
Update : Wir haben eine interaktive Lern-App für maschinelles Lernen / KI eingeführt,>> Probieren Sie es jetzt kostenlos aus <<
Importieren Sie die erforderlichen Bibliotheken
import numpy as np
import pandas as pd
eps = np.finfo(float).eps
from numpy import log2 as log
‚eps‘ ist hier die kleinste darstellbare Zahl. Manchmal erhalten wir log(0) oder 0 im Nenner, um das zu vermeiden, werden wir dies verwenden.
Definieren Sie den Datensatz:
Erstellen Sie einen Pandas-Datenrahmen:
Erinnern wir uns nun an die Schritte zur Erstellung eines Entscheidungsbaums….
1.compute the entropy for data-set2.for every attribute/feature:
1.calculate entropy for all categorical values
2.take average information entropy for the current attribute
3.calculate gain for the current attribute3. pick the highest gain attribute.
4. Repeat until we get the tree we desired
- Finden Sie die Entropie und dann den Informationsgewinn für die Aufteilung des Datensatzes.
Wir werden eine Funktion definieren, die eine Klasse (Zielvariablenvektor) aufnimmt und die Entropie dieser Klasse findet.
Hier ist der Bruch ‚pi‘, es ist das Verhältnis der Anzahl der Elemente in der aufgeteilten Gruppe zur Anzahl der Elemente in der Gruppe vor der Aufteilung (Elterngruppe).

2 .Definiere nun eine Funktion {ent}, um die Entropie jedes Attributs zu berechnen :
Speichere die Entropie jedes Attributs mit seinem Namen :
a_entropy = {k:ent(df,k) for k in df.keys()}
a_entropy

3. Berechne den Infogain jedes Attributs :
Definiere eine Funktion zur Berechnung von IG (Infogain) :
IG(attr) = Entropie des Datensatzes – Entropie des Attributs
def ig(e_dataset,e_attr):
return(e_dataset-e_attr)
Speichere IG jedes attr in einem dict :
#entropy_node = entropy of dataset
#a_entropy = entropy of k(th) attrIG = {k:ig(entropy_node,a_entropy) for k in a_entropy}

Wie wir sehen können, hat outlook den höchsten Informationsgewinn von 0.24 , deshalb werden wir outook als Knoten auf dieser Ebene für die Aufteilung auswählen.
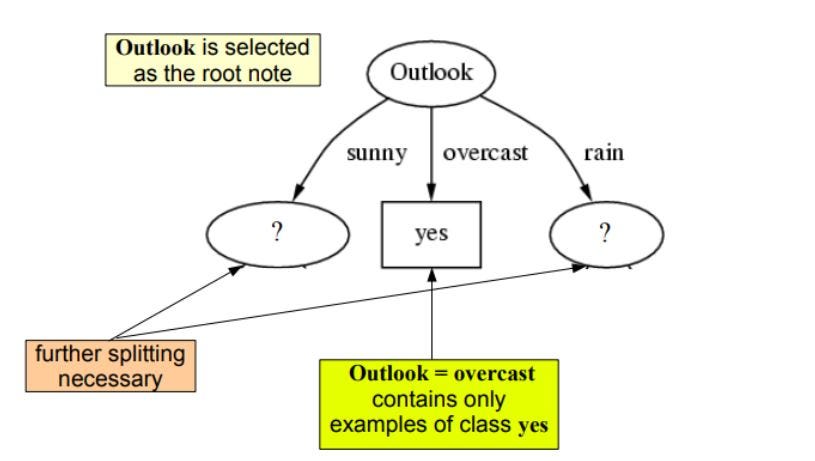
Um unseren Baum fortzusetzen, werden wir Rekursion verwenden
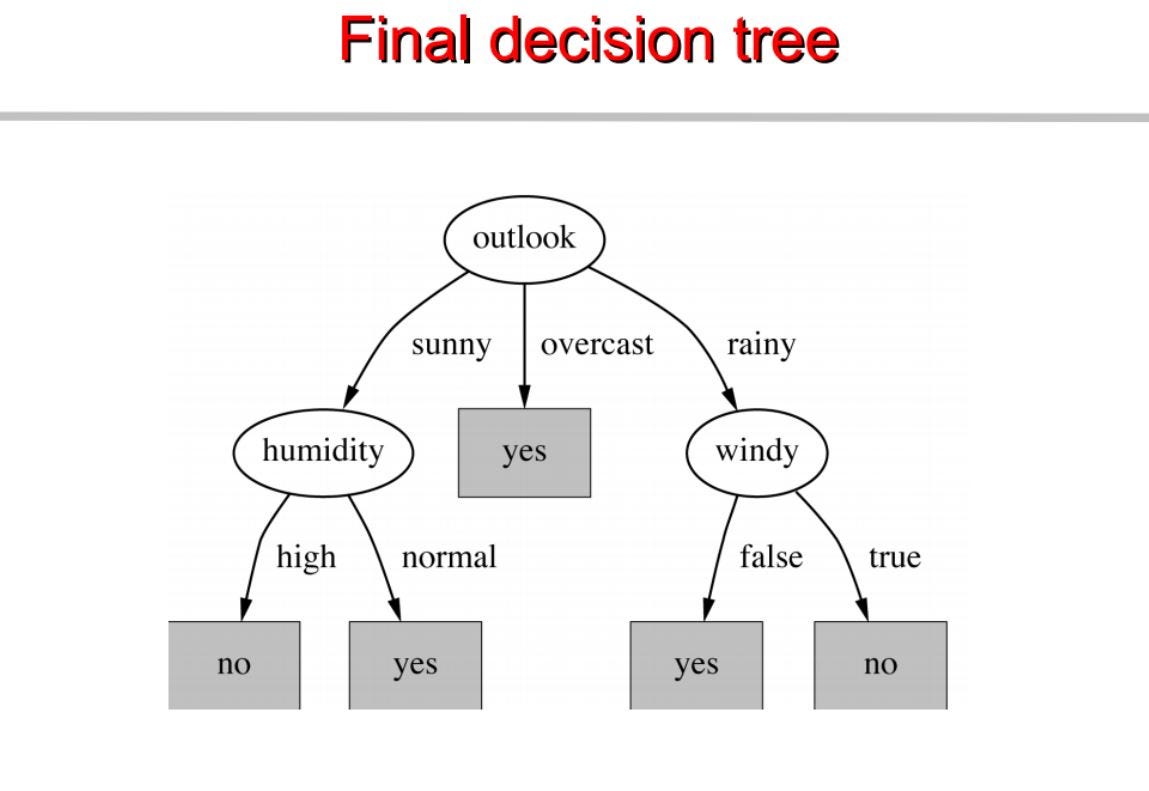
Wiederholen Sie dasselbe für die Unterbäume, bis wir den Baum erhalten.

Daraus bauen wir einen Entscheidungsbaum. Unten ist der komplette Code.

Besuche pytholabs.com für tolle Kurse