Tämässä postauksessa, menemme opettelemaan web scraping pythonilla. Käyttämällä pythonia aiomme kaapia Yahoo Financen. Tämä on loistava pörssitietojen lähde. Koodaamme scraperin sitä varten. Käyttämällä tätä kaapijaa voisit kaapia minkä tahansa yrityksen pörssitiedot Yahoo Financesta. Kuten tiedätte, haluan tehdä asioista melko yksinkertaisia, ja siksi käytän myös verkkokaapuria, joka lisää kaapimisen tehokkuutta.
Miksi tämä työkalu? Tämä työkalu auttaa meitä kaapimaan dynaamisia verkkosivustoja käyttämällä miljoonia pyöriviä välityspalvelimia, jotta meitä ei estetä. Se tarjoaa myös selvitysmahdollisuuden. Se käyttää headerless chromea dynaamisten verkkosivujen kaapimiseen.
Yleisesti web scraping jaetaan kahteen osaan:
- Datan hakeminen tekemällä HTTP-pyyntö
- Tärkeän datan poimiminen jäsentämällä HTML DOM
Kirjastot &Työkalut
- Kaunis keitto (Beautiful Soup) on Python-kirjasto, jonka avulla voi vetää dataa HTML- ja XML-tiedostoista.
- Pyyntöjen avulla voit lähettää HTTP-pyyntöjä hyvin helposti.
- Web scraping -työkalu, jolla voit poimia kohde-URL:n HTML-koodin.
Asennus
Asennuksemme on melko yksinkertainen. Luo vain kansio ja asenna Beautiful Soup & pyynnöt. Kansion luomista ja kirjastojen asentamista varten kirjoita alla olevat komennot. Oletan, että olet jo asentanut Python 3.x.
mkdir scraper
pip install beautifulsoup4
pip install requests
Luo nyt kansion sisälle tiedosto haluamallasi nimellä. Käytän scraping.py.
Ensin sinun täytyy rekisteröityä scrapingdog API:lle. Se antaa sinulle 1000 ILMAISTA krediittiä. Sitten vain tuo Kaunis keitto & pyynnöt tiedostoosi. näin.
from bs4 import BeautifulSoup
import requests
Mitä aiomme scrapeilla
Tässä on lista kentistä, jotka aiomme poimia:
- Previous Close
- Open
- Bid
- Ask
- Day’s Range
- 52 Week Range
- Volume
- Avg. Volume
- Market Cap
- Beta
- PE Ratio
- EPS
- Earnings Rate
- Forward Dividend & Yield
- Ex-Osinko & Päiväys
- 1v tavoite EST
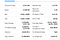
Ruoan valmistelu
Nyt, koska meillä on kaikki ainekset skrapperin valmisteluun, meidän pitäisi tehdä GET-pyyntö kohde-URL-osoitteeseen saadaksemme raa’an HTML-datan. Jos kaavintatyökalu ei ole sinulle tuttu, kehotan sinua tutustumaan sen dokumentaatioon. Nyt kaapimme Yahoo Finance -rahoitustietoja käyttäen pyyntöjen kirjastoa alla esitetyllä tavalla.
r = requests.get("https://api.scrapingdog.com/scrape?api_key=<your-api-key>&url=https://finance.yahoo.com/quote/AMZN?p=AMZN&.tsrc=fin-srch").text
Tämä antaa sinulle kyseisen kohde-URL:n HTML-koodin.
Nyt sinun täytyy käyttää BeautifulSoupia HTML:n jäsentämiseen.
soup = BeautifulSoup(r,'html.parser')
Nyt koko sivulla on neljä ”tbody”-tagia. Olemme kiinnostuneita kahdesta ensimmäisestä, koska emme tällä hetkellä tarvitse kolmannen & neljännen ”tbody”-tunnisteen sisällä olevia tietoja.
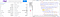
Ensiksi selvitämme kaikki nuo tbody-tunnisteet muuttujan ”soup” avulla.
alldata = soup.find_all("tbody")

Kuten huomaat, että kahdessa ensimmäisessä ”tbody”-tunnisteessa on kahdeksan ”tr”-tunnistetta ja jokaisella ”tr”-tunnisteella on kaksi ”td”-tagia.
try:
table1 = alldata.find_all("tr")
except:
table1=Nonetry:
table2 = alldata.find_all("tr")
except:
table2 = None
Nyt jokaisessa ”tr”-tagissa on kaksi ”td”-tagia. Ensimmäinen td-tagi koostuu ominaisuuden nimestä ja toisessa on kyseisen ominaisuuden arvo. Se on ikään kuin avain-arvopari.

Tässä vaiheessa ilmoitamme listan ja sanakirjan, ennen kuin aloitamme for-silmukan.
l={}
u=list()
Koodin yksinkertaisuuden vuoksi suoritan kullekin taulukolle kaksi erilaista ”for”-ilmukkaa. Ensin ”table1”
for i in range(0,len(table1)):
try:
table1_td = table1.find_all("td")
except:
table1_td = None l.text] = table1_td.text u.append(l)
l={}
Nyt olemme tehneet sen, että tallennamme kaikki td-tagit muuttujaan ”table1_td”. Ja sitten tallennamme ensimmäisen & toisen td-tunnisteen arvon muuttujaan ”dictionary”. Sitten työnnämme sanakirjan luetteloon. Koska emme halua tallentaa päällekkäisiä tietoja, teemme sanakirjasta lopussa tyhjän. Samanlaisia vaiheita noudatetaan myös ”taulukon2” kohdalla.
for i in range(0,len(table2)):
try:
table2_td = table2.find_all("td")
except:
table2_td = None l.text] = table2_td.text u.append(l)
l={}
Silloin lopussa kun tulostat listan ”u” saat JSON-vastauksen.
{
"Yahoo finance":
}
Eikö olekin mahtavaa. Onnistuimme kaapimaan Yahoo finanssia vain 5 minuutin asennuksessa. Meillä on array of python Object, joka sisältää yrityksen Amazon taloudelliset tiedot. Näin voimme kaapia tietoja miltä tahansa verkkosivustolta.
Johtopäätös
Tässä artikkelissa ymmärsimme, miten voimme kaapia tietoja käyttämällä tietojen kaapimistyökalua & BeautifulSoup riippumatta verkkosivuston tyypistä.
Kommentoi vapaasti ja kysy minulta mitä tahansa. Voit seurata minua Twitterissä ja Mediumissa. Kiitos lukemisesta ja paina tykkää-painiketta! 👍
Lisäresursseja
Ja siinä on lista! Tässä vaiheessa sinun pitäisi tuntea olosi mukavaksi, kun kirjoitat ensimmäisen web scraperin, jolla voit kerätä tietoja miltä tahansa verkkosivustolta. Seuraavassa on muutama lisäresurssi, joista voi olla apua verkkokaapimismatkasi aikana:
- Luettelo verkkokaapimisen välityspalveluista
- Luettelo kätevistä verkkokaapimistyökaluista
- BeautifulSoup-dokumentaatio
- Scrapingdog-dokumentaatio
- Ohje verkkokaapimiseen