In diesem Beitrag werden wir Web Scraping mit Python lernen. Mit Python werden wir Yahoo Finance scrapen. Dies ist eine großartige Quelle für Börsendaten. Wir werden einen Scraper dafür programmieren. Mit diesem Scraper können Sie die Börsendaten eines beliebigen Unternehmens von Yahoo Finance abrufen. Wie Sie wissen, mache ich die Dinge gerne ziemlich einfach, deshalb werde ich auch einen Web Scraper verwenden, der die Effizienz des Scrappings erhöhen wird.
Warum dieses Tool? Dieses Tool hilft uns, dynamische Websites mit Millionen von rotierenden Proxys zu scrapen, damit wir nicht blockiert werden. Es bietet auch eine Clearing-Funktion. Es verwendet Headerless Chrome, um dynamische Websites zu scrapen.
Gemeinsam wird Web Scraping in zwei Teile unterteilt:
- Daten durch eine HTTP-Anfrage abrufen
- Wichtige Daten durch Parsen des HTML-DOM extrahieren
Bibliotheken & Tools
- Beautiful Soup ist eine Python-Bibliothek, um Daten aus HTML- und XML-Dateien zu extrahieren.
- Requests erlauben es, sehr einfach HTTP-Anfragen zu senden.
- Web Scraping Tool, um den HTML-Code der Ziel-URL zu extrahieren.
Setup
Unser Setup ist ziemlich einfach. Erstellen Sie einfach einen Ordner und installieren Sie Beautiful Soup & Anfragen. Um einen Ordner zu erstellen und die Bibliotheken zu installieren, geben Sie die unten angegebenen Befehle ein. Ich gehe davon aus, dass Sie Python 3.x bereits installiert haben.
mkdir scraper
pip install beautifulsoup4
pip install requests
Nun erstellen Sie eine Datei in diesem Ordner mit einem beliebigen Namen. Ich verwende scraping.py.
Zunächst müssen Sie sich für die scrapingdog API anmelden. Dadurch erhalten Sie 1000 kostenlose Credits. Dann importieren Sie einfach Beautiful Soup & Anfragen in Ihre Datei. etwa so.
from bs4 import BeautifulSoup
import requests
Was wir scrapen werden
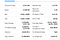
Hier ist die Liste der Felder, die wir extrahieren werden:
- Previous Close
- Open
- Bid
- Ask
- Day’s Range
- 52 Week Range
- Volume
- Avg. Volumen
- Marktkapital
- Beta
- PE Ratio
- EPS
- Gewinnrate
- Vorwärtsdividende &Rendite
- Ex-.Dividende &Datum
- 1Jahresziel EST
Zubereitung des Essens
Nun, Da wir nun alle Zutaten haben, um den Scraper vorzubereiten, sollten wir eine GET-Anfrage an die Ziel-URL stellen, um die HTML-Rohdaten zu erhalten. Wenn Sie mit dem Scraping-Tool nicht vertraut sind, empfehle ich Ihnen, sich die Dokumentation anzusehen. Jetzt werden wir Yahoo Finance nach Finanzdaten durchsuchen, indem wir die Anfragen-Bibliothek wie unten gezeigt verwenden.
r = requests.get("https://api.scrapingdog.com/scrape?api_key=<your-api-key>&url=https://finance.yahoo.com/quote/AMZN?p=AMZN&.tsrc=fin-srch").text
Damit erhalten Sie den HTML-Code der Ziel-URL.
Jetzt müssen Sie BeautifulSoup verwenden, um HTML zu parsen.
soup = BeautifulSoup(r,'html.parser')
Jetzt haben wir auf der gesamten Seite vier „tbody“-Tags. Wir interessieren uns für die ersten beiden, weil wir die Daten, die im dritten & vierten „tbody“-Tag vorhanden sind, momentan nicht brauchen.
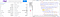
Zunächst werden wir alle diese „tbody“-Tags mit Hilfe der Variablen „soup“ herausfinden.
alldata = soup.find_all("tbody")

Wie du sehen kannst, haben die ersten beiden „tbody“ 8 „tr“ Tags und jedes „tr“ Tag hat zwei „td“ Tags.
try:
table1 = alldata.find_all("tr")
except:
table1=Nonetry:
table2 = alldata.find_all("tr")
except:
table2 = None
Jetzt hat jedes „tr“-Tag zwei „td“-Tags. Der erste „td“-Tag besteht aus dem Namen der Eigenschaft und der zweite aus dem Wert dieser Eigenschaft. Es ist so etwas wie ein Schlüssel-Wert-Paar.

An dieser Stelle werden wir eine Liste und ein Wörterbuch deklarieren, bevor wir eine for-Schleife starten.
l={}
u=list()
Um den Code einfach zu gestalten, werde ich zwei verschiedene „for“-Schleifen für jede Tabelle ausführen. Zuerst für „table1“
for i in range(0,len(table1)):
try:
table1_td = table1.find_all("td")
except:
table1_td = None l.text] = table1_td.text u.append(l)
l={}
Wir haben nun alle td-Tags in einer Variablen „table1_td“ gespeichert. Und dann speichern wir den Wert des ersten & zweiten td-Tags in einem „Wörterbuch“. Dann schieben wir das Wörterbuch in eine Liste. Da wir keine doppelten Daten speichern wollen, machen wir das Wörterbuch am Ende leer. Ähnliche Schritte werden für „table2“ durchgeführt.
for i in range(0,len(table2)):
try:
table2_td = table2.find_all("td")
except:
table2_td = None l.text] = table2_td.text u.append(l)
l={}
Wenn Sie dann am Ende die Liste „u“ ausgeben, erhalten Sie eine JSON-Antwort.
{
"Yahoo finance":
}
Ist das nicht erstaunlich. Wir haben es geschafft, Yahoo Finance in nur 5 Minuten zu scrapen. Wir haben ein Array von Python Object, das die Finanzdaten des Unternehmens Amazon enthält. Auf diese Weise können wir die Daten von jeder beliebigen Website scrapen.
Abschluss
In diesem Artikel haben wir verstanden, wie wir Daten mit dem Data Scraping Tool & BeautifulSoup unabhängig von der Art der Website scrapen können.
Fühlen Sie sich frei, zu kommentieren und mich etwas zu fragen. Sie können mir auf Twitter und Medium folgen. Danke fürs Lesen und bitte drückt den Like-Button! 👍
Zusätzliche Ressourcen
Und das ist die Liste! An diesem Punkt solltest du dich wohl fühlen, wenn du deinen ersten Web Scraper schreibst, um Daten von einer beliebigen Website zu sammeln. Hier sind ein paar zusätzliche Ressourcen, die Sie während Ihrer Web-Scraping-Reise hilfreich finden könnten:
- Liste von Web-Scraping-Proxy-Diensten
- Liste von praktischen Web-Scraping-Tools
- BeautifulSoup-Dokumentation
- Scrapingdog-Dokumentation
- Leitfaden zum Web-Scraping