Af Raymond Yuan, Software Engineering Intern
I denne tutorial vil vi lære at bruge deep learning til at komponere billeder i stil med et andet billede (har du nogensinde ønsket, at du kunne male som Picasso eller Van Gogh?). Dette er kendt som neural stiloverførsel! Det er en teknik, der er skitseret i Leon A. Gatys’ artikel, A Neural Algorithm of Artistic Style, som er en fantastisk læsning, og du bør helt sikkert tjekke den ud.
Neural style transfer er en optimeringsteknik, der bruges til at tage tre billeder, et indholdsbillede, et stilreferencebillede (f.eks. et kunstværk af en berømt maler) og det indgangsbillede, du ønsker at style – og blande dem sammen, således at indgangsbilledet transformeres til at ligne indholdsbilledet, men “males” i stilen af stilbilledet.
Lad os f.eks. tage et billede af denne skildpadde og Katsushika Hokusais Den store bølge ud for Kanagawa:
Hvordan ville det nu se ud, hvis Hokusai besluttede sig for at tilføje tekstur eller stil af sine bølger til billedet af skildpadden? Noget i stil med dette?
Er dette magi eller bare deep learning? Heldigvis er der ikke tale om magi: stiloverførsel er en sjov og interessant teknik, der viser de neurale netværks evner og interne repræsentationer.
Princippet i neural stiloverførsel er at definere to afstandsfunktioner, en, der beskriver, hvor forskelligt indholdet af to billeder er, Lcontent, og en, der beskriver forskellen mellem de to billeder med hensyn til deres stil, Lstyle. Derefter, givet tre billeder, et ønsket stilbillede, et ønsket indholdsbillede og indgangsbilledet (initialiseret med indholdsbilledet), forsøger vi at transformere indgangsbilledet for at minimere indholdsafstanden med indholdsbilledet og dets stilafstand med stilbilledet.
Sammenfattende tager vi det grundlæggende indgangsbillede, et indholdsbillede, som vi ønsker at matche, og det stilbillede, som vi ønsker at matche. Vi transformerer basisindgangsbilledet ved at minimere indholds- og stilafstandene (tab) med backpropagation og skaber et billede, der matcher indholdsbilledet og stilbilledet.
I processen vil vi opbygge praktisk erfaring og udvikle intuition omkring følgende begreber:
- Eager Execution – brug TensorFlows imperative programmeringsmiljø, der evaluerer operationer med det samme
- Lær mere om eager execution
- Se det i praksis (mange af tutorials kan køres i Colaboratory)
- Brug af Functional API til at definere en model – vi opbygger en delmængde af vores model, der giver os adgang til de nødvendige mellemliggende aktiveringer ved hjælp af Functional API
- Udnyttelse af feature maps af en pretrained model – Lær at bruge pretrained modeller og deres feature maps
- Opret brugerdefinerede træningssløjfer – vi undersøger, hvordan man opsætter en optimizer til at minimere et givet tab med hensyn til inputparametre
- Vi følger de generelle trin for at udføre stiloverførsel:
- Kode:
- Implementering
- Definere indholds- og stilrepræsentationer
- Hvorfor mellemliggende lag?
- Model
- Definér og opret vores tabsfunktioner (indholds- og stilafstande)
- Stiltab:
- Run Gradient Descent
- Beregne tab og gradienter
- Anvend og kør stiloverførselsprocessen
- Hvad vi dækkede:
Vi følger de generelle trin for at udføre stiloverførsel:
- Visualisere data
- Grundlæggende forbehandling/forberedelse af vores data
- Sæt tabsfunktioner op
- Opret model
- Optimering for tabsfunktion
Publikum:
Dette indlæg henvender sig til brugere på mellemniveau, der er fortrolige med grundlæggende maskinlæringsbegreber. For at få mest muligt ud af dette indlæg bør du:
- Læse Gatys’ artikel – vi forklarer undervejs, men artiklen vil give en mere grundig forståelse af opgaven
- Forstå gradient descent
Tidsforventning: 60 min
Kode:
Du kan finde den komplette kode til denne artikel på dette link. Hvis du gerne vil gennemgå dette eksempel trinvis, kan du finde colab’en her.
Implementering
Vi begynder med at aktivere eager execution. Eager execution giver os mulighed for at gennemgå denne teknik på den klareste og mest læsbare måde.

Definere indholds- og stilrepræsentationer
For at få både indholds- og stilrepræsentationer af vores billede, vil vi se på nogle mellemliggende lag i vores model. Mellemliggende lag repræsenterer funktionskort, der bliver stadig højere ordnet, efterhånden som man går dybere ned. I dette tilfælde bruger vi netværksarkitekturen VGG19, som er et forudtrænet billedklassifikationsnetværk. Disse mellemliggende lag er nødvendige for at definere repræsentationen af indhold og stil fra vores billeder. For et indgangsbillede vil vi forsøge at matche de tilsvarende stil- og indholdsmålrepræsentationer på disse mellemliggende lag.
Hvorfor mellemliggende lag?
Du undrer dig måske over, hvorfor disse mellemliggende udgange i vores prætrænede billedklassifikationsnetværk giver os mulighed for at definere stil- og indholdsrepræsentationer. På et højt niveau kan dette fænomen forklares ved, at for at et netværk kan udføre billedklassifikation (hvilket vores netværk er blevet trænet til at gøre), skal det forstå billedet. Dette indebærer, at man tager det rå billede som inputpixels og opbygger en intern repræsentation gennem transformationer, der forvandler de rå billedpixels til en kompleks forståelse af de funktioner, der findes i billedet. Dette er også til dels grunden til, at konvolutionelle neurale netværk er i stand til at generalisere godt: de er i stand til at fange de invarianter og definerende træk inden for klasser (f.eks. katte vs. hunde), der er agnostiske over for baggrundsstøj og andre ulemper. Et eller andet sted mellem det sted, hvor det rå billede indlæses, og klassifikationsmærket outputes, fungerer modellen således som en kompleks feature extractor; ved at få adgang til mellemliggende lag er vi således i stand til at beskrive indholdet og stilen af indgangsbilleder.
Specifikt vil vi trække disse mellemliggende lag ud af vores netværk:
Model
I dette tilfælde indlæser vi VGG19 og indlæser vores input tensor til modellen. Dette vil give os mulighed for at udtrække feature maps (og efterfølgende indholds- og stilrepræsentationerne) for indhold, stil og genererede billeder.
Vi bruger VGG19, som foreslået i artiklen. Da VGG19 desuden er en relativt simpel model (sammenlignet med ResNet, Inception osv.), fungerer feature maps faktisk bedre til stiloverførsel.
For at få adgang til de mellemliggende lag, der svarer til vores stil- og indholdsfunktionsmapper, får vi de tilsvarende output ved at bruge Keras Functional API til at definere vores model med de ønskede output-aktiveringer.
Med Functional API’en indebærer definitionen af en model blot, at input og output defineres: model = Model(inputs, outputs).
I ovenstående kodestump indlæser vi vores forud trænede billedklassifikationsnetværk. Derefter henter vi de lag af interesse, som vi definerede tidligere. Derefter definerer vi en model ved at indstille modellens input til et billede og outputs til output fra stil- og indholdslagene. Med andre ord har vi oprettet en model, der tager et indgangsbillede og udsender indholds- og stilmellemlagene!
Definér og opret vores tabsfunktioner (indholds- og stilafstande)
Vores indholdstabsdefinition er faktisk ret enkel. Vi sender netværket både det ønskede indholdsbillede og vores basisindgangsbillede. Dette vil returnere de mellemliggende lagoutput (fra de ovenfor definerede lag) fra vores model. Derefter tager vi simpelthen den euklidiske afstand mellem de to mellemliggende repræsentationer af disse billeder.
Mere formelt set er indholdstab en funktion, der beskriver afstanden af indhold fra vores indgangsbillede x og vores indholdsbillede, p . Lad Cₙₙ være et forud trænet dybt konvolutionelt neuralt netværk. Igen bruger vi i dette tilfælde VGG19. Lad X være et vilkårligt billede, så er Cₙₙ(x) det netværk, der fodres af X. Lad Fˡᵢⱼ(x)∈ Cₙₙ(x)og Pˡᵢⱼ(x) ∈ Cₙₙ(x) beskrive den respektive mellemliggende feature-repræsentation af netværket med input x og p i lag l . Derefter beskriver vi indholdsafstanden (tabet) formelt som:
Vi udfører backpropagation på den sædvanlige måde, således at vi minimerer dette indholdstab. Vi ændrer således det oprindelige billede, indtil det genererer en lignende respons i et bestemt lag (defineret i content_layer) som det oprindelige indholdsbillede.
Dette kan gennemføres ganske enkelt. Igen vil den som input tage feature maps i et lag L i et netværk, der fodres med x, vores inputbillede, og p, vores indholdsbillede, og returnere indholdsafstanden.
Stiltab:
Beregning af stiltab er lidt mere kompliceret, men følger samme princip, idet vi denne gang fodrer vores netværk med basisinputbilledet og stilbilledet. Men i stedet for at sammenligne de rå mellemliggende output af basisindgangsbilledet og stilbilledet sammenligner vi i stedet Gram-matricerne for de to output.
Matematisk set beskriver vi stiltab for basisindgangsbilledet, x, og stilbilledet, a, som afstanden mellem stilrepræsentationen (Gram-matricerne) for disse billeder. Vi beskriver stilrepræsentationen af et billede som korrelationen mellem forskellige filterresponser givet ved Gram-matrixen Gˡ, hvor Gˡᵢⱼ er det indre produkt mellem det vektoriserede feature map i og j i lag l. Vi kan se, at Gˡᵢⱼ genereret over funktionskortet for et givet billede repræsenterer korrelationen mellem funktionskort i og j.
For at generere en stil for vores basisindgangsbillede udfører vi gradientafstigning fra indholdsbilledet for at omdanne det til et billede, der matcher stilrepræsentationen af det oprindelige billede. Det gør vi ved at minimere den gennemsnitlige kvadrerede afstand mellem stilbilledets og indgangsbilledets korrelationskort for funktionerne. Hvert lags bidrag til det samlede stiltab beskrives ved
hvor Gˡᵢⱼ og Aˡᵢⱼ er de respektive stilrepræsentationer i lag l af indgangsbillede x og stilbillede a. Nl beskriver antallet af feature maps, der hver har en størrelse Ml=højde∗bredde. Det samlede stiltab på tværs af hvert lag er således
hvor vi vægter bidraget fra hvert lags tab med en eller anden faktor wl. I vores tilfælde vægter vi hvert lag lige meget:
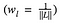
Dette gennemføres ganske enkelt:
Run Gradient Descent
Hvis du ikke er bekendt med gradient descent/backpropagation eller har brug for en genopfriskning, bør du helt sikkert tjekke denne ressource.
I dette tilfælde bruger vi Adam-optimeringen for at minimere vores tab. Vi opdaterer iterativt vores udgangsbillede således, at det minimerer vores tab: Vi opdaterer ikke vægtene i forbindelse med vores netværk, men træner i stedet vores indgangsbillede for at minimere tabet. For at kunne gøre dette, skal vi vide, hvordan vi beregner vores tab og gradienter. Bemærk, at L-BFGS-optimeringen, som, hvis du er bekendt med denne algoritme, anbefales, men som ikke anvendes i denne tutorial, fordi en primær motivation bag denne tutorial var at illustrere bedste praksis med eager execution. Ved at bruge Adam kan vi demonstrere autograd/gradienttape-funktionaliteten med brugerdefinerede træningssløjfer.
Beregne tab og gradienter
Vi vil definere en lille hjælpefunktion, der vil indlæse vores indholds- og stilbillede, fodre dem fremad gennem vores netværk, som derefter vil output indholds- og stilfunktionsrepræsentationer fra vores model.
Her bruger vi tf.GradientTape til at beregne gradienten. Det giver os mulighed for at drage fordel af den automatiske differentiering, der er tilgængelig ved sporingsoperationer til beregning af gradienten senere. Den registrerer operationerne under den fremadgående passage og er derefter i stand til at beregne gradienten af vores tabsfunktion i forhold til vores indgangsbillede for den bagudgående passage.
Så er det nemt at beregne gradienterne:
Anvend og kør stiloverførselsprocessen
Og for faktisk at udføre stiloverførslen:
Og det er det!
Lad os køre den på vores billede af skildpadden og Hokusais Den store bølge ved Kanagawa:

Se den iterative proces over tid:

Her er nogle andre fede eksempler på, hvad neural stiloverførsel kan gøre. Tjek det ud!
Afprøv dine egne billeder!
Hvad vi dækkede:
- Vi opbyggede flere forskellige tabsfunktioner og brugte backpropagation til at transformere vores indgangsbillede for at minimere disse tab.
- For at gøre dette indlæste vi en prætrænet model og brugte dens lærte feature maps til at beskrive indholds- og stilrepræsentationen af vores billeder.
- Vores vigtigste tabsfunktioner var primært beregning af afstanden i form af disse forskellige repræsentationer.
- Vi implementerede dette med en brugerdefineret model og eager eksekvering.
- Vi byggede vores brugerdefinerede model med Functional API.
- Eager execution giver os mulighed for dynamisk at arbejde med tensorer ved hjælp af et naturligt python-kontrolflow.
- Vi manipulerede tensorer direkte, hvilket gør det lettere at fejlfinde og arbejde med tensorer.
Vi opdaterede iterativt vores billede ved at anvende vores optimeringsregler til opdatering ved hjælp af tf.gradient. Optimereren minimerede de givne tab i forhold til vores indgangsbillede.