tsrc=fin-srch").text
esto le proporcionará un código HTML de esa URL de destino.
Ahora, usted tiene que utilizar BeautifulSoup para analizar el HTML.
soup = BeautifulSoup(r,'html.parser')
Ahora, en toda la página, tenemos cuatro etiquetas «tbody». Nos interesan las dos primeras porque actualmente no necesitamos los datos disponibles dentro de las terceras &cuatro etiquetas «tbody».
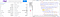
Primero, vamos a averiguar todas esas etiquetas «tbody» utilizando la variable «soup».
alldata = soup.find_all("tbody")

Como puedes observar los dos primeros «tbody» tienen 8 etiquetas «tr» y cada etiqueta «tr» tiene dos etiquetas «td».
try:
table1 = alldata.find_all("tr")
except:
table1=Nonetry:
table2 = alldata.find_all("tr")
except:
table2 = None
Ahora, cada etiqueta «tr» tiene dos etiquetas «td». La primera etiqueta «td» consiste en el nombre de la propiedad y la otra tiene el valor de esa propiedad. Es algo así como un par clave-valor.

En este punto, vamos a declarar una lista y un diccionario antes de iniciar un bucle for.
l={}
u=list()
Para simplificar el código voy a ejecutar dos bucles «for» diferentes para cada tabla. Primero para «tabla1»
for i in range(0,len(table1)):
try:
table1_td = table1.find_all("td")
except:
table1_td = None l.text] = table1_td.text u.append(l)
l={}
Ahora, lo que hemos hecho es que estamos almacenando todas las etiquetas td en una variable «tabla1_td». Y luego estamos almacenando el valor de la primera & segunda etiqueta td en un «diccionario». Luego estamos empujando el diccionario en una lista. Como no queremos almacenar datos duplicados vamos a hacer que el diccionario esté vacío al final. Pasos similares se seguirán para «table2».
for i in range(0,len(table2)):
try:
table2_td = table2.find_all("td")
except:
table2_td = None l.text] = table2_td.text u.append(l)
l={}
Entonces al final cuando se imprime la lista «u» se obtiene una respuesta JSON.
{
"Yahoo finance":
}
No es increíble. Hemos conseguido scrapear las finanzas de Yahoo en apenas 5 minutos de configuración. Tenemos un array de python Object que contiene los datos financieros de la empresa Amazon. De esta manera, podemos raspar los datos de cualquier sitio web.
Conclusión
En este artículo, hemos entendido cómo podemos raspar datos utilizando la herramienta de raspado de datos & BeautifulSoup independientemente del tipo de sitio web.
No dudes en comentar y preguntarme cualquier cosa. Puedes seguirme en Twitter y en Medium. ¡Gracias por leer y por favor dale al botón de «me gusta»! 👍
Recursos adicionales
¡Y ahí está la lista! En este punto, usted debe sentirse cómodo escribiendo su primer raspador web para recopilar datos de cualquier sitio web. Aquí hay algunos recursos adicionales que pueden ser útiles durante su viaje de raspado web:
- Lista de servicios proxy de raspado web
- Lista de herramientas prácticas de raspado web
- Documentación de BeautifulSoup
- Documentación de Scrapingdog
- Guía de raspado web