Az évek során sok embernek gondot okozott a nevem helyesírása. Fiatalabb koromban azt feltételeztem, hogy nem hallották a “Colin” nevet. Elég szokatlan volt ott, ahol éltem. Az elmúlt húsz évben a név népszerűbb lett, de a helyesírási problémák nem javultak. Kiderült, hogy manapság van egy másik probléma is: egy alternatív írásmód. Lehet, hogy a “Collin” tényleg olyan gyakori, mint a “Colin”? Nem hittem benne.
Szerencsére a társadalombiztosítási hivatal a születési dátum szerint nyilvántartja a keresztneveket, és ezeket az adatokat szabadon hozzáférhetővé teszik, így megválaszolhattam a kérdést.
Mint kiderült, a “Collin” népszerűsége a századforduló környékén drámaian megugrott, és pillanatnyilag háttérbe szorította a (természetesen helyes) “Colint.”
A grafikon a “Colin” és a “Collin” relatív népszerűségét mutatja az 1940 óta született emberek esetében. 1940-ben a két név mintegy 85 százaléka egy “l”-t használt, ami a hetvenes évek végéig fennmaradt; a két “l”-es változat gyorsan szárnyalt, és 1999 körül rövid időre megelőzte az egy “l”-es változatot, mielőtt azóta egyre lejjebb sodródott.
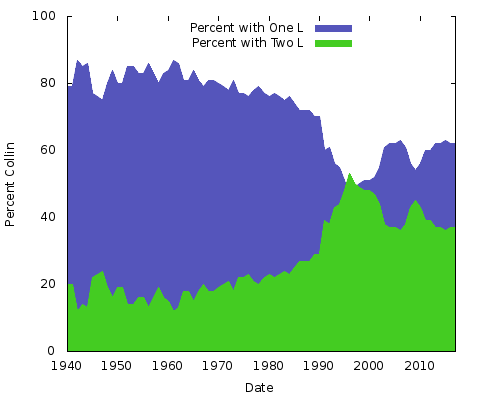
Mit jelent mindez? Fogalmam sincs. Bármi legyen is az ok, a többi névíráspár esetében más lesz. Ugyanezt megtehetnéd az “Eric” vs. “Erik” vagy a “Rachel” vs. “Rachael” és még sok más esetében. Tulajdonképpen csináljuk meg ezt a kettőt:
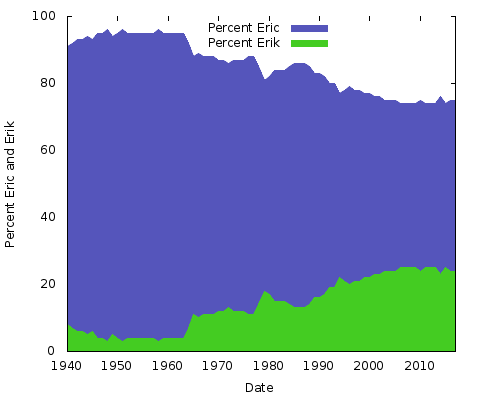
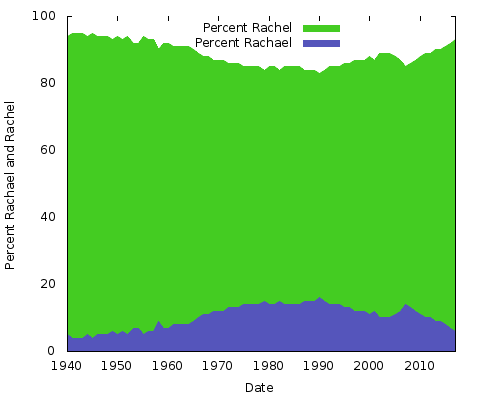
Ezek egyszerű területi ábrák. Erre a célra én jobban szeretem, mint a halmozott területi diagramot; csak két vonallal, ahol a két Y-tengely értékének összege mindig 100%-ot tesz ki, akkor csak azt kapnánk, hogy az alsó vonal ugyanaz, a felső fele pedig egyszínű. Így jobb képet kaphatsz a két írásmód népszerűségének nagy változásáról.
A halmozott területi diagram nagyszerű lenne több mint két név tendenciáinak bemutatására: Például a nevekhez kapcsolódó nemek időbeli változását csak egy névvel mutathatná be a fentihez hasonló grafikon segítségével, de egy kép segítségével több nevet is egymásra halmozhatna, és ugyanazt az információt közvetíthetné:
Social Security Baby Name Data
Az adatok az SSA weboldaláról származnak, ahol nyilvánosan elérhetővé teszik a legnépszerűbb 1000 legnépszerűbb babanevet a nyilvántartásukban szereplő minden születési évre vonatkozóan. Az 1940 előtti adatok elég gyéren állnak rendelkezésre, mivel az adminisztrációt csak a harmincas években hozták létre. Még 1880-ig visszamenőleg is lehet neveket kapni, de kevesebbet, mivel csak azok szerepelnek, akik a harmincas években és később iratkoztak be.
Az adatokat ezen az SSA-oldalon találod. Ez egy .zip archívumban van, amely minden születési évhez külön fájlokat tartalmaz, és van az adatoknak egy amerikai államokra lebontott változata is.
Az adatok így néznek ki
Linda,F,99686Mary,F,71688Patricia,F,51278Barbara,F,48791Sandra,F,34774Carol,F,33538Nancy,F,32442Az 1947-es fájl tetejéről van szó.
Az egyes évszámú fájlokat egybe kell egyesíteni, és valószínűleg hozzá kell adni egy “Születési év” (YOB) oszlopot, hogy könnyebben lehessen használni az idővel kapcsolatos grafikonok készítéséhez. Írtam egy kis Ruby szkriptet a feladat elvégzésére.
Az adatoknak egy grafikus csomagba való betáplálásához valószínűleg tovább kell masszírozni az adatokat: Át kell alakítania az egyetlen névvel ellátott sorokat olyan sorokká, amelyekben oszlopok vannak az összes olyan adatponthoz, amelyet grafikonozni szeretne. Ezek lehetnek egy fájlban vagy a grafikon soronként egy fájlban (a Gnuplot lehetővé teszi, hogy így dolgozzon, és több fájlt töltsön be egy grafikonba.) Ezt megteheti Ruby vagy Python segítségével. Én SQL-el és a “Q Text-as-Data” eszközzel csináltam, majd az eredményt betápláltam a Gnuplotba.