V tomto příspěvku se naučíme škrábání webu pomocí Pythonu. Pomocí pythonu budeme scrapovat Yahoo Finance. Jedná se o skvělý zdroj dat o akciových trzích. Nakódujeme pro něj scraper. Pomocí tohoto scraperu budete moci z Yahoo Finance vyškrabávat data o akciích jakékoli společnosti. Jak víte, rád dělám věci dost jednoduše, a proto budu také používat webový scraper, který zvýší efektivitu vašeho scrapování.
Proč tento nástroj? Tento nástroj nám pomůže seškrabávat dynamické webové stránky pomocí milionů rotujících proxy serverů, takže nebudeme blokováni. Poskytuje také možnost vymazání. Ke škrábání dynamických webových stránek používá Chrome bez hlaviček.
Obecně se škrábání webových stránek dělí na dvě části:
- Získávání dat pomocí požadavku HTTP
- Vytahování důležitých dat pomocí rozboru DOM HTML
Knihovny & Nástroje
- Beautiful Soup je knihovna Pythonu pro vytahování dat ze souborů HTML a XML.
- Požadavky umožňují velmi snadno odesílat požadavky HTTP.
- Nástroj pro škrabání webu, který umožňuje extrahovat kód HTML cílové adresy URL.
Nastavení
Naše nastavení je poměrně jednoduché. Stačí vytvořit složku a nainstalovat požadavky Beautiful Soup &. Pro vytvoření složky a instalaci knihoven zadejte níže uvedené příkazy. Předpokládám, že jste již nainstalovali Python 3.x.
mkdir scraper
pip install beautifulsoup4
pip install requests
Nyní vytvořte uvnitř této složky soubor s libovolným názvem. Já používám scraping.py.
Nejprve se musíte přihlásit k API scrapingdog. To vám poskytne 1000 kreditů ZDARMA. Pak stačí do souboru importovat Krásná polévka & požadavky. například takto.
from bs4 import BeautifulSoup
import requests
Co budeme škrabat
Tady je seznam polí, která budeme extrahovat:
- Předchozí Close
- Open
- Bid
- Ask
- Day’s Range
- 52 Week Range
- Volume
- Avg. Volume
- Market Cap
- Beta
- PE Ratio
- EPS
- Earnings Rate
- Forward Dividend & Yield
- Ex.Dividend & Date
- 1y target EST
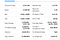
Příprava potravin
Teď, protože máme všechny ingredience pro přípravu škrabky, měli bychom provést požadavek GET na cílovou adresu URL, abychom získali surová data HTML. Pokud nejste obeznámeni s nástrojem pro škrábání, doporučuji vám projít si jeho dokumentaci. Nyní budeme škrábat finanční data Yahoo Finance pomocí knihovny požadavků, jak je znázorněno níže.
r = requests.get("https://api.scrapingdog.com/scrape?api_key=<your-api-key>&url=https://finance.yahoo.com/quote/AMZN?p=AMZN&.tsrc=fin-srch").text
Tím získáte kód HTML dané cílové adresy URL.
Nyní je třeba použít BeautifulSoup k analýze HTML.
soup = BeautifulSoup(r,'html.parser')
Nyní máme na celé stránce čtyři značky „tbody“. Nás zajímají první dvě, protože údaje dostupné uvnitř třetí &čtvrté značky „tbody“ momentálně nepotřebujeme.
Nejprve zjistíme všechny tyto značky „tbody“ pomocí proměnné „soup“.
alldata = soup.find_all("tbody")

Jak si můžete všimnout, první dva „tbody“ mají 8 tagů „tr“ a každý tag „tr“ má dva tagy „td“.
try:
table1 = alldata.find_all("tr")
except:
table1=Nonetry:
table2 = alldata.find_all("tr")
except:
table2 = None
Nyní má každá značka „tr“ dvě značky „td“. První značka „td“ obsahuje název vlastnosti a druhá značka obsahuje hodnotu této vlastnosti. Je to něco jako dvojice klíč-hodnota.

Na tomto místě budeme před spuštěním smyčky for deklarovat seznam a slovník.
l={}
u=list()
Pro zjednodušení kódu budu pro každou tabulku spouštět dvě různé smyčky „for“. Nejprve pro „tabulku1“
for i in range(0,len(table1)):
try:
table1_td = table1.find_all("td")
except:
table1_td = None l.text] = table1_td.text u.append(l)
l={}
Nyní jsme udělali to, že všechny značky td ukládáme do proměnné „tabulka1_td“. A pak ukládáme hodnotu první & druhé značky td do proměnné „dictionary“. Pak tento slovník přesuneme do seznamu. Protože nechceme ukládat duplicitní data, uděláme slovník na konci prázdný. Podobně budeme postupovat i u „tabulky2“.
for i in range(0,len(table2)):
try:
table2_td = table2.find_all("td")
except:
table2_td = None l.text] = table2_td.text u.append(l)
l={}
Pak na konci při vypsání seznamu „u“ dostaneme odpověď JSON.
{
"Yahoo finance":
}
Není to úžasné? Podařilo se nám vyškrábat Yahoo finance za pouhých 5 minut nastavení. Máme pole python Object obsahující finanční údaje společnosti Amazon. Tímto způsobem můžeme škrábat data z libovolné webové stránky.
Závěr
V tomto článku jsme pochopili, jak můžeme škrábat data pomocí nástroje pro škrábání dat & BeautifulSoup bez ohledu na typ webové stránky.
Neváhejte a komentujte a ptejte se mě na cokoli. Můžete mě sledovat na Twitteru a na Médiu. Děkuji za přečtení a stiskněte prosím tlačítko „To se mi líbí“! 👍
Další zdroje
A tady je seznam! V tuto chvíli byste se měli cítit pohodlně při psaní svého prvního webového scrapperu pro sběr dat z libovolných webových stránek. Zde je několik dalších zdrojů, které vám mohou být během vaší cesty za škrábáním webu užitečné:
- Seznam proxy služeb pro škrábání webu
- Seznam praktických nástrojů pro škrábání webu
- Dokumentace ke službě BeautifulSoup
- Dokumentace ke službě Scrapingdog
- Průvodce škrábáním webu
.