I dette indlæg vil vi lære web scraping med python. Ved hjælp af python skal vi scrape Yahoo Finance. Dette er en fantastisk kilde til aktiemarkedsdata. Vi vil kode en scraper til det. Ved hjælp af denne scraper vil du være i stand til at skrabe aktiedata for ethvert selskab fra yahoo finance. Som du ved, kan jeg godt lide at gøre tingene ret enkle, og derfor vil jeg også bruge en web scraper, som vil øge din scraping effektivitet.
Hvorfor dette værktøj? Dette værktøj vil hjælpe os med at skrabe dynamiske websteder ved hjælp af millioner af roterende proxies, så vi ikke bliver blokeret. Det giver også en clearingfacilitet. Det bruger headerless chrome til at skrabe dynamiske websteder.
Generelt er webscraping opdelt i to dele:
- Henter data ved at foretage en HTTP-forespørgsel
- Henter vigtige data ved at parsere HTML DOM
Biblioteker & Værktøjer
- Beautiful Soup er et Python-bibliotek til at trække data ud af HTML- og XML-filer.
- Requests giver dig mulighed for at sende HTTP-forespørgsler meget nemt.
- Webscraping-værktøj til at udtrække HTML-koden for mål-URL’en.
Setup
Vores opsætning er ret enkel. Du skal blot oprette en mappe og installere Beautiful Soup & anmodninger. For at oprette en mappe og installere biblioteker skal du skrive nedenstående angivne kommandoer. Jeg antager, at du allerede har installeret Python 3.x.
mkdir scraper
pip install beautifulsoup4
pip install requests
Nu skal du oprette en fil inde i denne mappe med et hvilket som helst navn, du vil. Jeg bruger scraping.py.
Først skal du tilmelde dig scrapingdog API. Det vil give dig 1000 GRATIS kreditter. Derefter skal du bare importere Beautiful Soup & anmodninger i din fil. som dette.
from bs4 import BeautifulSoup
import requests
Hvad vi skal scrape
Her er listen over felter, som vi vil udtrække:
- Previous Close
- Open
- Bid
- Ask
- Day’s Range
- 52 Week Range
- Volume
- Avg. Volume
- Market Cap
- Beta
- PE Ratio
- EPS
- Grundlagsindkomst
- Grundlagsudbytte
- Forward Dividend & Yield
- Ex-Udbytte & Dato
- 1y target EST
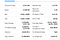
Forberedelse af maden
Nu, da vi har alle ingredienserne til at forberede skraberen, skal vi lave en GET-forespørgsel til mål-URL’en for at få de rå HTML-data. Hvis du ikke er bekendt med scraping-værktøjet, vil jeg opfordre dig til at gennemgå dets dokumentation. Nu vil vi skrabe Yahoo Finance for finansielle data ved hjælp af requests-biblioteket som vist nedenfor.
r = requests.get("https://api.scrapingdog.com/scrape?api_key=<your-api-key>&url=https://finance.yahoo.com/quote/AMZN?p=AMZN&.tsrc=fin-srch").text
Dette vil give dig en HTML-kode for denne mål-URL.
Nu skal du bruge BeautifulSoup til at parse HTML.
soup = BeautifulSoup(r,'html.parser')
Nu har vi på hele siden fire “tbody”-tags. Vi er interesseret i de to første, fordi vi i øjeblikket ikke har brug for de data, der er tilgængelige inde i de tredje & fjerde “tbody”-tags.
Først vil vi finde ud af alle disse “tbody”-tags ved hjælp af variablen “soup”.
alldata = soup.find_all("tbody")

Som du kan bemærke, at de to første “tbody” har 8 “tr”-tags, og hvert “tr”-tag har to “td”-tags.
try:
table1 = alldata.find_all("tr")
except:
table1=Nonetry:
table2 = alldata.find_all("tr")
except:
table2 = None
Nu har hvert “tr”-tag to “td”-tags. Det første td-tag består af navnet på egenskaben, og det andet har værdien af denne egenskab. Det er noget i retning af et nøgle-værdipar.

På dette tidspunkt skal vi erklære en liste og en ordbog, før vi starter en for-løkke.
l={}
u=list()
For at gøre koden enkel vil jeg køre to forskellige “for”-sløjfer for hver tabel. Først for “table1”
for i in range(0,len(table1)):
try:
table1_td = table1.find_all("td")
except:
table1_td = None l.text] = table1_td.text u.append(l)
l={}
Nu er det, vi har gjort, at vi gemmer alle td-tags i en variabel “table1_td”. Og så gemmer vi værdien af det første & andet td-tag i en “dictionary”. Derefter skubber vi ordbogen ind i en liste. Da vi ikke ønsker at gemme dobbelte data, vil vi gøre “dictionary” tomt til sidst. Lignende trin vil blive fulgt for “table2”.
for i in range(0,len(table2)):
try:
table2_td = table2.find_all("td")
except:
table2_td = None l.text] = table2_td.text u.append(l)
l={}
Så til sidst, når du udskriver listen “u”, får du et JSON-svar.
{
"Yahoo finance":
}
Er det ikke fantastisk. Det lykkedes os at scrape Yahoo finance på bare 5 minutters opsætning. Vi har et array af python Object, der indeholder de finansielle data for virksomheden Amazon. På denne måde kan vi skrabe data fra ethvert websted.
Slutning
I denne artikel forstod vi, hvordan vi kan skrabe data ved hjælp af data scraping værktøj & BeautifulSoup uanset typen af websted.
Føl dig fri til at kommentere og spørge mig om noget. Du kan følge mig på Twitter og Medium. Tak for læsning og tryk venligst på like-knappen! 👍
Supplerende ressourcer
Og der er listen! På dette tidspunkt bør du føle dig tryg ved at skrive din første webscraper til at indsamle data fra et hvilket som helst websted. Her er et par yderligere ressourcer, som du måske vil finde nyttige under din rejse til webscraping:
- Liste over webscraping-proxytjenester
- Liste over praktiske webscraping-værktøjer
- BeautifulSoup-dokumentation
- Scrapingdog-dokumentation
- Guide til webscraping