Vuosien varrella monilla ihmisillä on ollut vaikeuksia kirjoittaa nimeäni. Nuorempana oletin, etteivät he olleet kuulleet nimeä ”Colin”. Se oli aika epätavallista siellä missä asuin. Viimeisten kahdenkymmenen vuoden aikana nimestä on tullut suositumpi, mutta oikeinkirjoitusvaikeudet eivät ole parantuneet. Kävi ilmi, että nykyään on toinenkin ongelma: vaihtoehtoinen kirjoitusasu. Voisiko ”Collin” todella olla yhtä yleinen kuin ”Colin”? En uskonut sitä.
Onneksi sosiaaliturvalaitos pitää kirjaa etunimistä syntymäajan mukaan, ja he antavat nämä tiedot vapaasti saataville, joten pystyin vastaamaan tuohon kysymykseen.
Kiinni kävi ilmi, että ”Collin” koki dramaattisen harppauksen suosiossa vuosisadan vaihteen tienoilla, ja se jätti hetkellisesti varjoonsa (oikean, tietenkin) ”Colinin.”
Graafi osoittaa ”Colinin” vs. ”Collininin suhteellista suosiota vuodesta 1940 lähtien syntyneiden osalta. Vuonna 1940 noin 85 prosenttia näistä kahdesta nimestä käytti yhtä ”l”:ää, mikä säilyi 70-luvun lopulle asti; kahden ”l”:n variantti lähti nopeasti liikkeelle ja ylitti hetkeksi yhden ”l”:n version vuoden 1999 tienoilla ennen kuin se on sen jälkeen ajautunut alemmas.
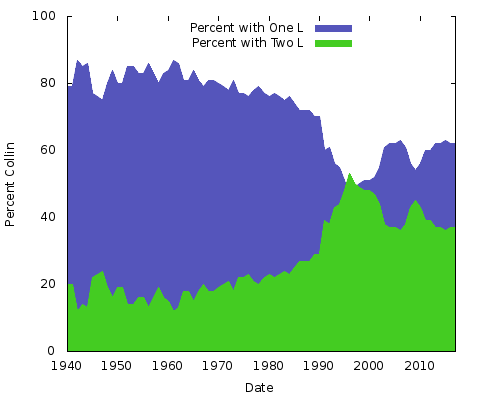
Mitä tämä kaikki tarkoittaa? Minulla ei ole aavistustakaan. Olivatpa syyt mitkä tahansa, ne ovat erilaisia muiden nimien kirjoitusasuparien kohdalla. Voit tehdä saman ”Eric” vs. ”Erik” tai ”Rachel” vs. ”Rachael” ja monille muille. Itse asiassa tehdään nuo kaksi:
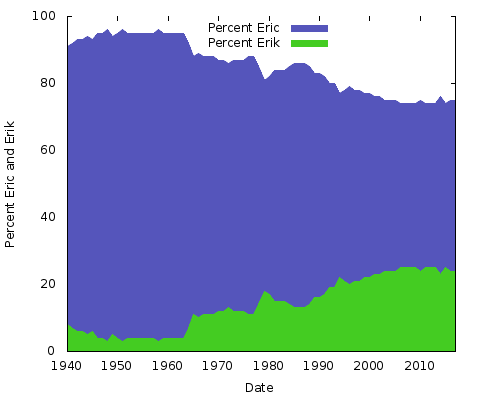
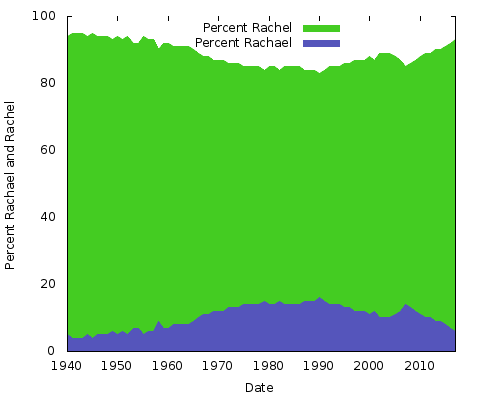
Nämä ovat yksinkertaisia aluekaavioita. Tähän tarkoitukseen pidän sitä parempana kuin pinottua aluekaaviota; vain kahdella viivalla, jossa kahden Y-akselin arvojen summa on aina 100 %, päädyttäisiin vain siihen, että alin viiva on sama ja yläpuolisko yksivärinen. Näin saat paremman käsityksen kahden kirjoitusasun suosion suuresta muutoksesta.
Pinotettu aluekaavio olisi loistava useamman kuin kahden nimen trendien näyttämiseen: Voisit esimerkiksi näyttää nimiin liittyvän sukupuolen muuttumisen ajan kuluessa vain yhdellä nimellä käyttämällä yllä olevan kaltaista kaaviota, mutta yhtä kuvaa käyttämällä voisit pinota useita nimiä ja välittää saman tiedon:
Social Security Baby Name Data
Tiedot ovat peräisin SSA:n verkkosivuilta, joilla he julkaisevat julkisesti 1000 suosituinta vauvan nimeä jokaiselta syntymävuodelta. Ennen vuotta 1940 tiedot ovat melko niukkoja, koska hallinto perustettiin vasta 30-luvulla. Voit silti saada nimiä aina vuoteen 1880 asti, mutta niitä on vähemmän, koska mukana ovat vain ihmiset, jotka ilmoittautuivat 30-luvulla ja sen jälkeen.
Saa tiedot tältä SSA:n sivulta. Se on .zip-arkistossa, jossa on erilliset tiedostot jokaiselle syntymävuodelle, ja siellä on versio tiedoista eriteltyinä Yhdysvaltain osavaltioiden mukaan.
Tiedot näyttävät seuraavalta
Linda,F,99686Mary,F,71688Patricia,F,51278Barbara,F,48791Sandra,F,34774Carol,F,33538Nancy,F,32442Tämä on vuoden 1947 tiedoston yläosasta.
Haluat yhdistää yksittäiset vuositiedostot yhdeksi ja luultavasti lisätä ”Syntymävuosi”-sarakkeen (Year of birth, YOB) helpottaaksesi sen käyttöä aikaan liittyvässä graafisessa kuvailussa. Kirjoitin pienen Ruby-skriptin, joka tekee tämän työn.
Syöttääksesi dataa grafiikkapakettiin sinun on luultavasti hierottava dataa lisää: Sinun on muutettava yhdellä nimellä varustetut rivit riveiksi, joissa on sarakkeet kaikille niille datapisteille, jotka haluat graafisesti esittää. Nämä voivat olla yhdessä tiedostossa tai yksi tiedosto jokaista kuvaajan riviä kohden (Gnuplot antaa sinun työskennellä tällä tavalla, lataamalla useita tiedostoja yhteen kuvaajaan.) Voit tehdä tämän Rubyllä tai Pythonilla. Minä tein sen SQL:llä ja ”Q Text-as-Data” -työkalulla ja syötin tuloksen Gnuplotiin.