Por Raymond Yuan, Becario de Ingeniería de Software
En este tutorial, aprenderemos a utilizar el aprendizaje profundo para componer imágenes al estilo de otra imagen (¿alguna vez has deseado poder pintar como Picasso o Van Gogh?). Esto se conoce como transferencia de estilo neural. Se trata de una técnica descrita en el artículo de Leon A. Gatys, A Neural Algorithm of Artistic Style (Un algoritmo neuronal de estilo artístico), que es una gran lectura y que deberías consultar.
La transferencia neuronal de estilo es una técnica de optimización que se utiliza para tomar tres imágenes, una imagen de contenido, una imagen de referencia de estilo (como una obra de arte de un pintor famoso) y la imagen de entrada a la que se quiere dar estilo, y mezclarlas de manera que la imagen de entrada se transforme para parecerse a la imagen de contenido, pero «pintada» con el estilo de la imagen de estilo.
Por ejemplo, tomemos una imagen de esta tortuga y La gran ola de Kanagawa de Katsushika Hokusai:
¿Ahora cómo se vería si Hokusai decidiera añadir la textura o el estilo de sus olas a la imagen de la tortuga? Algo así?
¿Es esto magia o simplemente aprendizaje profundo? Afortunadamente, no se trata de magia: la transferencia de estilo es una técnica divertida e interesante que muestra las capacidades y las representaciones internas de las redes neuronales.
El principio de la transferencia de estilo neuronal es definir dos funciones de distancia, una que describe lo diferente que es el contenido de dos imágenes, Lcontent, y otra que describe la diferencia entre las dos imágenes en términos de su estilo, Lstyle. Entonces, dadas tres imágenes, una imagen de estilo deseada, una imagen de contenido deseada, y la imagen de entrada (inicializada con la imagen de contenido), tratamos de transformar la imagen de entrada para minimizar la distancia de contenido con la imagen de contenido y su distancia de estilo con la imagen de estilo.
En resumen, tomaremos la imagen de entrada base, una imagen de contenido que queremos igualar, y la imagen de estilo que queremos igualar. Transformaremos la imagen base de entrada minimizando las distancias (pérdidas) de contenido y estilo con backpropagation, creando una imagen que coincida con el contenido de la imagen de contenido y el estilo de la imagen de estilo.
En el proceso, construiremos experiencia práctica y desarrollaremos la intuición en torno a los siguientes conceptos:
- Ejecución ansiosa – utilizaremos el entorno de programación imperativa de TensorFlow que evalúa las operaciones inmediatamente
- Aprenderemos más sobre la ejecución ansiosa
- Verlo en acción (muchos de los tutoriales son ejecutables en Colaboratory)
- Utilizar la API Funcional para definir un modelo – construiremos un subconjunto de nuestro modelo que nos dará acceso a las necesarias activaciones intermedias utilizando la API Funcional
- Aprovechamiento de los mapas de características de un modelo preentrenado – Aprenderemos a utilizar los modelos preentrenados y sus mapas de características
- Crear bucles de entrenamiento personalizados – examinaremos cómo configurar un optimizador para minimizar una pérdida determinada con respecto a los parámetros de entrada
- Seguiremos los pasos generales para realizar la transferencia de estilos:
- Código:
- Implementación
- Definir las representaciones de contenido y estilo
- ¿Por qué capas intermedias?
- Modelo
- Definimos y creamos nuestras funciones de pérdida (distancias de contenido y estilo)
- Pérdida de estilo:
- Ejecutar el descenso de gradiente
- Calcular la pérdida y los gradientes
- Aplicar y ejecutar el proceso de transferencia de estilo
- Lo que cubrimos:
Seguiremos los pasos generales para realizar la transferencia de estilos:
- Visualizar los datos
- Preprocesamiento básico/preparar nuestros datos
- Configurar las funciones de pérdida
- Crear el modelo
- Optimizar para la función de pérdida
Audiencia: Este post está orientado a usuarios intermedios que se sientan cómodos con los conceptos básicos del aprendizaje automático. Para obtener el máximo provecho de este post, usted debe:
- Leer el documento de Gatys – vamos a explicar a lo largo del camino, pero el documento proporcionará una comprensión más profunda de la tarea
- Entender el descenso de gradiente
Tiempo estimado: 60 min
Código:
Puedes encontrar el código completo de este artículo en este enlace. Si quieres recorrer este ejemplo, puedes encontrar el colab aquí.
Implementación
Comenzaremos habilitando la ejecución ansiosa. La ejecución ansiosa nos permite trabajar con esta técnica de la forma más clara y legible.

Definir las representaciones de contenido y estilo
Para obtener tanto las representaciones de contenido como las de estilo de nuestra imagen, nos fijaremos en algunas capas intermedias dentro de nuestro modelo. Las capas intermedias representan mapas de características que se vuelven cada vez más ordenadas a medida que se profundiza. En este caso, estamos utilizando la arquitectura de red VGG19, una red de clasificación de imágenes preentrenada. Estas capas intermedias son necesarias para definir la representación del contenido y el estilo de nuestras imágenes. Para una imagen de entrada, intentaremos hacer coincidir las correspondientes representaciones de estilo y contenido objetivo en estas capas intermedias.
¿Por qué capas intermedias?
Tal vez te preguntes por qué estas salidas intermedias dentro de nuestra red de clasificación de imágenes preentrenada nos permiten definir representaciones de estilo y contenido. A un alto nivel, este fenómeno puede explicarse por el hecho de que para que una red realice la clasificación de imágenes (para lo que nuestra red ha sido entrenada), debe entender la imagen. Esto implica tomar la imagen en bruto como píxeles de entrada y construir una representación interna mediante transformaciones que conviertan los píxeles de la imagen en bruto en una comprensión compleja de las características presentes en la imagen. En parte, ésta es la razón por la que las redes neuronales convolucionales son capaces de generalizar bien: son capaces de captar las invariantes y las características definitorias dentro de las clases (por ejemplo, gatos frente a perros) que son agnósticas al ruido de fondo y otras molestias. Así, en algún lugar entre la entrada de la imagen en bruto y la salida de la etiqueta de clasificación, el modelo sirve como un complejo extractor de características; por lo tanto, accediendo a las capas intermedias, somos capaces de describir el contenido y el estilo de las imágenes de entrada.
Específicamente sacaremos estas capas intermedias de nuestra red:
Modelo
En este caso, cargamos VGG19, y alimentamos nuestro tensor de entrada al modelo. Esto nos permitirá extraer los mapas de características (y posteriormente las representaciones de contenido y estilo) del contenido, el estilo y las imágenes generadas.
Utilizamos VGG19, como se sugiere en el artículo. Además, dado que VGG19 es un modelo relativamente simple (comparado con ResNet, Inception, etc) los mapas de características realmente funcionan mejor para la transferencia de estilo.
Para acceder a las capas intermedias correspondientes a nuestros mapas de características de estilo y contenido, obtenemos las salidas correspondientes utilizando la API Funcional de Keras para definir nuestro modelo con las activaciones de salida deseadas.
Con la API Funcional, definir un modelo simplemente implica definir la entrada y la salida: model = Model(inputs, outputs).
En el fragmento de código anterior, cargaremos nuestra red de clasificación de imágenes preentrenada. Luego tomamos las capas de interés como definimos anteriormente. Luego definimos un Modelo estableciendo las entradas del modelo a una imagen y las salidas a las salidas de las capas de estilo y contenido. En otras palabras, ¡creamos un modelo que tomará una imagen de entrada y dará como salida las capas intermedias de contenido y estilo!
Definimos y creamos nuestras funciones de pérdida (distancias de contenido y estilo)
Nuestra definición de pérdida de contenido es en realidad bastante simple. Pasaremos a la red tanto la imagen de contenido deseada como nuestra imagen de entrada base. Esto devolverá las salidas de las capas intermedias (de las capas definidas anteriormente) de nuestro modelo. Entonces simplemente tomamos la distancia euclidiana entre las dos representaciones intermedias de esas imágenes.
Más formalmente, la pérdida de contenido es una función que describe la distancia de contenido de nuestra imagen de entrada x y nuestra imagen de contenido, p . Sea Cₙₙ una red neuronal convolucional profunda preentrenada. De nuevo, en este caso utilizamos VGG19. Sea X una imagen cualquiera, entonces Cₙₙ(x) es la red alimentada por X. Dejemos que Fˡᵢⱼ(x)∈ Cₙₙ(x)y Pˡᵢⱼ(x) ∈ Cₙₙ(x) describan la respectiva representación de características intermedias de la red con entradas x y p en la capa l . Entonces describimos la distancia de contenido (pérdida) formalmente como:
Realizamos la retropropagación de la forma habitual de tal manera que minimizamos esta pérdida de contenido. Así, cambiamos la imagen inicial hasta que genere una respuesta similar en una determinada capa (definida en content_layer) a la imagen de contenido original.
Esto se puede implementar de forma bastante sencilla. De nuevo tomará como entrada los mapas de características en una capa L de una red alimentada por x, nuestra imagen de entrada, y p, nuestra imagen de contenido, y devolverá la distancia de contenido.
Pérdida de estilo:
Calcular la pérdida de estilo es un poco más complicado, pero sigue el mismo principio, esta vez alimentando nuestra red con la imagen de entrada base y la imagen de estilo. Sin embargo, en lugar de comparar las salidas intermedias brutas de la imagen de entrada base y la imagen de estilo, comparamos las matrices Gram de las dos salidas.
Matemáticamente, describimos la pérdida de estilo de la imagen de entrada base, x, y la imagen de estilo, a, como la distancia entre la representación de estilo (las matrices Gram) de estas imágenes. Describimos la representación de estilo de una imagen como la correlación entre diferentes respuestas de filtro dadas por la matriz Gram Gˡ, donde Gˡᵢⱼ es el producto interno entre el mapa de características vectorizado i y j en la capa l. Podemos ver que Gˡᵢⱼ generado sobre el mapa de características para una imagen dada representa la correlación entre los mapas de características i y j.
Para generar un estilo para nuestra imagen de entrada base, realizamos el descenso de gradiente de la imagen de contenido para transformarla en una imagen que coincida con la representación de estilo de la imagen original. Lo hacemos minimizando la distancia media al cuadrado entre el mapa de correlación de características de la imagen de estilo y la imagen de entrada. La contribución de cada capa a la pérdida total de estilo se describe mediante
donde Gˡᵢⱼ y Aˡᵢⱼ son las respectivas representaciones de estilo en la capa l de la imagen de entrada x y la imagen de estilo a. Nl describe el número de mapas de características, cada uno de ellos de tamaño Ml=height∗width. Así, la pérdida total de estilo en cada capa es
donde ponderamos la contribución de la pérdida de cada capa por algún factor wl. En nuestro caso, ponderamos cada capa por igual:
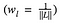
Esto se implementa de forma sencilla:
Ejecutar el descenso de gradiente
Si no estás familiarizado con el descenso de gradiente/ retropropagación o necesitas un repaso, definitivamente deberías consultar este recurso.
En este caso, utilizamos el optimizador Adam para minimizar nuestra pérdida. Actualizamos iterativamente nuestra imagen de salida de manera que minimice nuestra pérdida: no actualizamos los pesos asociados a nuestra red, sino que entrenamos nuestra imagen de entrada para minimizar la pérdida. Para ello, debemos saber cómo calculamos nuestras pérdidas y gradientes. Tenga en cuenta que el optimizador L-BFGS, que si usted está familiarizado con este algoritmo se recomienda, pero no se utiliza en este tutorial porque una motivación principal detrás de este tutorial fue para ilustrar las mejores prácticas con la ejecución ansiosa. Usando Adam, podemos demostrar la funcionalidad de la cinta autogradiente/gradiente con bucles de entrenamiento personalizados.
Calcular la pérdida y los gradientes
Definiremos una pequeña función de ayuda que cargará nuestro contenido e imagen de estilo, los alimentará a través de nuestra red, que luego dará salida a las representaciones de características de contenido y estilo de nuestro modelo.
Aquí usamos tf.GradientTape para calcular el gradiente. Nos permite aprovechar la diferenciación automática disponible al trazar las operaciones para calcular el gradiente posteriormente. Registra las operaciones durante el pase hacia adelante y luego es capaz de calcular el gradiente de nuestra función de pérdida con respecto a nuestra imagen de entrada para el pase hacia atrás.
Entonces calcular los gradientes es fácil:
Aplicar y ejecutar el proceso de transferencia de estilo
Y para realizar realmente la transferencia de estilo:
¡Y ya está!
Ejecutémoslo en nuestra imagen de la tortuga y en La gran ola de Kanagawa de Hokusai:

Observa el proceso iterativo a lo largo del tiempo:

Aquí tienes otros ejemplos geniales de lo que puede hacer la transferencia de estilo neuronal. Compruébalo.
¡Prueba tus propias imágenes!
Lo que cubrimos:
- Construimos varias funciones de pérdida diferentes y utilizamos la retropropagación para transformar nuestra imagen de entrada con el fin de minimizar estas pérdidas.
- Para ello, cargamos un modelo preentrenado y utilizamos sus mapas de características aprendidas para describir el contenido y la representación de estilo de nuestras imágenes.
- Nuestras principales funciones de pérdida fueron principalmente el cálculo de la distancia en términos de estas diferentes representaciones.
- Implementamos esto con un modelo personalizado y una ejecución ansiosa.
- Construimos nuestro modelo personalizado con la API Funcional.
- La ejecución ansiosa nos permite trabajar dinámicamente con tensores, utilizando un flujo de control natural de python.
- Manipulamos tensores directamente, lo que facilita la depuración y el trabajo con tensores.
Actualizamos iterativamente nuestra imagen aplicando las reglas de actualización de nuestros optimizadores utilizando tf.gradient. El optimizador minimizó las pérdidas dadas con respecto a nuestra imagen de entrada.