V průběhu let mělo mnoho lidí problémy s pravopisem mého jména. Když jsem byl mladší, předpokládal jsem, že jméno „Colin“ neslyšeli. V místě, kde jsem žil, to bylo dost neobvyklé. Za posledních dvacet let se jméno stalo populárnějším, ale problémy s pravopisem se nezlepšily. Ukázalo se, že v dnešní době je tu další problém: alternativní hláskování. Mohlo by být „Collin“ opravdu tak běžné jako „Colin“? Nevěřil jsem tomu.
Naštěstí Správa sociálního zabezpečení sleduje křestní jména podle data narození a tyto údaje dává volně k dispozici, takže jsem si na tuto otázku mohl odpovědět.
Ukázalo se, že „Collin“ zažil na přelomu století dramatický skok v popularitě a na chvíli zastínil (samozřejmě správné) „Colin“.
Kraf ukazuje relativní popularitu „Colin“ oproti „Collin u lidí narozených od roku 1940. V roce 1940 používalo asi 85 % těchto dvou jmen jedno „l“, což přetrvalo až do konce sedmdesátých let; varianta se dvěma „l“ se rychle ujala a kolem roku 1999 nakrátko překonala verzi s jedním „l“, od té doby však klesá.
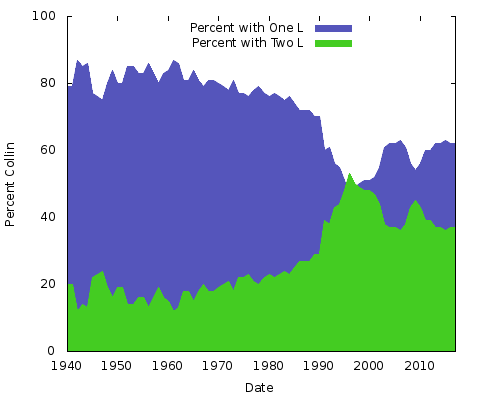
Co to všechno znamená? Nemám tušení. Ať už jsou důvody jakékoli, u jiných párů hláskování jmen budou jiné. Totéž byste mohli udělat pro „Eric“ vs. „Erik“ nebo „Rachel“ vs. „Rachael“ a mnoho dalších. Vlastně udělejme ty dva:
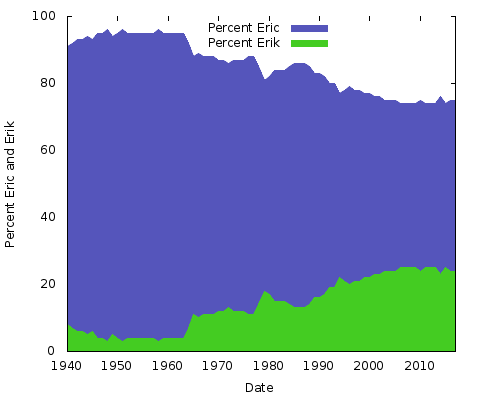
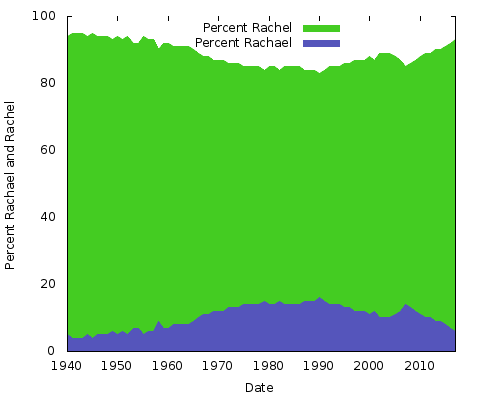
Jsou to jednoduché plošné grafy. Pro tento účel je mám raději než skládaný plošný graf; s pouhými dvěma řádky, kde součet hodnot obou os Y je vždy roven 100 %, byste skončili jen se stejným spodním řádkem a horní polovinou plné barvy. Takto získáte lepší představu o velké změně v oblíbenosti obou hláskování.
Skládaný plošný graf by byl skvělý pro zobrazení trendů více než dvou jmen: Pomocí grafu, jako je výše uvedený, byste například mohli ukázat změnu pohlaví spojenou se jmény v průběhu času pouze u jednoho jména, ale pomocí jednoho obrázku byste mohli naskládat více jmen a sdělit stejnou informaci:
Údaje o jménech dětí ze systému sociálního zabezpečení
Údaje pocházejí z webových stránek SSA, kde je veřejně k dispozici 1000 nejoblíbenějších dětských jmen pro každý rok narození v jejich evidenci. Před rokem 1940 jsou údaje poměrně kusé, protože správa byla zřízena až ve třicátých letech. Stále můžete získat jména sahající až do roku 1880, ale je jich méně, protože jsou zahrnuty pouze osoby, které se zapsaly ve třicátých letech a později.
Získat údaje můžete na této stránce SSA. Jsou v archivu .zip, který obsahuje samostatné soubory pro každý rok narození, a je tam i verze dat rozdělená podle států USA.
Data vypadají takto
Linda,F,99686Mary,F,71688Patricia,F,51278Barbara,F,48791Sandra,F,34774Carol,F,33538Nancy,F,32442Toto je z horní části souboru z roku 1947.
Soubory s jednotlivými roky budete chtít spojit do jednoho a pravděpodobně přidat sloupec „Rok narození“ (YOB), abyste je mohli snadněji používat pro tvorbu grafů souvisejících s časem. Napsal jsem k tomu malý skript v jazyce Ruby.
Chcete-li data předat nějakému grafickému balíku, budete je pravděpodobně muset ještě trochu rozmasírovat: Řádky s jedním názvem je třeba přeměnit na řádky se sloupci pro všechny datové body, které chcete zobrazit v grafu. Ty mohou být v jednom souboru nebo v každém řádku grafu jeden soubor (Gnuplot umožňuje pracovat tímto způsobem a načíst více souborů do jednoho grafu.) Můžete to udělat pomocí jazyka Ruby nebo Python. Já jsem to udělal pomocí SQL a nástroje „Q Text-as-Data“, pak jsem výsledek vložil do Gnuplotu.