By Raymond Yuan, Software Engineering Intern
In diesem Tutorial lernen wir, wie man Deep Learning verwendet, um Bilder im Stil eines anderen Bildes zu komponieren (haben Sie sich jemals gewünscht, Sie könnten wie Picasso oder Van Gogh malen?). Dies wird als neuronale Stilübertragung bezeichnet! Diese Technik wird in Leon A. Gatys‘ Arbeit A Neural Algorithm of Artistic Style beschrieben, die sehr lesenswert ist und die Sie sich unbedingt ansehen sollten.
Neuronaler Stiltransfer ist eine Optimierungstechnik, die verwendet wird, um drei Bilder zu nehmen: ein Inhaltsbild, ein Referenzbild für den Stil (z. B. ein Kunstwerk eines berühmten Malers) und das Eingabebild, das Sie gestalten möchten – und sie so zu mischen, dass das Eingabebild so transformiert wird, dass es wie das Inhaltsbild aussieht, aber im Stil des Stilbildes „gemalt“ wird.
Nehmen wir zum Beispiel ein Bild dieser Schildkröte und Katsushika Hokusais Die große Welle vor Kanagawa:
Wie würde es nun aussehen, wenn Hokusai beschließen würde, die Textur oder den Stil seiner Wellen dem Bild der Schildkröte hinzuzufügen? Etwa so?
Ist das Magie oder nur Deep Learning? Glücklicherweise handelt es sich nicht um Magie: Die Stilübertragung ist eine unterhaltsame und interessante Technik, die die Fähigkeiten und internen Repräsentationen neuronaler Netze verdeutlicht.
Das Prinzip der neuronalen Stilübertragung besteht darin, zwei Abstandsfunktionen zu definieren, eine, die beschreibt, wie unterschiedlich der Inhalt zweier Bilder ist, Lcontent, und eine, die den Unterschied zwischen den beiden Bildern in Bezug auf ihren Stil beschreibt, Lstyle. Bei drei Bildern, einem gewünschten Stilbild, einem gewünschten Inhaltsbild und dem Eingabebild (initialisiert mit dem Inhaltsbild), versuchen wir dann, das Eingabebild so zu transformieren, dass der Inhaltsabstand zum Inhaltsbild und der Stilabstand zum Stilbild minimiert wird.
Zusammengefasst nehmen wir das Basis-Eingabebild, ein Inhaltsbild, das wir anpassen wollen, und das Stilbild, das wir anpassen wollen. Wir transformieren das Basis-Eingabebild, indem wir die Abstände zwischen Inhalt und Stil (Verluste) mit Backpropagation minimieren und ein Bild erzeugen, das mit dem Inhalt des Inhaltsbildes und dem Stil des Stilbildes übereinstimmt.
In diesem Prozess werden wir praktische Erfahrungen sammeln und Intuition für die folgenden Konzepte entwickeln:
- Eager Execution – verwenden Sie die imperative Programmierumgebung von TensorFlow, die Operationen sofort auswertet
- Lernen Sie mehr über Eager Execution
- Sehen Sie es in Aktion (viele der Tutorials sind im Colaboratory ausführbar)
- Verwenden der Functional API, um ein Modell zu definieren – wir werden eine Teilmenge unseres Modells erstellen, die uns Zugang zu den notwendigen Zwischenaktivierungen unter Verwendung der funktionalen API
- Nutzung von Feature-Maps eines vortrainierten Modells – Wir lernen, wie man vortrainierte Modelle und ihre Feature-Maps verwendet
- Erstellen von benutzerdefinierten Trainingsschleifen – Wir untersuchen, wie man einen Optimierer einrichtet, um einen gegebenen Verlust in Bezug auf Eingabeparameter zu minimieren
- Wir werden die allgemeinen Schritte zur Durchführung des Stiltransfers befolgen:
- Code:
- Implementierung
- Inhalts- und Stildarstellungen definieren
- Warum Zwischenschichten?
- Modell
- Definieren und erstellen Sie unsere Verlustfunktionen (Abstände von Inhalt und Stil)
- Stilverlust:
- Run Gradient Descent
- Berechnen Sie den Verlust und die Gradienten
- Anwenden und den Stiltransferprozess ausführen
- Was wir behandelt haben:
Wir werden die allgemeinen Schritte zur Durchführung des Stiltransfers befolgen:
- Daten visualisieren
- Grundlegende Vorverarbeitung/Vorbereitung unserer Daten
- Verlustfunktionen einrichten
- Modell erstellen
- Optimierung für Verlustfunktion
Zielgruppe: Dieser Beitrag richtet sich an fortgeschrittene Benutzer, die mit den grundlegenden Konzepten des maschinellen Lernens vertraut sind. Um das meiste aus diesem Beitrag herauszuholen, sollten Sie:
- Gatys Paper lesen – wir erklären es unterwegs, aber das Paper wird ein gründlicheres Verständnis der Aufgabe vermitteln
- Gradientenabstieg verstehen
Geschätzte Zeit: 60 min
Code:
Den vollständigen Code für diesen Artikel finden Sie unter diesem Link. Wenn Sie dieses Beispiel Schritt für Schritt durchgehen möchten, finden Sie das Colab hier.
Implementierung
Zunächst aktivieren wir die eifrige Ausführung. Die eifrige Ausführung ermöglicht es uns, diese Technik auf die klarste und lesbarste Weise durchzuarbeiten.

Inhalts- und Stildarstellungen definieren
Um sowohl die Inhalts- als auch die Stildarstellungen unseres Bildes zu erhalten, werden wir uns einige Zwischenebenen in unserem Modell ansehen. Zwischenebenen stellen Feature-Maps dar, die mit zunehmender Tiefe immer höher geordnet werden. In diesem Fall verwenden wir die Netzarchitektur VGG19, ein vortrainiertes Bildklassifizierungsnetz. Diese Zwischenschichten sind notwendig, um die Darstellung von Inhalt und Stil in unseren Bildern zu definieren. Für ein Eingabebild werden wir versuchen, die entsprechenden Stil- und Inhalts-Zieldarstellungen auf diesen Zwischenschichten zu finden.
Warum Zwischenschichten?
Sie fragen sich vielleicht, warum diese Zwischenausgänge in unserem vortrainierten Bildklassifizierungsnetz uns ermöglichen, Stil- und Inhaltsdarstellungen zu definieren. Auf einer hohen Ebene lässt sich dieses Phänomen dadurch erklären, dass ein Netz, das eine Bildklassifizierung durchführen soll (wofür unser Netz trainiert wurde), das Bild verstehen muss. Dazu muss es das Rohbild als Eingabepixel nehmen und eine interne Darstellung durch Transformationen aufbauen, die die Rohbildpixel in ein komplexes Verständnis der im Bild vorhandenen Merkmale verwandeln. Dies ist auch einer der Gründe, warum neuronale Faltungsnetzwerke gut verallgemeinern können: Sie sind in der Lage, die Invarianzen und definierenden Merkmale innerhalb von Klassen (z. B. Katzen vs. Hunde) zu erfassen, die unabhängig von Hintergrundrauschen und anderen Störungen sind. Zwischen der Eingabe des Rohbildes und der Ausgabe des Klassifizierungslabels dient das Modell also als komplexer Merkmalsextraktor; durch den Zugriff auf die Zwischenschichten können wir den Inhalt und den Stil der Eingabebilder beschreiben.
Speziell werden wir diese Zwischenschichten aus unserem Netzwerk herausziehen:
Modell
In diesem Fall laden wir VGG19 und geben unseren Eingabetensor in das Modell ein. Auf diese Weise können wir die Feature-Maps (und in der Folge die Inhalts- und Stilrepräsentationen) des Inhalts, des Stils und der generierten Bilder extrahieren.
Wir verwenden VGG19, wie in der Veröffentlichung vorgeschlagen. Da VGG19 ein relativ einfaches Modell ist (im Vergleich zu ResNet, Inception usw.), eignen sich die Feature-Maps besser für die Stilübertragung.
Um auf die Zwischenschichten zuzugreifen, die unseren Stil- und Inhalts-Feature-Maps entsprechen, erhalten wir die entsprechenden Ausgaben, indem wir die funktionale API von Keras verwenden, um unser Modell mit den gewünschten Ausgabeaktivierungen zu definieren.
Mit der funktionalen API müssen bei der Definition eines Modells lediglich die Eingabe und die Ausgabe definiert werden: model = Model(inputs, outputs).
Im obigen Codeschnipsel laden wir unser vortrainiertes Bildklassifizierungsnetzwerk. Dann nehmen wir die Schichten von Interesse, die wir zuvor definiert haben. Dann definieren wir ein Modell, indem wir die Eingaben des Modells auf ein Bild und die Ausgaben auf die Ausgaben der Stil- und Inhaltsschichten setzen. Mit anderen Worten, wir haben ein Modell erstellt, das ein Eingangsbild nimmt und die Zwischenschichten Inhalt und Stil ausgibt!
Definieren und erstellen Sie unsere Verlustfunktionen (Abstände von Inhalt und Stil)
Unsere Definition des Inhaltsverlusts ist eigentlich ganz einfach. Wir übergeben dem Netzwerk sowohl das gewünschte Inhaltsbild als auch unser Basis-Eingabebild. Dies gibt die Ausgaben der Zwischenschichten (aus den oben definierten Schichten) von unserem Modell zurück. Dann nehmen wir einfach den euklidischen Abstand zwischen den beiden Zwischendarstellungen dieser Bilder.
Formaler ausgedrückt ist der Inhaltsverlust eine Funktion, die den Abstand des Inhalts von unserem Eingabebild x und unserem Inhaltsbild p beschreibt. Sei Cₙₙ ein vortrainiertes tiefes neuronales Faltungsnetzwerk. Auch in diesem Fall verwenden wir VGG19. Sei X ein beliebiges Bild, dann sei Cₙₙ(x) das Netz, das von X gespeist wird. Fˡᵢⱼ(x)∈ Cₙₙ(x) und Pˡᵢⱼ(x) ∈ Cₙₙ(x) beschreiben die jeweilige intermediäre Merkmalsrepräsentation des Netzes mit den Eingängen x und p auf Schicht l . Dann beschreiben wir die inhaltliche Distanz (Verlust) formal als:
Wir führen Backpropagation in der üblichen Weise so durch, dass wir diesen inhaltlichen Verlust minimieren. Wir verändern also das Ausgangsbild so lange, bis es in einer bestimmten Schicht (definiert in content_layer) eine ähnliche Reaktion erzeugt wie das ursprüngliche Inhaltsbild.
Dies kann ganz einfach implementiert werden. Auch hier werden die Merkmalskarten auf einer Schicht L in einem Netz, das mit x, unserem Eingabebild, und p, unserem Inhaltsbild, gefüttert wird, als Eingabe genommen und die Inhaltsdistanz zurückgegeben.
Stilverlust:
Die Berechnung des Stilverlusts ist etwas komplizierter, folgt aber demselben Prinzip, wobei diesmal unser Netz mit dem Basis-Eingabebild und dem Stilbild gefüttert wird. Anstatt jedoch die rohen Zwischenergebnisse des Basis-Eingabebildes und des Stilbildes zu vergleichen, vergleichen wir stattdessen die Gram-Matrizen der beiden Ausgaben.
Mathematisch beschreiben wir den Stilverlust des Basis-Eingabebildes x und des Stilbildes a als den Abstand zwischen den Stildarstellungen (den Gram-Matrizen) dieser Bilder. Wir beschreiben die Stildarstellung eines Bildes als die Korrelation zwischen verschiedenen Filterantworten, die durch die Gram-Matrix Gˡ gegeben ist, wobei Gˡᵢⱼ das innere Produkt zwischen der vektorisierten Merkmalskarte i und j in Schicht l ist. Wir sehen, dass Gˡᵢⱼ, das über die Merkmalskarte für ein bestimmtes Bild generiert wird, die Korrelation zwischen den Merkmalskarten i und j darstellt.
Um einen Stil für unser Basis-Eingabebild zu generieren, führen wir einen Gradientenabstieg vom Inhaltsbild durch, um es in ein Bild zu transformieren, das der Stildarstellung des Originalbildes entspricht. Dies geschieht durch Minimierung des mittleren quadratischen Abstands zwischen der Merkmalskorrelationskarte des Stilbildes und des Eingabebildes. Der Beitrag jeder Schicht zum Gesamtstilverlust wird beschrieben durch
wobei Gˡᵢⱼ und Aˡᵢⱼ die jeweilige Stildarstellung in Schicht l von Eingangsbild x und Stilbild a sind. Nl beschreibt die Anzahl der Merkmalskarten, jede mit der Größe Ml=Höhe∗Breite. Der gesamte Stilverlust in jeder Schicht beträgt also
wobei wir den Beitrag der Verluste jeder Schicht mit einem Faktor wl gewichten. In unserem Fall gewichten wir jede Schicht gleich:
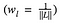
Dies wird einfach umgesetzt:
Run Gradient Descent
Wenn Sie mit Gradient Descent/Backpropagation nicht vertraut sind oder eine Auffrischung brauchen, sollten Sie sich diese Ressource unbedingt ansehen.
In diesem Fall verwenden wir den Adam-Optimierer, um unseren Verlust zu minimieren. Wir aktualisieren unser Ausgangsbild iterativ so, dass es unseren Verlust minimiert: Wir aktualisieren nicht die mit unserem Netzwerk verbundenen Gewichte, sondern trainieren unser Eingangsbild, um den Verlust zu minimieren. Dazu müssen wir wissen, wie wir unsere Verluste und Gradienten berechnen. Beachten Sie, dass der L-BFGS-Optimierer, der, wenn Sie mit diesem Algorithmus vertraut sind, empfohlen wird, in diesem Tutorium jedoch nicht verwendet wird, da eine der Hauptmotivationen für dieses Tutorium darin bestand, bewährte Verfahren mit eifriger Ausführung zu veranschaulichen. Durch die Verwendung von Adam können wir die Autograd/GradientTape-Funktionalität mit benutzerdefinierten Trainingsschleifen demonstrieren.
Berechnen Sie den Verlust und die Gradienten
Wir werden eine kleine Hilfsfunktion definieren, die unser Inhalts- und Stilbild lädt, sie durch unser Netzwerk weiterleitet, das dann die Inhalts- und Stilmerkmalrepräsentationen aus unserem Modell ausgibt.
Hier verwenden wir tf.GradientTape, um den Gradienten zu berechnen. Es erlaubt uns, die Vorteile der automatischen Differenzierung zu nutzen, die durch die Verfolgung von Operationen für die spätere Berechnung des Gradienten verfügbar ist. Es zeichnet die Operationen während des Vorwärtsdurchlaufs auf und ist dann in der Lage, den Gradienten unserer Verlustfunktion in Bezug auf unser Eingabebild für den Rückwärtsdurchlauf zu berechnen.
Dann ist die Berechnung der Gradienten einfach:
Anwenden und den Stiltransferprozess ausführen
Und um den Stiltransfer tatsächlich durchzuführen:
Und das ist es!
Lassen Sie es uns an unserem Bild der Schildkröte und Hokusais „Die große Welle vor Kanagawa“ ausprobieren:

Beobachten Sie den iterativen Prozess im Laufe der Zeit:

Hier sind einige andere coole Beispiele dafür, was neuronale Stilübertragung leisten kann. Check it out!
Testen Sie Ihre eigenen Bilder!
Was wir behandelt haben:
- Wir haben verschiedene Verlustfunktionen erstellt und Backpropagation verwendet, um unser Eingabebild zu transformieren, um diese Verluste zu minimieren.
- Zu diesem Zweck haben wir ein vortrainiertes Modell geladen und seine gelernten Merkmalskarten verwendet, um den Inhalt und die stilistische Darstellung unserer Bilder zu beschreiben.
- Unsere wichtigsten Verlustfunktionen berechneten in erster Linie den Abstand in Bezug auf diese verschiedenen Darstellungen.
- Wir implementierten dies mit einem benutzerdefinierten Modell und eifriger Ausführung.
- Wir haben unser benutzerdefiniertes Modell mit der funktionalen API erstellt.
- Die eifrige Ausführung ermöglicht es uns, dynamisch mit Tensoren zu arbeiten, indem wir einen natürlichen Python-Kontrollfluss verwenden.
- Wir haben Tensoren direkt manipuliert, was die Fehlersuche und die Arbeit mit Tensoren erleichtert.
Wir haben unser Bild iterativ aktualisiert, indem wir die Aktualisierungsregeln unseres Optimierers mit tf.gradient angewendet haben. Der Optimierer minimierte die gegebenen Verluste in Bezug auf unser Eingabebild.