In dit bericht gaan we leren web scraping met python. Met behulp van python gaan we Yahoo Finance scrapen. Dit is een geweldige bron voor beursgegevens. We zullen daar een scraper voor coderen. Met behulp van die scraper zou je in staat zijn om gegevens over aandelen van elk bedrijf van Yahoo Finance te scrapen. Zoals je weet hou ik ervan om dingen eenvoudig te maken, daarom zal ik ook een web scraper gebruiken die je efficiëntie zal verhogen.
Waarom deze tool? Deze tool zal ons helpen om dynamische websites te scrapen met behulp van miljoenen roterende proxies, zodat we niet geblokkeerd worden. Het biedt ook een clearing-faciliteit. Het maakt gebruik van headerless chrome om dynamische websites te scrapen.
In het algemeen, web scraping is verdeeld in twee delen:
- Halen van gegevens door het maken van een HTTP-verzoek
- Extractie van belangrijke gegevens door het parseren van de HTML DOM
Bibliotheken & Tools
- Beautiful Soup is een Python-bibliotheek voor het trekken van gegevens uit HTML-en XML-bestanden.
- Met Requests kunt u heel eenvoudig HTTP-verzoeken versturen.
- web scraping tool om de HTML-code van de doel-URL te extraheren.
Setup
Onze setup is vrij eenvoudig. Maak gewoon een map aan en installeer Beautiful Soup & aanvragen. Om een map aan te maken en bibliotheken te installeren, typ de onderstaande commando’s. Ik ga ervan uit dat je Python 3.x al hebt geïnstalleerd.
mkdir scraper
pip install beautifulsoup4
pip install requests
Nu, maak een bestand in die map met een naam die je wilt. Ik gebruik scraping.py.
Ten eerste, moet je je aanmelden voor de scrapingdog API. Je krijgt dan 1000 GRATIS credits. Dan importeer je gewoon Beautiful Soup & verzoeken in je bestand. Zoals dit.
from bs4 import BeautifulSoup
import requests
Wat we gaan scrapen
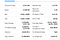
Hier is de lijst met velden die we gaan extraheren:
- Vorige Close
- Open
- Bid
- Ask
- Day’s Range
- 52 Week Range
- Volume
- Avg. Volume
- Marketcap
- Beta
- PE Ratio
- EPS
- Earnings Rate
- Forward Dividend & Yield
- Ex-Dividend & Date
- 1y target EST
Prearing the Food
Nu, nu we alle ingrediënten hebben om de scraper voor te bereiden, moeten we een GET-aanvraag doen bij de doel-URL om de ruwe HTML-gegevens te krijgen. Als je niet bekend bent met de scraping tool, zou ik je dringend aanraden om de documentatie door te nemen. Nu gaan we Yahoo Finance scrapen voor financiële gegevens met behulp van de requests library zoals hieronder te zien is.
r = requests.get("https://api.scrapingdog.com/scrape?api_key=<your-api-key>&url=https://finance.yahoo.com/quote/AMZN?p=AMZN&.tsrc=fin-srch").text
Dit levert u een HTML code op van die doel URL.
Nu moet u BeautifulSoup gebruiken om de HTML te parseren.
soup = BeautifulSoup(r,'html.parser')
Nu, op de hele pagina, hebben we vier “tbody” tags. We zijn geïnteresseerd in de eerste twee omdat we op dit moment niet de gegevens nodig hebben die beschikbaar zijn binnen de derde & vierde “tbody” tags.
Eerst zullen we al die “tbody” tags te weten komen met behulp van variabele “soup”.
alldata = soup.find_all("tbody")

Zoals u kunt zien, heeft de eerste twee “tbody” 8 “tr”-tags en elke “tr”-tag heeft twee “td”-tags.
try:
table1 = alldata.find_all("tr")
except:
table1=Nonetry:
table2 = alldata.find_all("tr")
except:
table2 = None
Nu heeft elke “tr”-tag twee “td”-tags. De eerste td tag bestaat uit de naam van de eigenschap en de andere heeft de waarde van die eigenschap. Het is zoiets als een sleutel-waardepaar.

Op dit punt gaan we een lijst en een woordenboek declareren voordat we een for-lus starten.
l={}
u=list()
Om de code eenvoudig te houden zal ik voor elke tabel twee verschillende “for”-lussen laten lopen. Eerst voor “table1”
for i in range(0,len(table1)):
try:
table1_td = table1.find_all("td")
except:
table1_td = None l.text] = table1_td.text u.append(l)
l={}
Nu, wat we hebben gedaan is dat we alle td tags in een variabele “table1_td” hebben opgeslagen. En dan slaan we de waarde van de eerste & tweede td tag op in een “dictionary”. Daarna duwen we het woordenboek in een lijst. Omdat we geen dubbele gegevens willen opslaan, maken we de dictionary aan het eind leeg. Vergelijkbare stappen zullen worden gevolgd voor “table2”.
for i in range(0,len(table2)):
try:
table2_td = table2.find_all("td")
except:
table2_td = None l.text] = table2_td.text u.append(l)
l={}
Als je dan aan het eind de lijst “u” afdrukt, krijg je een JSON response.
{
"Yahoo finance":
}
Is dat niet geweldig. Het is ons gelukt om Yahoo Finance te scrapen in slechts 5 minuten. We hebben een array van Python Objecten met de financiële gegevens van het bedrijf Amazon. Op deze manier kunnen we de gegevens van elke website scrapen.
Conclusie
In dit artikel hebben we begrepen hoe we gegevens kunnen scrapen met behulp van data scraping tool & BeautifulSoup, ongeacht het type website.
Voel je vrij om commentaar te geven en me iets te vragen. U kunt mij volgen op Twitter en Medium. Bedankt voor het lezen en druk op de like knop! 👍
Aanvullende bronnen
En daar is de lijst! Op dit punt zou je je op je gemak moeten voelen met het schrijven van je eerste web scraper om gegevens van een website te verzamelen. Hier zijn een paar extra bronnen die u misschien nuttig vindt tijdens uw web scraping reis:
- Lijst van web scraping proxy diensten
- Lijst van handige web scraping tools
- BeautifulSoup Documentatie
- Scrapingdog Documentatie
- Gids voor web scraping