par David Venturi
Il y a un an, j’ai abandonné l’un des meilleurs programmes d’informatique au Canada. J’ai commencé à créer mon propre programme de maîtrise en science des données en utilisant des ressources en ligne. Je me suis rendu compte que je pouvais apprendre tout ce dont j’avais besoin grâce à edX, Coursera et Udacity plutôt. Et je pouvais l’apprendre plus rapidement, plus efficacement et pour une fraction du coût.
J’ai presque terminé maintenant. J’ai suivi de nombreux cours liés à la science des données et audité des parties de beaucoup d’autres. Je connais les options qui existent et les compétences nécessaires aux apprenants qui se préparent à un rôle d’analyste ou de scientifique des données. Il y a quelques mois, j’ai commencé à créer un guide axé sur la révision qui recommande les meilleurs cours pour chaque sujet de la science des données.
Pour le premier guide de la série, j’ai recommandé quelques cours de codage pour le scientifique de données débutant. Ensuite, c’était des cours de statistiques et de probabilités.
- Maintenant sur les introductions à la science des données.
- Comment nous avons choisi les cours à considérer
- Comment nous avons évalué les cours
- Quel est le processus de la science des données?
- Expérience de base en codage, statistiques et probabilités requise
- Notre choix pour le meilleur cours d’introduction à la science des données est…
- Une excellente introduction axée sur Python
- Une offre impressionnante sans données d’examen
- La concurrence
- Wrapping it Up
Maintenant sur les introductions à la science des données.
(Ne vous inquiétez pas si vous n’êtes pas sûr de ce que comporte un cours d’introduction à la science des données. Je vous l’expliquerai sous peu.)
Pour ce guide, j’ai passé plus de 10 heures à essayer d’identifier tous les cours d’introduction à la science des données en ligne offerts en janvier 2017, à extraire des éléments d’information clés de leurs syllabus et de leurs critiques, et à compiler leurs évaluations. Pour cette tâche, je me suis tourné vers nul autre que la communauté open source Class Central et sa base de données de milliers d’évaluations et de critiques de cours.
Depuis 2011, le fondateur de Class Central, Dhawal Shah, a gardé un œil plus attentif sur les cours en ligne que sans doute n’importe qui d’autre dans le monde. Dhawal m’a personnellement aidé à assembler cette liste de ressources.
Comment nous avons choisi les cours à considérer
Chaque cours doit répondre à trois critères :
- Il doit enseigner le processus de science des données. Nous en reparlerons bientôt.
- Il doit être à la demande ou proposé tous les quelques mois.
- Il doit s’agir d’un cours interactif en ligne, donc pas de livres ou de tutoriels à lire uniquement. Bien que ce soient des moyens viables d’apprendre, ce guide se concentre sur les cours.
Nous pensons avoir couvert tous les cours notables qui répondent aux critères ci-dessus. Puisqu’il y a apparemment des centaines de cours sur Udemy, nous avons choisi de ne considérer que les plus examinés et les mieux notés. Il y a toujours une chance que nous ayons manqué quelque chose, cependant. Alors n’hésitez pas à nous faire savoir dans la section des commentaires si nous avons laissé un bon cours de côté.
Comment nous avons évalué les cours
Nous avons compilé la note moyenne et le nombre de critiques de Class Central et d’autres sites d’évaluation pour calculer une note moyenne pondérée pour chaque cours. Nous avons lu les critiques textuelles et utilisé ces commentaires pour compléter les notes numériques.
Nous avons fait des appels de jugement subjectifs sur les syllabus en fonction de deux facteurs :
1. La couverture du processus de la science des données. Le cours survole-t-il ou saute-t-il certains sujets ? Couvre-t-il certains sujets de manière trop détaillée ? Voir la section suivante pour savoir ce que ce processus implique.
2. Utilisation des outils courants de la science des données. Le cours est-il enseigné en utilisant des langages de programmation populaires comme Python et/ou R ? Ceux-ci ne sont pas nécessaires, mais utiles dans la plupart des cas, donc une légère préférence est accordée à ces cours.

Quel est le processus de la science des données?
Qu’est-ce que la science des données ? Que fait un scientifique des données ? Ce sont les types de questions fondamentales auxquelles un cours d’introduction à la science des données devrait répondre. L’infographie suivante des professeurs de Harvard Joe Blitzstein et Hanspeter Pfister décrit un processus typique de science des données, ce qui nous aidera à répondre à ces questions.
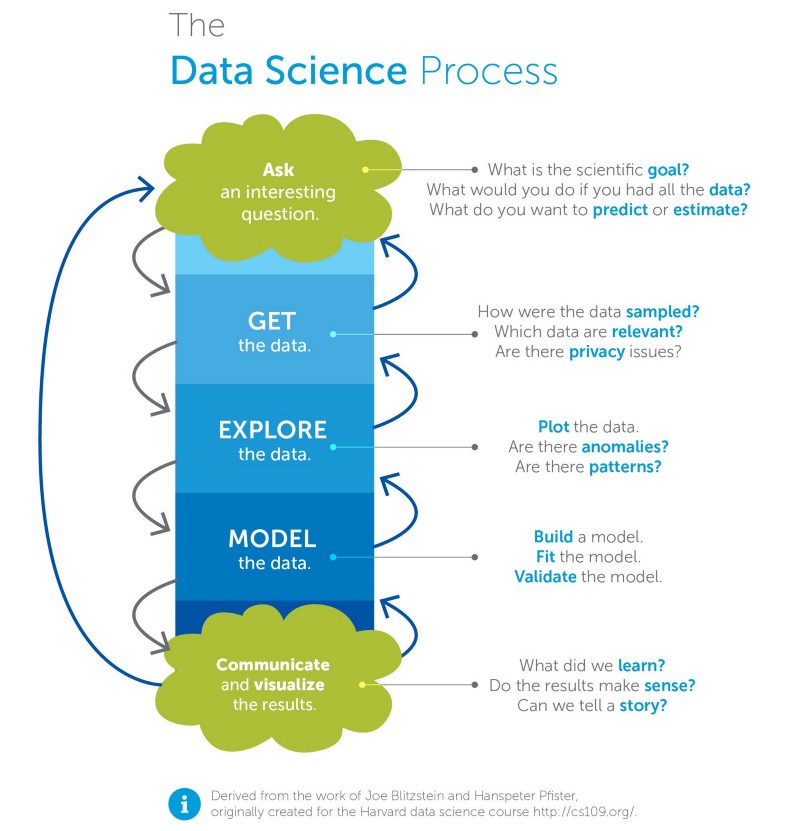
Notre objectif avec ce cours d’introduction à la science des données est de nous familiariser avec le processus de science des données. Nous ne voulons pas une couverture trop approfondie des aspects spécifiques du processus, d’où la partie « intro à » du titre.
Pour chaque aspect, le cours idéal explique les concepts clés dans le cadre du processus, présente les outils courants et fournit quelques exemples (de préférence pratiques).
Nous recherchons uniquement une introduction. Ce guide n’inclura donc pas les spécialisations complètes ou les programmes comme la spécialisation en science des données de l’Université Johns Hopkins sur Coursera ou le nanodiplôme d’analyste de données d’Udacity. Ces compilations de cours échappent à l’objectif de cette série : trouver les meilleurs cours individuels pour chaque sujet afin de constituer une formation en science des données. Les trois derniers guides de cette série d’articles couvriront en détail chaque aspect du processus de science des données.
Expérience de base en codage, statistiques et probabilités requise
Plusieurs cours énumérés ci-dessous exigent une expérience de base en programmation, statistiques et probabilités. Cette exigence est compréhensible étant donné que le nouveau contenu est raisonnablement avancé, et que ces sujets ont souvent plusieurs cours qui leur sont consacrés.
Cette expérience peut être acquise grâce à nos recommandations dans les deux premiers articles (programmation, statistiques) de ce guide de carrière en science des données.
Notre choix pour le meilleur cours d’introduction à la science des données est…
- Data Science A-Z™ : Real-Life Data Science Exercises Included (Kirill Eremenko/Udemy)
Le cours Data Science A-Z™ de Kirill Eremenko sur Udemy est le grand gagnant en termes d’ampleur et de profondeur de la couverture du processus de science des données parmi les 20+ cours qualifiés. Il a une note moyenne pondérée de 4,5 étoiles sur 3 071 commentaires, ce qui le place parmi les cours les mieux notés et les plus examinés de ceux considérés.
Il décrit le processus complet et fournit des exemples concrets. Avec 21 heures de contenu, il est d’une bonne longueur. Les évaluateurs aiment la livraison de l’instructeur et l’organisation du contenu. Le prix varie en fonction des remises Udemy, qui sont fréquentes, de sorte que vous pouvez acheter l’accès pour aussi peu que 10 $.
Bien qu’il ne coche pas notre case « utilisation des outils de science des données courants », les choix d’outils non Python/R (gretl, Tableau, Excel) sont utilisés efficacement dans le contexte. Eremenko mentionne ce qui suit lorsqu’il explique le choix de gretl (gretl est un progiciel statistique), bien que cela s’applique à tous les outils qu’il utilise (c’est moi qui souligne) :
Dans gretl, nous serons en mesure de faire la même modélisation tout comme dans R et Python, mais nous n’aurons pas à coder. C’est là tout l’enjeu. Certains d’entre vous connaissent peut-être déjà très bien R, mais d’autres ne le connaissent peut-être pas du tout. Mon objectif est de vous montrer comment construire un modèle robuste et de vous donner un cadre que vous pouvez appliquer dans n’importe quel outil que vous choisissez. gretl nous aidera à éviter de nous enliser dans notre codage.
Un critique éminent a noté ce qui suit:
Kirill est le meilleur professeur que j’ai trouvé en ligne. Il utilise des exemples de la vie réelle et explique les problèmes communs afin que vous obteniez une compréhension plus profonde du travail de cours. Il fournit également beaucoup d’informations sur ce que signifie être un scientifique des données, du travail avec des données insuffisantes jusqu’à la présentation de votre travail à la direction de classe C. Je recommande vivement ce cours pour les étudiants débutants aux analystes de données intermédiaires!

Une excellente introduction axée sur Python
- Intro à l’analyse de données (Udacity)
L’Intro à l’analyse de données d’Udacity est une offre relativement nouvelle qui fait partie du populaire Nanodegré d’analyste de données d’Udacity. Il couvre le processus de science des données de manière claire et cohérente en utilisant Python, bien qu’il manque un peu dans l’aspect modélisation. La durée estimée est de 36 heures (six heures par semaine sur six semaines), mais elle est plus courte selon mon expérience. Il a une note moyenne pondérée de 5 étoiles sur deux critiques. Il est gratuit.
Les vidéos sont bien produites et l’instructeur (Caroline Buckey) est clair et sympathique. De nombreux quiz de programmation mettent en application les concepts appris dans les vidéos. Les étudiants quitteront le cours confiants dans leurs compétences nouvelles et/ou améliorées de NumPy et Pandas (ce sont des bibliothèques Python populaires). Le projet final – qui est noté et examiné dans le nanodiplôme mais pas dans le cours individuel gratuit – peut être un ajout intéressant à un portefeuille.

Une offre impressionnante sans données d’examen
- Data Science Fundamentals (Big Data University)
Data Science Fundamentals est une série de quatre cours fournis par la Big Data University d’IBM. Elle comprend des cours intitulés Data Science 101, Data Science Methodology, Data Science Hands-on with Open Source Tools, et R 101.
Elle couvre l’ensemble du processus de science des données et présente Python, R et plusieurs autres outils open-source. Les cours ont une énorme valeur de production. On estime à 13-18 heures d’effort, en fonction de si vous prenez le cours « R 101 » à la fin, qui n’est pas nécessaire pour le but de ce guide. Malheureusement, il n’a pas de données d’examen sur les principaux sites d’examen que nous avons utilisés pour cette analyse, donc nous ne pouvons pas encore le recommander par rapport aux deux options ci-dessus. Il est gratuit.

La concurrence
Notre choix n°1 avait une note moyenne pondérée de 4,5 sur 5 étoiles sur 3 068 critiques. Regardons les autres alternatives, classées par note décroissante. Vous trouverez ci-dessous plusieurs cours axés sur R, si vous souhaitez vous initier à ce langage.
- Python for Data Science and Machine Learning Bootcamp (Jose Portilla/Udemy) : Couverture complète des processus avec un accent lourd sur les outils (Python). Moins axé sur les processus et plus une introduction très détaillée à Python. Un cours extraordinaire, mais qui n’est pas idéal pour la portée de ce guide. Comme le cours R de Jose ci-dessous, il peut servir à la fois d’introduction à Python/R et d’introduction à la science des données. 21,5 heures de contenu. Il a une note moyenne pondérée de 4,7 étoiles sur 1 644 commentaires. Le coût varie en fonction des remises Udemy, qui sont fréquentes.
- Data Science and Machine Learning Bootcamp with R (Jose Portilla/Udemy) : Couverture complète du processus avec un accent lourd sur les outils (R). Moins axé sur les processus et plus une introduction très détaillée à R. Cours incroyable, mais pas idéal pour la portée de ce guide. Comme le cours Python de Jose ci-dessus, il peut servir à la fois d’introduction à Python/R et d’introduction à la science des données. 18 heures de contenu. Il a une note moyenne pondérée de 4,6 étoiles sur 847 commentaires. Le coût varie en fonction des remises Udemy, qui sont fréquentes.

- Science des données et apprentissage automatique avec Python – Hands On ! (Frank Kane/Udemy) : Couverture partielle du processus. Se concentre sur les statistiques et l’apprentissage automatique. Longueur décente (neuf heures de contenu). Utilise Python. Il a une note moyenne pondérée de 4,5 étoiles sur 3 104 commentaires. Le coût varie en fonction des remises Udemy, qui sont fréquentes.
- Introduction à la science des données (Data Hawk Tech/Udemy) : Couverture complète du processus, bien que la profondeur de la couverture soit limitée. Assez court (trois heures de contenu). Couvre brièvement R et Python. Il a une note moyenne pondérée de 4,4 étoiles sur 62 commentaires. Le coût varie en fonction des remises Udemy, qui sont fréquentes.
- Applied Data Science : An Introduction (Université de Syracuse/Open Education by Blackboard) : Couverture complète du processus, bien que pas uniformément répartie. Se concentre fortement sur les statistiques de base et R. Trop appliqué et pas assez axé sur les processus pour le but de ce guide. L’expérience du cours en ligne semble décousue. Il a une note moyenne pondérée de 4,33 étoiles sur 6 critiques. Gratuit.
- Introduction à la science des données (Nina Zumel & John Mount/Udemy) : Couverture partielle des processus uniquement, bien que bonne profondeur dans les aspects de préparation et de modélisation des données. Longueur acceptable (six heures de contenu). Utilise R. Il a une note moyenne pondérée de 4,3 étoiles sur 101 commentaires. Le coût varie en fonction des remises Udemy, qui sont fréquentes.
- Applied Data Science with Python (V2 Maestros/Udemy) : Couverture complète du processus avec une bonne profondeur de couverture pour chaque aspect du processus. Longueur décente (8,5 heures de contenu). Utilise Python. Il a une note moyenne pondérée de 4,3 étoiles sur 92 commentaires. Le coût varie en fonction des remises Udemy, qui sont fréquentes.

- Vous voulez être un scientifique de données ? (V2 Maestros/Udemy) : Couverture complète des processus, bien que la profondeur de la couverture soit limitée. Assez court (3 heures de contenu). Couverture limitée des outils. Il a une note moyenne pondérée de 4,3 étoiles sur 790 commentaires. Le coût varie en fonction des remises Udemy, qui sont fréquentes.
- Data to Insight : an Introduction to Data Analysis (University of Auckland/FutureLearn) : L’étendue de la couverture n’est pas claire. Prétend se concentrer sur l’exploration, la découverte et la visualisation des données. Non proposé à la demande. 24 heures de contenu (trois heures par semaine sur huit semaines). Il a une note moyenne pondérée de 4 étoiles sur 2 critiques. Gratuit avec certificat payant disponible.
- Orientation en science des données (Microsoft/edX) : Couverture partielle des processus (manque l’aspect modélisation). Utilise Excel, ce qui est logique étant donné qu’il s’agit d’un cours de la marque Microsoft. 12-24 heures de contenu (deux-quatre heures par semaine sur six semaines). Il a une note moyenne pondérée de 3,95 étoiles sur 40 commentaires. Gratuit avec certificat vérifié disponible pour 25 $.
- Data Science Essentials (Microsoft/edX) : Couverture complète du processus avec une bonne profondeur de couverture pour chaque aspect. Couvre R, Python et Azure ML (une plateforme d’apprentissage automatique de Microsoft). Plusieurs critiques 1 étoile citant le choix de l’outil (Azure ML) et la prestation médiocre de l’instructeur. 18-24 heures de contenu (trois-quatre heures par semaine sur six semaines). La moyenne pondérée de 67 avis est de 3,81 étoiles. Gratuit avec certificat vérifié disponible pour 49 $.

- Applied Data Science with R (V2 Maestros/Udemy) : Le compagnon R du cours Python de V2 Maestros ci-dessus. Couverture complète du processus avec une bonne profondeur de couverture pour chaque aspect du processus. Longueur décente (11 heures de contenu). Utilise R. Il a une note moyenne pondérée de 3,8 étoiles sur 212 commentaires. Le coût varie en fonction des remises Udemy, qui sont fréquentes.
- Intro to Data Science (Udacity) : Couverture partielle des processus, bien que bonne profondeur pour les sujets couverts. Manque l’aspect exploration, bien que Udacity ait un excellent cours complet sur l’analyse exploratoire des données (EDA). Prétend être d’une durée de 48 heures (six heures par semaine sur huit semaines), mais est plus court dans mon expérience. Certaines critiques pensent que la mise en place du contenu avancé est insuffisante. Semble désorganisé. Utilise Python. Il a un niveau de 3.Note moyenne pondérée de 61 étoiles sur 18 avis. Gratuit.
- Introduction à la science des données en Python (Université du Michigan/Coursera) : Couverture partielle des processus. Pas de modélisation et de vizualisation, bien que les cours #2 et #3 de la spécialisation Applied Data Science with Python couvrent ces aspects. Prendre les trois cours serait trop approfondi pour l’objectif de ces guides. Utilise Python. D’une durée de quatre semaines. Il a une note moyenne pondérée de 3,6 étoiles sur 15 critiques. Options gratuites et payantes disponibles.

- Prise de décision basée sur les données (PwC/Coursera) : Couverture partielle (manque de modélisation) avec une orientation commerciale. Présente de nombreux outils, notamment R, Python, Excel, SAS et Tableau. Durée de quatre semaines. Il a une note moyenne pondérée de 3,5 étoiles sur 2 avis. Des options gratuites et payantes sont disponibles.
- A Crash Course in Data Science (Johns Hopkins University/Coursera) : Un aperçu extrêmement bref du processus complet. Trop bref pour l’objectif de cette série. D’une durée de deux heures. Il a une note moyenne pondérée de 3,4 étoiles sur 19 critiques. Options gratuites et payantes disponibles.
- The Data Scientist’s Toolbox (Johns Hopkins University/Coursera) : Un aperçu extrêmement bref du processus complet. Plus un cours de mise en place pour la spécialisation en science des données de l’Université Johns Hopkins. Il est censé contenir de 4 à 16 heures de contenu (une heure par semaine sur quatre semaines), mais un lecteur a noté qu’il pouvait être suivi en deux heures. Il a une note moyenne pondérée de 3,22 étoiles sur 182 critiques. Des options gratuites et payantes sont disponibles.
- Gestion et visualisation des données (Wesleyan University/Coursera) : Couverture partielle du processus (manque de modélisation). Durée de quatre semaines. Bonne valeur de production. Utilise Python et SAS. Il a une note moyenne pondérée de 2,67 étoiles sur 6 critiques. Options gratuites et payantes disponibles.
Les cours suivants n’avaient pas de critiques en janvier 2017.
- CS109 Data Science (Université de Harvard) : Couverture complète du processus en grande profondeur (probablement trop en profondeur pour le but de cette série). Un cours complet de 12 semaines pour les étudiants de premier cycle. La navigation dans le cours est difficile car le cours n’est pas conçu pour une consommation en ligne. Les conférences de Harvard sont filmées. L’infographie ci-dessus sur le processus de science des données provient de ce cours. Utilise Python. Pas de données d’examen. Gratuit.
- Introduction à l’analyse des données pour les entreprises (Université du Colorado Boulder/Coursera) : Couverture partielle des processus (manque les aspects de modélisation et de visualisation) avec un accent sur les affaires. Le processus de science des données est déguisé en « chaîne de valeur information-action » dans leurs cours. Durée de quatre semaines. Décrit plusieurs outils, mais ne couvre que SQL de manière approfondie. Pas de données d’examen. Options gratuites et payantes disponibles.
- Introduction à la science des données (Lynda) : Couverture complète du processus, bien que la profondeur de la couverture soit limitée. Assez court (trois heures de contenu). Présente à la fois R et Python. Pas de données d’examen. Le coût dépend de l’abonnement à Lynda.
Wrapping it Up
C’est le troisième article d’une série de six articles qui couvre les meilleurs cours en ligne pour vous lancer dans le domaine de la science des données. Nous avons abordé la programmation dans le premier article et les statistiques et les probabilités dans le deuxième article. Le reste de la série couvrira d’autres compétences fondamentales de la science des données : la visualisation des données et l’apprentissage automatique.
Si vous voulez apprendre la science des données, commencez par l’un de ces cours de programmation
Si vous voulez apprendre la science des données, prenez quelques-uns de ces cours de statistiques
Le dernier morceau sera un résumé de ces articles, plus les meilleurs cours en ligne pour d’autres sujets clés tels que le wrangling des données, les bases de données et même le génie logiciel.
Si vous cherchez une liste complète des cours en ligne en science des données, vous pouvez les trouver sur la page du sujet Science des données et Big Data de Class Central.
Si vous avez aimé lire ceci, consultez d’autres articles de Class Central :
Voici 250 cours de l’Ivy League que vous pouvez suivre en ligne dès maintenant et gratuitement
250 MOOC de Brown, Columbia, Cornell, Dartmouth, Harvard, Penn, Princeton et Yale.
Les 50 meilleurs cours universitaires en ligne gratuits selon les données
Lorsque j’ai lancé Class Central en novembre 2011, il y avait environ 18 cours en ligne gratuits, et presque tous…
Si vous avez des suggestions de cours que j’ai manqués, faites-le moi savoir dans les réponses !
Si vous avez trouvé cela utile, cliquez sur le ? pour que plus de personnes le voient ici sur Medium.
Ceci est une version condensée de mon article original publié sur Class Central, où j’ai inclus d’autres descriptions de cours, des syllabi et de multiples critiques.