In de loop der jaren hebben veel mensen moeite gehad mijn naam te spellen. Toen ik jonger was, nam ik aan dat ze de naam “Colin” niet kenden. Het was vrij ongebruikelijk waar ik woonde. De afgelopen twintig jaar is de naam populairder geworden, maar de spellingsproblemen zijn er niet beter op geworden. Het blijkt dat er tegenwoordig nog een ander probleem is: een alternatieve spelling. Zou “Collin” echt zo gewoon zijn als “Colin”? Ik geloofde het niet.
Gelukkig houdt de Social Security Administration voornamen bij op geboortedatum en zij stellen deze gegevens vrij beschikbaar, zodat ik die vraag kon beantwoorden.
Het bleek dat “Collin” rond de eeuwwisseling een dramatische sprong in populariteit doormaakte en even het (correcte, natuurlijk) “Colin” overschaduwde.”
De grafiek toont de relatieve populariteit van “Colin” versus “Collin” voor mensen geboren sinds 1940. In 1940 gebruikte ongeveer 85 procent van de twee namen één “l” en dat bleef zo tot het eind van de jaren zeventig; de variant met twee “l-en” nam snel een hoge vlucht en overtrof rond 1999 kortstondig de versie met één “l”, om sindsdien steeds verder af te zakken.
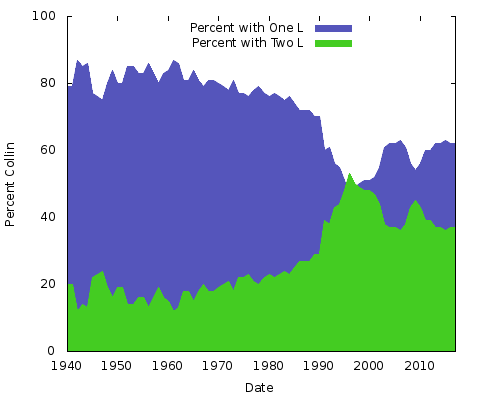
Wat betekent dit allemaal? Ik heb geen idee. Wat de redenen ook zijn, ze zullen anders zijn voor andere spellingsparen van namen. Je zou hetzelfde kunnen doen voor “Eric” vs. “Erik” of “Rachel” vs. “Rachael” en vele anderen. Eigenlijk, laten we die twee doen:
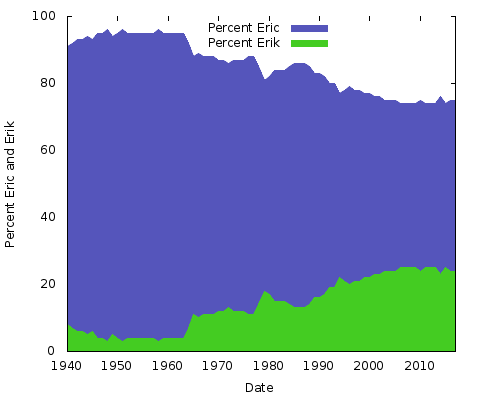
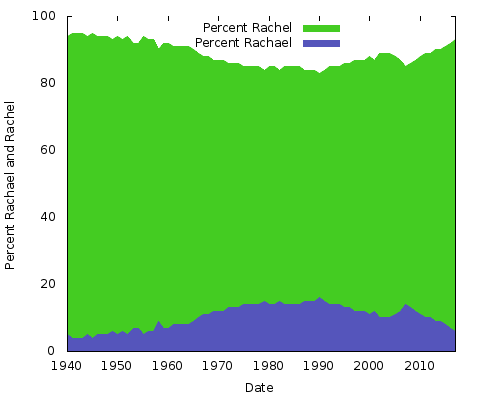
Dit zijn eenvoudige gebiedstabellen. Voor dit doel geef ik de voorkeur aan een gestapelde oppervlaktegrafiek; met slechts twee lijnen, waarbij de som van de twee Y-as waarden altijd 100% is, zou je gewoon eindigen met dezelfde onderste lijn en de bovenste helft een effen kleur. Op deze manier krijg je een beter idee van de grote verandering in populariteit van de twee schrijfwijzen.
Een gestapelde gebiedsgrafiek zou geweldig zijn om trends van meer dan twee namen te laten zien: Je zou bijvoorbeeld verandering in geslacht geassocieerd met namen in de tijd kunnen laten zien met slechts één naam met behulp van een grafiek zoals hierboven, maar met behulp van één afbeelding zou je meerdere namen kunnen stapelen en dezelfde informatie overbrengen:
Social Security Baby Name Data
De gegevens komen van de SSA-website waar ze de top 1000 van populairste babynamen openbaar maken voor elk geboortejaar in hun bestanden. Vóór 1940 zijn de gegevens nogal schaars, omdat de administratie pas in de jaren dertig werd opgezet. U kunt nog steeds namen krijgen die teruggaan tot 1880, maar het zijn er minder omdat alleen mensen die zich in de jaren dertig en later hebben ingeschreven, zijn opgenomen.
Krijg de gegevens op deze SSA-pagina. Het komt in een .zip-archief met afzonderlijke bestanden voor elk geboortejaar, en er is een versie van de gegevens uitgesplitst naar Amerikaanse staten.
De gegevens zien er als
Linda,F,99686Mary,F,71688Patricia,F,51278Barbara,F,48791Sandra,F,34774Carol,F,33538Nancy,F,32442Dit is van de top van het bestand 1947.
Je zult de bestanden met één jaar willen combineren tot één en waarschijnlijk een kolom “Geboortejaar” (YOB) toevoegen om het gebruik ervan voor tijdgerelateerde grafieken te vergemakkelijken. Ik heb een klein Ruby script geschreven om dit te doen.
Om de gegevens aan een grafiekpakket te voeden, moet je de gegevens waarschijnlijk nog wat meer masseren: Je moet de rijen met een enkele naam omzetten in rijen met kolommen voor alle datapunten die je in een grafiek wilt zetten. Deze kunnen in één bestand staan of één bestand per regel in de grafiek (met Gnuplot kun je op die manier werken, door meerdere bestanden in één grafiek te laden). Je zou dit met Ruby of Python kunnen doen. Ik deed het met SQL en de “Q Text-as-Data” tool, en voerde het resultaat vervolgens naar Gnuplot.