I årenes løb har en masse mennesker haft problemer med at stave mit navn. Da jeg var yngre, gik jeg ud fra, at de ikke havde hørt navnet “Colin”. Det var ret usædvanligt, hvor jeg boede. I løbet af de sidste tyve år er navnet blevet mere populært, men staveproblemerne er ikke blevet bedre. Det viser sig, at der i disse dage er et andet problem: en alternativ stavemåde. Kan “Collin” virkelig være lige så almindeligt som “Colin”? Jeg troede ikke på det.
Gluksomt nok holder Social Security Administration styr på fornavne efter fødselsdato, og de gør disse data frit tilgængelige, så jeg kunne besvare det spørgsmål.
Det viste sig, at “Collin” oplevede et dramatisk spring i popularitet omkring århundredeskiftet og overskyggede kortvarigt det (korrekte, naturligvis) “Colin.”
Grafen viser den relative popularitet af “Colin” vs. “Collin for personer født siden 1940. I 1940 brugte ca. 85 procent af de to navne ét “l”, hvilket fortsatte ind i slutningen af halvfjerdserne; varianten med to “l” tog hurtigt fart og overgik kortvarigt den enkelte “l”-version omkring 1999, før den drev nedad siden da.
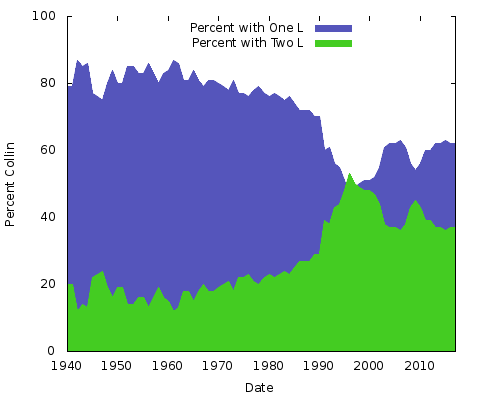
Hvad betyder det hele? Jeg har ingen anelse. Uanset hvad årsagerne er, vil de være anderledes for andre par af navne stavemåder. Man kunne gøre det samme for “Eric” vs. “Erik” eller “Rachel” vs. “Rachael” og mange andre. Lad os faktisk lave disse to:
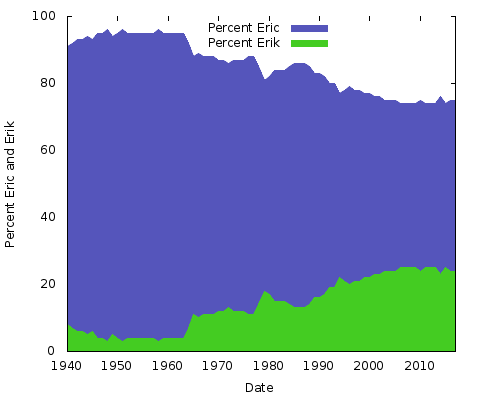
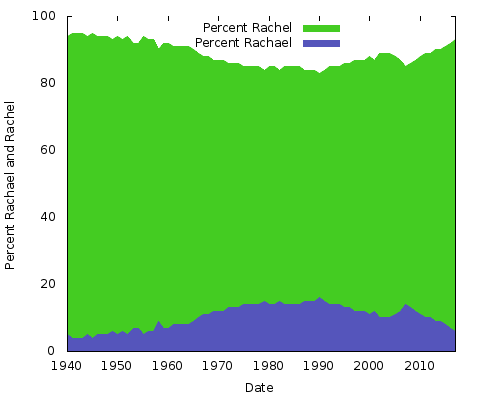
Dette er simple områdediagrammer. Til dette formål foretrækker jeg det frem for et stablet områdediagram; med kun to linjer, hvor summen af de to værdier på Y-aksen altid udgør 100 %, ville man bare ende med den samme nederste linje og den øverste halvdel i en ensfarvet farve. På denne måde får man en bedre idé om den store ændring i popularitet for de to stavemåder.
Et stablet områdediagram ville være fantastisk til at vise tendenser for mere end to navne: Du kan f.eks. vise ændringer i kønsforholdene i forbindelse med navne over tid med kun ét navn ved hjælp af et diagram som det ovenstående, men ved hjælp af ét billede kan du stable flere navne og formidle de samme oplysninger:
Social Security Baby Name Data
Dataene kommer fra SSA’s websted, hvor de gør de 1000 mest populære babynavne offentligt tilgængelige for hvert fødselsår i deres registre. Før 1940 er dataene ret sparsomme, da administrationen først blev oprettet i trediverne. Du kan stadig få navne tilbage til 1880, men der er færre, da kun folk, der blev indskrevet i trediverne og senere, er medtaget.
Få dataene på denne SSA-side. De kommer i et .zip-arkiv, der indeholder separate filer for hvert fødselsår, og der er en version af dataene opdelt efter amerikanske stater.
Dataene ser således ud
Linda,F,99686Mary,F,71688Patricia,F,51278Barbara,F,48791Sandra,F,34774Carol,F,33538Nancy,F,32442Dette er fra toppen af filen for 1947.
Du vil gerne kombinere de enkelte års filer til én og sandsynligvis tilføje en kolonne “Year of birth” (YOB) for at gøre det lettere at bruge den til tidsrelateret grafisk fremstilling. Jeg skrev et lille Ruby-script til at gøre jobbet.
For at fodre data til en grafpakke skal du sandsynligvis massere dataene noget mere: Du skal omdanne de rækker med et enkelt navn til rækker med kolonner for alle de datapunkter, som du ønsker at lave grafer. Disse kan være i én fil eller én fil pr. linje i grafen (Gnuplot lader dig arbejde på den måde, hvor du indlæser flere filer i én graf.) Du kan gøre dette med Ruby eller Python. Jeg gjorde det med SQL og værktøjet “Q Text-as-Data”, hvorefter jeg indførte resultatet i Gnuplot.