This post, we will learn web scraping using python.It is gonna be connected to use Python.It is gonna be connected. pythonを使用して、Yahooファイナンスをスクレイピングするつもりです。 これは、株式市場のデータのための素晴らしいソースです。 私たちはそのためのスクレイパーをコード化する予定です。 そのスクレイパーを使えば、ヤフーファイナンスからあらゆる会社の株式データをスクレイピングすることができるようになります。 ご存知のように、私は物事をかなり単純化するのが好きなので、そのために、スクレイピングの効率を高める Web スクレイパーも使用します。 このツールは、私たちがブロックされないように回転プロキシの何百万人を使用して動的なウェブサイトをスクレイピングするのに役立ちます。 また、クリアリング機能を提供します。
一般に、Web スクレイピングは 2 つの部分に分けられます。
- HTTP リクエストを行うことでデータを取得する。
- HTML DOM を解析することで重要データを取り出す。
ライブラリ & ツール
- Beautiful Soup は HTML と XML ファイルからデータを抽出する Python のライブラリである。
- Requests では、HTTP リクエストを非常に簡単に送信できます。
- Web スクレイピング ツールでは、ターゲット URL の HTML コードを抽出します。
Setup
設定は非常にシンプルです。 フォルダを作成し、Beautiful Soup & のリクエストをインストールするだけです。 フォルダの作成とライブラリのインストールは、以下のコマンドを入力します。 Python 3.x はすでにインストールされていると仮定します。
mkdir scraper
pip install beautifulsoup4
pip install requests
次に、そのフォルダーの中に好きな名前でファイルを作成します。 私はscraping.pyを使用しています。
まず、あなたはscrapingdog APIにサインアップする必要があります。 それはあなたに1000の無料クレジットを提供します。 そして、あなたのファイルにビューティフルスープ & リクエストをインポートしてください。
from bs4 import BeautifulSoup
import requests
スクレイピングするもの
抽出するフィールドのリストはこちらです。
- Previous Close
- Open
- Bid
- Ask
- 52 Week Range
- Volume
- Avg.Local
- Open
- Bid
- Ask
- Day”s Range
- Market Cap
- Beta
- PE Ratio
- EPS
- Earnings Rate
- Forward Dividend & Yield
- Ex-Competitive
- 1y target EST
。配当金 & Date
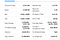
Preparing the Food
さて、次は、料理の準備である。 スクレイパーを準備するためのすべての材料が揃ったので、生の HTML データを取得するためにターゲット URL に GET リクエストを実行しましょう。 もしスクレイピング・ツールに慣れていないなら、そのドキュメントに目を通すことを強くお勧めする。
r = requests.get("https://api.scrapingdog.com/scrape?api_key=<your-api-key>&url=https://finance.yahoo.com/quote/AMZN?p=AMZN&.tsrc=fin-srch").text
これにより、ターゲット URL の HTML コードが提供されます。
次に、BeautifulSoup を使用して HTML を解析します。
soup = BeautifulSoup(r,'html.parser')
さて、ページ全体には、4 つの「tbody」タグがあります。 最初の2つに興味があるのは、3番目&4番目の「tbody」タグの中で利用できるデータは現在必要ないからです。
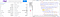
ウェブサイト上のtbodyタグ
最初に、変数「スープ」を使ってこれらのすべての「tbody」タグを見つけてみます。
alldata = soup.find_all("tbody")

最初の二つの「tbody」には8つの「tr」タグがあって、それぞれの「tr」タグには「td」タグが二つあることに気がつくと思うのですが、「tbody」内の「tdタグ」は「trタグ」と同じものです。
try:
table1 = alldata.find_all("tr")
except:
table1=Nonetry:
table2 = alldata.find_all("tr")
except:
table2 = None
さて、それぞれの「tr」タグは2つの「td」タグを持っています。 最初のtdタグはプロパティの名前からなり、もう一つのtdタグはそのプロパティの値を持っている。

この時点で、リストと辞書を宣言してから for ループを開始します。
l={}
u=list()
コードを簡単にするため、それぞれのテーブルに対して2種類の for を実行することにします。 まず「table1」に対して
for i in range(0,len(table1)):
try:
table1_td = table1.find_all("td")
except:
table1_td = None l.text] = table1_td.text u.append(l)
l={}
ここで行ったことは、すべてのtdタグを「table1_td」という変数に格納することです。 そして、最初の&番目のtdタグの値を「dictionary」に格納しています。 そして、辞書をリストにプッシュしています。 重複したデータを保存したくないので、最後にdictionaryを空にしています。 同様の手順を「table2」でも行います。
for i in range(0,len(table2)):
try:
table2_td = table2.find_all("td")
except:
table2_td = None l.text] = table2_td.text u.append(l)
l={}
そして最後にリスト「u」を出力すると、JSONレスポンスが得られます。
{
"Yahoo finance":
}
すごいと思いませんか。 わずか 5 分のセットアップで Yahoo ファイナンスをスクレイピングすることに成功しました。 Amazonという会社の財務データを含むpythonオブジェクトの配列を持っています。 このようにして、あらゆる Web サイトからデータをスクレイピングできます。
結論
この記事では、データ スクレイピング ツール & BeautifulSoup を使用して、Web サイトの種類に関係なくデータをスクレイピングできる方法を理解しました。 TwitterとMediumでフォローできます。 読んでくれてありがとう、そしていいね!ボタンを押してください。 👍
Additional Resources
そして、これがリストです! この時点で、任意の Web サイトからデータを収集するための最初の Web スクレイパーを快適に書くことができると感じているはずです。 以下は、Web スクレイピングの旅で役に立つかもしれないいくつかの追加リソースです:
- List of web scraping proxy services
- List of handy web scraping tools
- BeautifulSoup documentation
- Scrapingdog documentation
- Guide to web scraping