長年にわたり、多くの人が私の名前の綴りに悩んできました。 若い頃、私は彼らが “Colin “という名前を聞いたことがないと思っていました。 私が住んでいたところでは、それはかなり珍しいことでした。 この20年間で、この名前はよりポピュラーになりましたが、スペルのトラブルは改善されていません。 最近では、別のスペルも問題になっているようだ。 コリン “は “コリン “と同じくらい一般的な名前なのだろうか?
幸運にも、社会保障庁は生年月日によるファーストネームを記録しており、このデータを自由に利用できるので、その疑問に答えることができました。
その結果、「コリン」は今世紀に入る頃に人気が急上昇し、一瞬、(もちろん、正しい)「コリン」を追い越しました。 1940年には、この2つの名前の約85%が1つの “l “を使っており、それは70年代後半まで続きました。”l “が2つあるタイプは急速に普及し、1999年頃に一時的に “l “が1つのタイプを上回り、その後はずっと下降線をたどっています。
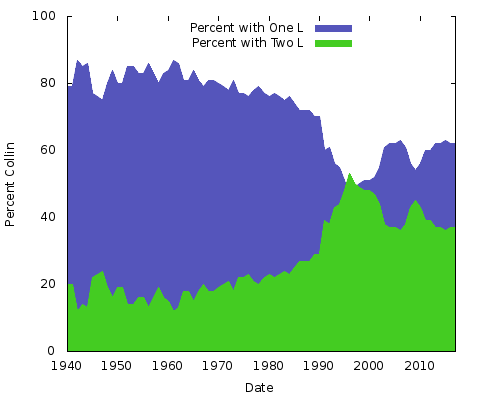
これが何を意味しているのでしょうか。 私には見当もつかない。 どんな理由であれ、他のペアの名前の綴りでは異なるでしょう。 Eric」対「Erik」、「Rachel」対「Rachael」などでも同じことができるはずです。 実際に、この2つをやってみましょう。
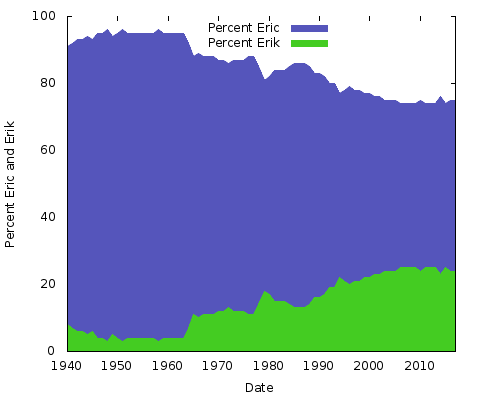
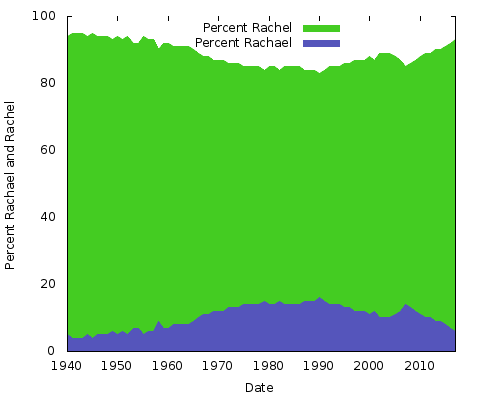
これは単純な面積表です。 この目的のために、私は積み上げられた面積グラフよりもこれを好みます。2 つの Y 軸の値の合計が常に 100% になる 2 つの線だけでは、同じ下の線と上半分が無地になるだけです。 この方法では、2 つの綴りの人気の大きな変化をよりよく理解できます。
積上げ面積グラフは、2 つ以上の名前の傾向を示すのに最適です。 たとえば、上記のようなチャートを使用して、1 つの名前だけで、名前に関連する性別の経時変化を示すことができますが、1 つの画像を使用して、複数の名前を重ねて同じ情報を伝達することができます。
Social Security Baby Name Data
このデータは、SSA の Web サイトから得たもので、SSA は、出生年ごとに最も人気のある赤ちゃんの名前トップ 1000 を公開します。 1940年以前は、30年代に行政が設立されたばかりなので、データはかなりまばらです。 1880年まではまだ入手可能ですが、30年代以降に登録された人たちだけが含まれているので、数は少なくなっています。 .zip アーカイブで、生まれた年ごとに別々のファイルになっており、米国の州ごとに分割されたバージョンもあります。
データは以下のようになります。
単年度のファイルを 1 つにまとめ、おそらく「生年」 (YOB) 列を追加して、時間関連のグラフ作成に使いやすくしたいと思うことでしょう。 私はこの作業を行う小さな Ruby スクリプトを書きました。
グラフ作成パッケージにデータを供給するには、おそらくデータをさらにマッサージする必要があるでしょう。 単一の名前を持つ行を、グラフ化したいすべてのデータ ポイントの列を持つ行に変換する必要があります。 これらは 1 つのファイルか、あるいはグラフの 1 行に 1 つのファイルかもしれません (Gnuplot ではそのようにして複数のファイルを 1 つのグラフに読み込むことができます)。 これは Ruby か Python でできます。 私は SQL と “Q Text-as-Data” ツールを使ってこれを行い、その結果を Gnuplot に送りました
。