Az alábbi bejegyzésben a python segítségével fogunk web scrapinget tanulni. A python segítségével a Yahoo Finance-t fogjuk lekaparni. Ez egy nagyszerű forrás a tőzsdei adatokhoz. Ehhez fogunk kódolni egy scraper-t. Ezzel a scraperrel bármely vállalat részvényadatait lekaparhatnánk a yahoo finance-ból. Mint tudod, szeretem a dolgokat elég egyszerűvé tenni, ehhez egy web scraper-t is fogok használni, ami növeli a scraping hatékonyságát.
Miért ez az eszköz? Ez az eszköz segíteni fog nekünk abban, hogy dinamikus weboldalakat kaparjunk milliónyi forgó proxyt használva, hogy ne blokkoljanak minket. Ezenkívül tisztítási lehetőséget is biztosít. Header nélküli Chrome-ot használ a dinamikus weboldalak kaparásához.
A webkaparás általában két részre oszlik:
- Adatok lekérdezése HTTP-kéréssel
- A fontos adatok kinyerése a HTML DOM elemzése révén
Könyvtárak & Eszközök
- A Beautiful Soup egy Python könyvtár, amellyel HTML és XML fájlokból lehet adatokat kinyerni.
- A Requests lehetővé teszi, hogy HTTP kéréseket küldjünk nagyon egyszerűen.
- web scraping eszköz a cél URL HTML kódjának kinyeréséhez.
Setup
A beállításunk elég egyszerű. Csak hozzon létre egy mappát és telepítse a Beautiful Soup & kéréseket. A mappa létrehozásához és a könyvtárak telepítéséhez írja be az alábbi parancsokat. Feltételezem, hogy már telepítetted a Python 3.x.
mkdir scraper
pip install beautifulsoup4
pip install requests
Most hozz létre egy fájlt a mappán belül, tetszőleges névvel. Én a scraping.py-t használom.
Először is fel kell iratkoznod a scrapingdog API-ra. Ez 1000 INGYENES kreditet biztosít számodra. Ezután csak importáld a Beautiful Soup & kéréseket a fájlodba. például így.
from bs4 import BeautifulSoup
import requests
Mit fogunk lekaparni
Itt van a mezők listája, amelyeket ki fogunk nyerni:
- Előző zárás
- nyit
- Bid
- Ask
- Day’s Range
- 52 Week Range
- Volume
- Avg. Volume
- Market Cap
- Beta
- PE Ratio
- EPS
- Earnings Rate
- Forward Dividend & Yield
- Ex-Osztalék & Dátum
- 1y target EST
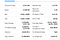
Előkészítés
Most, mivel minden hozzávalónk megvan a scraper elkészítéséhez, a nyers HTML-adatok megszerzéséhez GET-kérést kell indítanunk a cél URL-címére. Ha nem ismeri a kaparó eszközt, akkor javaslom, hogy nézze át a dokumentációját. Most a Yahoo Finance pénzügyi adatait fogjuk lekaparni az alábbiakban látható requests könyvtár segítségével.
r = requests.get("https://api.scrapingdog.com/scrape?api_key=<your-api-key>&url=https://finance.yahoo.com/quote/AMZN?p=AMZN&.tsrc=fin-srch").text
Ezzel megkapjuk a cél URL HTML kódját.
Most a BeautifulSoup-ot kell használnunk a HTML elemzésére.
soup = BeautifulSoup(r,'html.parser')
Most az egész oldalon négy “tbody” tag van. Minket az első kettő érdekel, mert jelenleg nincs szükségünk a harmadik & negyedik “tbody” címkén belül rendelkezésre álló adatokra.
Először is, a “soup” változó segítségével megkeressük az összes “tbody” címkét.
alldata = soup.find_all("tbody")

Mint láthatjuk, az első két “tbody”-ban 8 “tr” tag van, és minden “tr” taghez két “td” tag tartozik.
try:
table1 = alldata.find_all("tr")
except:
table1=Nonetry:
table2 = alldata.find_all("tr")
except:
table2 = None
Most minden “tr” taghez két “td” tag tartozik. Az első td tag a tulajdonság nevét tartalmazza, a másik pedig a tulajdonság értékét. Ez olyasmi, mint egy kulcs-érték pár.

Ezzel a ponttal egy listát és egy szótárat fogunk deklarálni, mielőtt elindítjuk a for ciklusunkat.
l={}
u=list()
A kód egyszerűsítése érdekében két különböző “for” kört fogok lefuttatni minden táblára. Először a “table1”
for i in range(0,len(table1)):
try:
table1_td = table1.find_all("td")
except:
table1_td = None l.text] = table1_td.text u.append(l)
l={}
Most, amit csináltunk, az az, hogy az összes td taget egy “table1_td” változóban tároljuk. Aztán az első & második td tag értékét egy “dictionary” változóban tároljuk. Ezután a szótárat egy listába tesszük. Mivel nem akarunk duplikált adatokat tárolni, a végén a szótárat üressé tesszük. Hasonló lépéseket fogunk követni a “table2” esetében is.
for i in range(0,len(table2)):
try:
table2_td = table2.find_all("td")
except:
table2_td = None l.text] = table2_td.text u.append(l)
l={}
A végén, amikor kiírjuk a listát “u”, egy JSON választ kapunk.
{
"Yahoo finance":
}
Hát nem csodálatos? A Yahoo finance-t mindössze 5 perc beállítási idő alatt sikerült lekaparni. Van egy python Object tömbünk, amely az Amazon cég pénzügyi adatait tartalmazza. Így bármilyen weboldalról lekaparhatjuk az adatokat.
Következtetés
Ezzel a cikkel megértettük, hogyan tudunk adatokat lekaparni az & BeautifulSoup adatkaparó eszközzel, függetlenül a weboldal típusától.
Kommentáljon nyugodtan, és kérdezzen tőlem bármit. Követhet engem a Twitteren és a Mediumon. Köszönöm az olvasást, és kérem, nyomja meg a tetszik gombot! 👍
Kiegészítő források
És itt a lista! Ezen a ponton már kényelmesnek kell érezned, hogy megírd az első web scraperedet, amivel adatokat gyűjthetsz bármilyen weboldalról. Íme néhány további forrás, amelyet hasznosnak találhat a webkaparás során:
- List of web scraping proxy services
- List of handy web scraping tools
- BeautifulSoup Documentation
- Scrapingdog Documentation
- Guide to web scraping