By Raymond Yuan, ソフトウェア エンジニアリング インターン
このチュートリアルでは、ディープラーニングを使用して、別の画像のスタイルで画像を構成する方法を学びます (ピカソやゴッホのように描けたらと思ったことはありませんか?) 。). これは、ニューラル・スタイル・トランスファーとして知られています! これは、Leon A. Gatys の論文「A Neural Algorithm of Artistic Style」に概説されている手法で、非常に読み応えがあるので、ぜひチェックしてみてください。
Neural style transfer は、コンテンツ画像、スタイル参照画像(有名画家のアートワークなど)、スタイルを設定したい入力画像の 3 つの画像を取り、入力画像がコンテンツ画像のように見えるがスタイル画像のスタイルの「絵」になるようにそれらをブレンドするのに使われる最適化技法です。
たとえば、このカメの画像と葛飾北斎の「神奈川沖浪裏」を例にとって説明します:
さて、北斎が亀の画像に波の質感やスタイルを加えることにしたら、どのように見えるだろうか。 こんな感じでしょうか。
これは魔法か単なる深層学習か? 幸い、これには魔法は関係ありません。スタイル転送は、ニューラルネットワークの能力と内部表現を示す、楽しくて興味深い手法です。
ニューラル スタイル転送の原理は、2 つの距離関数、2 つの画像のコンテンツがどれだけ異なるかを記述する Lcontent と、2 つの画像のスタイルの違いを記述する Lstyle を定義することにあります。 そして、希望するスタイル画像、希望するコンテンツ画像、入力画像(コンテンツ画像で初期化)の3つの画像が与えられたとき、コンテンツ画像とのコンテンツ距離とスタイル画像とのスタイル距離を最小にするように入力画像を変換しようとします。
まとめると、基本となる入力画像、マッチしたいコンテンツ画像、マッチしたいスタイル画像を取ります。 バックプロパゲーションでコンテンツとスタイルの距離(損失)を最小化してベース入力画像を変換し、コンテンツ画像のコンテンツとスタイル画像のスタイルを一致させる画像を作成することになります。
その過程で、以下の概念について実践的な経験を積み、直感を養っていきます。
- Eager Execution – 操作をすぐに評価するTensorFlowの命令型プログラミング環境を使う
- Eager Executionについてもっと学ぶ
- 実際に見る(多くのチュートリアルはColaboratoryで実行できる)
- Using Functional API to define a model – モデルのサブセットを構築して、必要とされる Functional APIを用いた中間活性化
- Leveraging feature maps of a pretrained model – Prerained models and their feature mapsの使用方法を学びます
- Create custom training loops – 入力パラメータに関して与えられた損失を最小化するための最適化の設定方法を検討します
Style transferを実行する一般的なステップに従って、スタイル転送を実行します。
- Visualize data
- Basic Preprocessing/preparing our data
- Set up loss functions
- Create model
- Optimize for loss function
Audience.Of.Pirates
Basic Preprocessing/preparing our data
- Gatysの論文を読む – 途中で説明しますが、論文を読むとタスクについてより深く理解できます
- 勾配降下を理解する
推定される時間。 60 min
Code:
この記事の完全なコードは、このリンクで見つけることができます。 5077>
実装
私たちはまず、イーガー実行を有効にします。 5077>

Define content and style representations
画像のコンテンツとスタイル表現の両方を取得するために、モデル内のいくつかの中間層を見ていきましょう。 中間層は、奥に行くほど高順位になる特徴マップを表します。 今回は、事前に学習した画像分類ネットワークであるVGG19というネットワークアーキテクチャを使用します。 これらの中間層は、画像からコンテンツとスタイルの表現を定義するのに必要である。 5077>
Why intermediate layers?
なぜ事前学習された画像分類ネットワーク内のこれらの中間出力が、スタイルとコンテンツの表現を定義できるのか不思議に思っているかもしれません。 高レベルでは、この現象は、ネットワークが画像分類を実行するために (私たちのネットワークはこれを行うように訓練されています)、画像を理解しなければならないという事実によって説明することができます。 これは、生の画像を入力ピクセルとして受け取り、生の画像ピクセルを画像内に存在する特徴の複雑な理解に変える変換を通じて、内部表現を構築することを意味します。 これは、畳み込みニューラルネットワークがうまく一般化できる理由の一部でもあります。畳み込みニューラルネットワークは、背景のノイズやその他の厄介なものに左右されないクラス(猫と犬など)内の不変性と定義的特徴を捉えることができるのです。 したがって、中間層にアクセスすることにより、入力画像のコンテンツとスタイルを記述することができます。
具体的には、ネットワークからこれらの中間層を取り出します。 これにより、コンテンツ、スタイル、および生成された画像の特徴マップ(およびそれに続くコンテンツとスタイルの表現)を抽出することができる。
論文で提案されているように、我々はVGG19を使う。 さらに、VGG19は比較的単純なモデルであるため(ResNet、Inceptionなどと比較して)、特徴マップは実際にスタイル転送によく機能する。
我々のスタイルおよびコンテンツ特徴マップに対応する中間層にアクセスするために、Keras Functional APIを用いて、所望の出力活性化を持つ我々のモデルを定義して対応する出力を取得する。 model = Model(inputs, outputs).
上記のコード スニペットでは、事前に学習したイメージ分類ネットワークをロードします。 そして、先ほど定義したように、関心のあるレイヤーを取得します。 次に、モデルの入力を画像に、出力をスタイル レイヤーとコンテンツ レイヤーの出力に設定することで、モデルを定義します。 言い換えれば、入力画像を受け取り、コンテンツとスタイルの中間層を出力するモデルを作成しました!
損失関数(コンテンツとスタイルの距離)の定義と作成
コンテンツ損失の定義は実際には非常にシンプルです。 私たちはネットワークに、希望するコンテンツ画像と基本入力画像の両方を渡します。 これは、我々のモデルから中間層の出力 (上記で定義された層から) を返します。
より正式には、コンテンツ ロスとは、入力画像 x とコンテンツ画像 p からのコンテンツの距離を記述する関数です。 Cₙₙを事前に訓練された深い畳み込みニューラルネットワークとする。 ここでもVGG19を使用します。 Fˡᵢⱼ(x)∈Cₙₙ(x) and Pˡᵢⱼ(x) ∈Cₙₙ(x) は層lで入力xとpのネットワークのそれぞれの中間特徴表現について記述するものとする。 5077>
この内容損失を最小にするように、通常の方法でバックプロパゲーションを実行する。 このように、ある層 (content_layer で定義) で元のコンテンツ画像と同様のレスポンスを生成するまで、初期画像を変更するのです。 この場合も、入力画像である x とコンテンツ画像である p から供給されるネットワーク内の層 L で特徴マップを入力として受け取り、コンテンツ距離を返します。
Style Loss:
スタイル損失の計算は少し複雑ですが、同じ原理に従い、今回はネットワークに基本入力画像とスタイル画像を送ります。 しかし、ベース入力イメージとスタイル イメージの生の中間出力を比較する代わりに、2 つの出力のグラム行列を比較します。
数学的には、ベース入力イメージ x とスタイル イメージ a のスタイル損失は、これらのイメージのスタイル表現 (グラム行列) 間の距離として記述されます。 画像のスタイル表現を、グラム行列Gˡで与えられる異なるフィルタ応答間の相関として記述する。ここで、Gˡᵢⱼは層lのベクトル化特徴マップiとjの間の内積である。 与えられた画像の特徴マップ上で生成されたGˡᵢⱼは、特徴マップiとjの間の相関を表すことがわかる。
ベース入力画像のスタイルを生成するには、コンテンツ画像から勾配降下を行い、元画像のスタイル表現にマッチする画像に変換します。 これは、スタイル画像と入力画像の特徴相関マップの間の平均二乗距離を最小化することにより行う。 総スタイル損失に対する各層の寄与は、
ここでGˡᵢⱼとAˡᵢⱼは入力画像xおよびスタイル画像aの層lにおけるそれぞれのスタイル表現であると記述している。 Nlは特徴マップの数を表し、それぞれの大きさはMl=height*widthである。 したがって、各層にわたる総スタイル損失は、
ここで、ある係数wlで各層の損失の寄与を重み付けする。 5077>
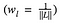
これは簡単に実装されます。
Run Gradient Descent
Gradient Descent/backpropagation に慣れていない場合や復習が必要な場合は、ぜひこのリソースをチェックしてみてください。
このケースでは、損失を最小限に抑えるために Adam オプティマイザーを使用します。 私たちのネットワークに関連する重みを更新するのではなく、損失を最小化するために入力画像を訓練します。 このためには、損失と勾配の計算方法を知っておく必要がある。 L-BFGSオプティマイザは、このアルゴリズムに精通している方にはお勧めですが、このチュートリアルの主な動機は、イーガー実行のベストプラクティスを説明することでしたので、このチュートリアルでは使用しないことに注意してください。 Adam を使用することにより、カスタム トレーニング ループでオートグラッド/グラディエント テープ機能を実証できます。
損失と勾配の計算
コンテンツとスタイル画像をロードし、ネットワークを通してそれらを転送し、モデルからコンテンツとスタイルの特徴表現を出力する小さなヘルパー関数を定義します。 これは、後で勾配を計算するために、操作をトレースすることによって利用可能な自動微分を利用することができます。
では、勾配の計算は簡単です:
Apply and run the style transfer process
そして実際にスタイル転送を実行する:
And that is it it !
それでは、亀の画像と北斎の「神奈川沖の大波」で実行してみましょう。

Watch the iterative process over time:

The other cool examples of what neural style transfer can do here are some than the other cool examples. ぜひご覧ください。
の画像-Photo By.Pf.No: Andreas Praefcke , from Wikimedia Commons and Image of Composition 7 by Vassily Kandinsky, Public Domain
の画像 – Photo By.Kandinsky, Wikipedia: Andreas Praefcke , from Wikimedia Commons and Image of Pillars of Creation by NASA, ESA, and the Hubble Heritage Team, Public Domain
Try you own images!
What we covered:
- We built several different loss functions and used backpropagation to transform our input image in order to minimize these losses.
- In order we loaded in a pretrained model and use its learned feature maps to describe the content and style representation of our images.
- This for making it, we loaded in a prerained model and using its learned feature maps to describe the content and style representation of our images.
- What is you do you know the loss function?
- 私たちの主な損失関数は、主にこれらの異なる表現の観点から距離を計算することでした。
- 私たちはこれをカスタム モデルとイーガー実行で実装しました。
- カスタムモデルを Functional API で構築しました。
- イーガー実行により、自然な Python 制御フローを使用して、テンソルを動的に操作することができます。
- 私たちはテンソルを直接操作することで、デバッグやテンソルでの作業を容易にしました。
私たちは tf.gradient を使用して最適化装置の更新ルールを適用し、画像を繰り返し更新しました。 オプティマイザーは入力画像に対して与えられた損失を最小化しました。