Dans ce post, nous allons apprendre le web scraping avec python. En utilisant python, nous allons scrapper Yahoo Finance. C’est une grande source de données boursières. Nous allons coder un scraper pour cela. En utilisant ce scraper, vous serez en mesure d’extraire les données boursières de n’importe quelle entreprise de Yahoo Finance. Comme vous le savez, j’aime rendre les choses assez simples, pour cela, je vais également utiliser un scraper web qui augmentera votre efficacité de scrapping.
Pourquoi cet outil ? Cet outil nous aidera à gratter des sites web dynamiques en utilisant des millions de proxies rotatifs afin de ne pas être bloqué. Il fournit également une facilité de compensation. Il utilise le chrome sans en-tête pour gratter les sites web dynamiques.
Généralement, le grattage web est divisé en deux parties :
- La récupération des données en faisant une requête HTTP
- L’extraction des données importantes en analysant le DOM HTML
Librairies &Outils
- Beautiful Soup est une bibliothèque Python pour extraire les données des fichiers HTML et XML.
- Les requêtes vous permettent d’envoyer des requêtes HTTP très facilement.
- Outil de scraping web pour extraire le code HTML de l’URL cible.
Setup
Notre configuration est assez simple. Il suffit de créer un dossier et d’installer les demandes de Beautiful Soup &. Pour créer un dossier et installer les bibliothèques tapez les commandes données ci-dessous. Je suppose que vous avez déjà installé Python 3.x.
mkdir scraper
pip install beautifulsoup4
pip install requests
Maintenant, créez un fichier à l’intérieur de ce dossier par le nom que vous voulez. J’utilise scraping.py.
D’abord, vous devez vous inscrire à l’API scrapingdog. Cela vous fournira 1000 crédits GRATUITS. Ensuite, il suffit d’importer Beautiful Soup & demandes dans votre fichier. comme ceci.
from bs4 import BeautifulSoup
import requests
Ce que nous allons scraper
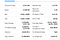
Voici la liste des champs que nous allons extraire :
- Clôture précédente
- Open
- Bid
- Ask
- Day’s Range
- 52 Week Range
- Volume
- Avg. Volume
- Capacité boursière
- Bêta
- Ratio PE
- EPS
- Taux de bénéfice
- Dividende à terme &Rendement
- Dividende Ex.Dividende & Date
- 1y target EST
Préparation de la nourriture
Maintenant, puisque nous avons tous les ingrédients pour préparer le scraper, nous devons faire une requête GET à l’URL cible pour obtenir les données HTML brutes. Si vous n’êtes pas familier avec l’outil de scraping, je vous conseille vivement de parcourir sa documentation. Maintenant, nous allons gratter Yahoo Finance pour les données financières en utilisant la bibliothèque requests comme indiqué ci-dessous.
r = requests.get("https://api.scrapingdog.com/scrape?api_key=<your-api-key>&url=https://finance.yahoo.com/quote/AMZN?p=AMZN&.tsrc=fin-srch").text
cela vous fournira un code HTML de cette URL cible.
Maintenant, vous devez utiliser BeautifulSoup pour analyser le HTML.
soup = BeautifulSoup(r,'html.parser')
Maintenant, sur la page entière, nous avons quatre balises « tbody ». Nous sommes intéressés par les deux premières car nous n’avons actuellement pas besoin des données disponibles à l’intérieur de la troisième &quatrième balise « tbody ».
D’abord, nous allons trouver toutes ces balises « tbody » en utilisant la variable « soupe ».
alldata = soup.find_all("tbody")

Comme vous pouvez le remarquer, les deux premiers « tbody » ont 8 balises « tr » et chaque balise « tr » a deux balises « td ».
try:
table1 = alldata.find_all("tr")
except:
table1=Nonetry:
table2 = alldata.find_all("tr")
except:
table2 = None
Maintenant, chaque balise « tr » a deux balises « td ». La première balise td est constituée du nom de la propriété et l’autre de la valeur de cette propriété. C’est quelque chose comme une paire clé-valeur.

À ce stade, nous allons déclarer une liste et un dictionnaire avant de commencer une boucle for.
l={}
u=list()
Pour rendre le code simple, je vais exécuter deux boucles « for » différentes pour chaque table. D’abord pour « table1 »
for i in range(0,len(table1)):
try:
table1_td = table1.find_all("td")
except:
table1_td = None l.text] = table1_td.text u.append(l)
l={}
Maintenant, ce que nous avons fait est que nous stockons toutes les balises td dans une variable « table1_td ». Et puis nous stockons la valeur de la première & deuxième balise td dans un « dictionnaire ». Ensuite, nous poussons le dictionnaire dans une liste. Comme nous ne voulons pas stocker des données en double, nous allons rendre le dictionnaire vide à la fin. Des étapes similaires seront suivies pour « table2 ».
for i in range(0,len(table2)):
try:
table2_td = table2.find_all("td")
except:
table2_td = None l.text] = table2_td.text u.append(l)
l={}
Ensuite, à la fin, lorsque vous imprimez la liste « u », vous obtenez une réponse JSON.
{
"Yahoo finance":
}
N’est-ce pas incroyable. Nous avons réussi à scraper Yahoo finance en seulement 5 minutes de configuration. Nous avons un tableau de python Object contenant les données financières de l’entreprise Amazon. De cette façon, nous pouvons scrapper les données de n’importe quel site web.
Conclusion
Dans cet article, nous avons compris comment nous pouvons scrapper des données en utilisant l’outil de scraping de données & BeautifulSoup quel que soit le type de site web.
N’hésitez pas à commenter et à me demander quoi que ce soit. Vous pouvez me suivre sur Twitter et Medium. Merci de lire et s’il vous plaît appuyez sur le bouton like ! 👍
Ressources supplémentaires
Et voilà la liste ! À ce stade, vous devriez vous sentir à l’aise pour écrire votre premier scraper web pour recueillir des données à partir de n’importe quel site web. Voici quelques ressources supplémentaires que vous pourrez trouver utiles au cours de votre voyage de scraping web :
- Liste de services proxy de scraping web
- Liste d’outils de scraping web pratiques
- Documentation BeautifulSoup
- Documentation Scrapingdog
- Guide du scraping web
.