Door Raymond Yuan, Software Engineering Intern
In deze tutorial leren we hoe we deep learning kunnen gebruiken om afbeeldingen samen te stellen in de stijl van een andere afbeelding (ooit gewenst dat je kon schilderen als Picasso of Van Gogh?). Dit staat bekend als neurale stijloverdracht! Dit is een techniek die wordt beschreven in Leon A. Gatys’ paper, A Neural Algorithm of Artistic Style, dat geweldig is om te lezen, en je zou het zeker moeten bekijken.
Neural style transfer is een optimalisatietechniek die wordt gebruikt om drie afbeeldingen te nemen, een inhoudsafbeelding, een stijlreferentieafbeelding (zoals een kunstwerk van een beroemde schilder), en de invoerafbeelding die je wilt stijlen – en meng ze zodanig dat de invoerafbeelding wordt getransformeerd om eruit te zien als de inhoudsafbeelding, maar “geschilderd” in de stijl van de stijlafbeelding.
Nemen we bijvoorbeeld een afbeelding van deze schildpad en Katsushika Hokusai’s De grote golf bij Kanagawa:
Nu, hoe zou het eruit zien als Hokusai zou besluiten de textuur of stijl van zijn golven toe te voegen aan de afbeelding van de schildpad? Zoiets als dit?
Is dit magie of gewoon deep learning? Gelukkig komt hier geen magie aan te pas: stijloverdracht is een leuke en interessante techniek die de mogelijkheden en interne representaties van neurale netwerken laat zien.
Het principe van neurale stijloverdracht is om twee afstandsfuncties te definiëren, een die beschrijft hoe verschillend de inhoud van twee afbeeldingen is, Lcontent, en een die het verschil tussen de twee afbeeldingen beschrijft in termen van hun stijl, Lstyle. Dan, gegeven drie beelden, een gewenst stijlbeeld, een gewenst inhoudsbeeld, en het invoerbeeld (geïnitialiseerd met het inhoudsbeeld), proberen we het invoerbeeld te transformeren om de inhoudsafstand met het inhoudsbeeld en de stijlafstand met het stijlbeeld te minimaliseren.
In het kort, we nemen het basis invoerbeeld, een inhoudsbeeld dat we willen matchen, en het stijlbeeld dat we willen matchen. We transformeren het basis invoerbeeld door de inhoud en stijl afstanden (verliezen) te minimaliseren met backpropagation, waardoor een beeld ontstaat dat overeenkomt met de inhoud van het inhoudsbeeld en de stijl van het stijlbeeld.
In het proces, zullen we praktische ervaring opbouwen en intuïtie ontwikkelen rond de volgende concepten:
- Eager Execution – gebruik TensorFlow’s imperatieve programmeeromgeving die operaties onmiddellijk evalueert
- Leer meer over eager execution
- Zie het in actie (veel van de tutorials zijn runnable in Colaboratory)
- Functionele API gebruiken om een model te definiëren – we zullen een subset van ons model bouwen dat ons toegang geeft tot de nodige tussenliggende activeringen met behulp van de Functional API
- Gebruik maken van feature maps van een vooraf getraind model – leren hoe we vooraf getrainde modellen en hun feature maps kunnen gebruiken
- Aangepaste trainingslussen maken – we zullen onderzoeken hoe we een optimizer kunnen instellen om een bepaald verlies ten opzichte van invoerparameters te minimaliseren
- We zullen de algemene stappen volgen om stijloverdracht uit te voeren:
- Code:
- Uitvoering
- Definieer inhoud en stijl representaties
- Waarom tussenlagen?
- Model
- Definieer en maak onze verliesfuncties (inhoud en stijl afstanden)
- Stijlverlies:
- Run Gradient Descent
- Bereken het verlies en de gradiënten
- Toepassen en uitvoeren van het stijloverdrachtproces
- Wat we hebben behandeld:
We zullen de algemene stappen volgen om stijloverdracht uit te voeren:
- Visualiseer data
- Basis voorbewerken/voorbereiden van onze data
- Verliesfuncties instellen
- Model maken
- Optimaliseer voor verliesfunctie
Doelgroep: Deze post is gericht op gemiddelde gebruikers die vertrouwd zijn met basisconcepten van machinaal leren. Om het meeste uit deze post te halen, moet u:
- Gatys paper lezen – we leggen het onderweg uit, maar het paper zal een grondiger begrip van de taak geven
- Gradiëntafdaling begrijpen
Tijd Geschat: 60 min
Code:
De volledige code voor dit artikel vindt u op deze link. Als u door dit voorbeeld wilt stappen, kunt u de colab hier vinden.
Uitvoering
We beginnen met het inschakelen van eager execution. Eager execution stelt ons in staat om deze techniek op de duidelijkste en meest leesbare manier door te werken.

Definieer inhoud en stijl representaties
Om zowel de inhoud als de stijl representaties van onze afbeelding te krijgen, zullen we kijken naar enkele tussenlagen binnen ons model. Tussenlagen zijn kaarten met kenmerken die steeds hoger gerangschikt worden naarmate je dieper gaat. In dit geval gebruiken we de netwerkarchitectuur VGG19, een vooraf getraind netwerk voor beeldclassificatie. Deze tussenlagen zijn nodig om de weergave van inhoud en stijl van onze beelden te definiëren. Voor een ingevoerd beeld zullen we proberen de overeenkomstige stijl- en inhoudsdoelrepresentaties in deze tussenlagen te matchen.
Waarom tussenlagen?
Je vraagt je misschien af waarom deze tussenuitgangen binnen ons voorgetrainde beeldclassificatienetwerk ons in staat stellen stijl- en inhoudsrepresentaties te definiëren. Op een hoog niveau kan dit fenomeen worden verklaard door het feit dat om een netwerk beeldclassificatie te laten uitvoeren (waartoe ons netwerk is opgeleid), het het beeld moet begrijpen. Dit houdt in dat het ruwe beeld als inputpixels moet worden genomen en dat een interne representatie moet worden opgebouwd door middel van transformaties die de ruwe beeldpixels omzetten in een complex begrip van de kenmerken die in het beeld aanwezig zijn. Dit is ook deels de reden waarom convolutionele neurale netwerken goed kunnen generaliseren: zij zijn in staat om de invarianties en definiërende kenmerken binnen klassen te vangen (b.v. katten vs. honden) die agnostisch zijn voor achtergrondruis en andere ongemakken. Ergens tussen de invoer van het ruwe beeld en de uitvoer van het classificatielabel fungeert het model dus als een complexe functie-extractor; door toegang te krijgen tot tussenliggende lagen kunnen we de inhoud en stijl van invoerbeelden beschrijven.
Specifiek halen we deze tussenliggende lagen uit ons netwerk:
Model
In dit geval laden we VGG19, en voeren we onze invoertensor in het model in. Dit stelt ons in staat om de feature maps (en vervolgens de inhoud en stijl representaties) van de inhoud, stijl, en gegenereerde beelden te extraheren.
We gebruiken VGG19, zoals voorgesteld in de paper. Bovendien, omdat VGG19 een relatief eenvoudig model is (vergeleken met ResNet, Inception, enz.) werken de feature maps eigenlijk beter voor stijloverdracht.
Om toegang te krijgen tot de tussenlagen die overeenkomen met onze stijl- en inhoudsfeature maps, krijgen we de bijbehorende uitgangen door de Keras Functional API te gebruiken om ons model met de gewenste uitvoeractivaties te definiëren.
Met de Functional API bestaat het definiëren van een model eenvoudigweg uit het definiëren van de invoer en uitvoer: model = Model(inputs, outputs).
In het bovenstaande codefragment laden we ons vooraf getrainde netwerk voor beeldclassificatie. Dan pakken we de interessante lagen zoals we die eerder hebben gedefinieerd. Vervolgens definiëren we een model door de invoer van het model in te stellen op een afbeelding en de uitvoer op de uitvoer van de stijl- en inhoudlagen. Met andere woorden, we hebben een model gemaakt dat een afbeelding als invoer neemt en de tussenlagen voor inhoud en stijl uitvoert!
Definieer en maak onze verliesfuncties (inhoud en stijl afstanden)
Onze inhoud verlies definitie is eigenlijk heel eenvoudig. We geven het netwerk zowel de gewenste inhoudsafbeelding als onze basisinvoerafbeelding. Dit zal de outputs van de tussenliggende lagen (van de hierboven gedefinieerde lagen) van ons model teruggeven. Vervolgens nemen we eenvoudigweg de euclidische afstand tussen de twee tussenliggende representaties van die beelden.
Meer formeel is inhoudsverlies een functie die de afstand beschrijft van de inhoud van ons invoerbeeld x en ons inhoudsbeeld, p . Laat Cₙₙ een voorgetraind diep convolutioneel neuraal netwerk zijn. Ook in dit geval gebruiken we VGG19. Laat X een afbeelding zijn, dan is Cₙₙ(x) het netwerk dat gevoed wordt door X. Laat Fˡᵢⱼ(x)∈ Cₙₙ(x)en Pˡᵢⱼ(x) ∈ Cₙₙ(x) de respectieve tussenliggende kenmerkrepresentatie beschrijven van het netwerk met de ingangen x en p in laag l . Vervolgens beschrijven we de inhoudsafstand (verlies) formeel als:
We voeren backpropagatie uit op de gebruikelijke manier zodat we dit inhoudsverlies minimaliseren. We veranderen dus het oorspronkelijke beeld totdat het in een bepaalde laag (gedefinieerd in content_layer) een vergelijkbare respons genereert als het oorspronkelijke inhoudsbeeld.
Dit kan vrij eenvoudig worden geïmplementeerd. Ook hier neemt het als invoer de feature maps in een laag L in een netwerk gevoed door x, onze invoerafbeelding, en p, onze inhoudsafbeelding, en retourneert de inhoudsafstand.
Stijlverlies:
Het berekenen van stijlverlies is iets ingewikkelder, maar volgt hetzelfde principe, dit keer voeden we ons netwerk met de basisinvoerafbeelding en de stijlafbeelding. Echter, in plaats van het vergelijken van de ruwe tussenliggende outputs van het basisinvoerbeeld en het stijlbeeld, vergelijken we in plaats daarvan de Gram-matrices van de twee outputs.
Mathematisch beschrijven we het stijlverlies van het basisinvoerbeeld, x, en het stijlbeeld, a, als de afstand tussen de stijlrepresentatie (de gram-matrices) van deze beelden. We beschrijven de stijlweergave van een beeld als de correlatie tussen verschillende filterresponsen, gegeven door de Gram-matrix Gˡ, waarbij Gˡᵢⱼ het binnenproduct is tussen de gevectoriseerde kenmerkkaart i en j in laag l. We kunnen zien dat Gˡᵢⱼ gegenereerd over de feature map voor een bepaald beeld de correlatie tussen feature maps i en j vertegenwoordigt.
Om een stijl te genereren voor ons basis invoerbeeld, voeren we gradiënt afdaling uit van het inhoudsbeeld om het te transformeren in een beeld dat overeenkomt met de stijl representatie van het originele beeld. We doen dit door de gemiddelde gekwadrateerde afstand tussen de kenmerkcorrelatiekaart van het stijlbeeld en het invoerbeeld te minimaliseren. De bijdrage van elke laag aan het totale stijlverlies wordt beschreven door
waarbij Gˡᵢⱼ en Aˡᵢⱼ de respectieve stijlvoorstellingen in laag l van invoerafbeelding x en stijlafbeelding a zijn. Nl beschrijft het aantal feature maps, elk van grootte Ml=hoogte∗breedte. Het totale stijlverlies over elke laag is dus
waarbij we de bijdrage van het verlies van elke laag wegen met een factor wl. In ons geval wegen we elke laag even zwaar:
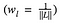
Dit wordt eenvoudig geïmplementeerd:
Run Gradient Descent
Als u niet bekend bent met gradient descent/backpropagation of een opfrisser nodig hebt, moet u zeker deze bron bekijken.
In dit geval gebruiken we de Adam optimizer om ons verlies te minimaliseren. We werken iteratief ons uitgangsbeeld zo bij, dat het ons verlies minimaliseert: we werken de gewichten van ons netwerk niet bij, maar in plaats daarvan trainen we ons ingangsbeeld om het verlies te minimaliseren. Om dit te kunnen doen, moeten we weten hoe we ons verlies en onze gradiënten berekenen. Merk op dat de L-BFGS optimizer, die als je bekend bent met dit algoritme wordt aanbevolen, maar niet wordt gebruikt in deze tutorial omdat een primaire motivatie achter deze tutorial was om best practices met eager execution te illustreren. Door Adam te gebruiken, kunnen we de autograd/gradient tape functionaliteit demonstreren met aangepaste training loops.
Bereken het verlies en de gradiënten
We zullen een kleine helper functie definiëren die onze inhoud en stijl afbeelding zal laden, ze door ons netwerk zal voeren, die vervolgens de inhoud en stijl kenmerk representaties van ons model zal uitvoeren.
Hier gebruiken we tf.GradientTape om de gradiënt te berekenen. Hiermee kunnen we gebruik maken van de automatische differentiatie die beschikbaar is door operaties te traceren om later de gradiënt te berekenen. Het registreert de bewerkingen tijdens de voorwaartse doorgang en is dan in staat om de gradiënt van onze verliesfunctie te berekenen ten opzichte van onze invoerafbeelding voor de achterwaartse doorgang.
Dan is het berekenen van de gradiënten eenvoudig:
Toepassen en uitvoeren van het stijloverdrachtproces
En om de stijloverdracht daadwerkelijk uit te voeren:
En dat is het!
Laten we het uitvoeren op onze afbeelding van de schildpad en Hokusai’s De Grote Golf bij Kanagawa:

Kijk naar het iteratieve proces in de tijd:

Hier zijn enkele andere coole voorbeelden van wat neurale stijloverdracht kan doen. Check it out!
Probeer je eigen beelden uit!
Wat we hebben behandeld:
- We hebben verschillende verliesfuncties gebouwd en backpropagation gebruikt om onze invoerafbeelding te transformeren om deze verliezen te minimaliseren.
- Om dit te doen, hebben we een vooraf getraind model geladen en de geleerde kenmerkkaarten gebruikt om de inhoud en stijlrepresentatie van onze afbeeldingen te beschrijven.
- Onze belangrijkste verliesfuncties waren voornamelijk het berekenen van de afstand in termen van deze verschillende representaties.
- We implementeerden dit met een aangepast model en eager uitvoering.
- We bouwden ons aangepaste model met de Functional API.
- Eager execution stelt ons in staat om dynamisch te werken met tensors, met behulp van een natuurlijke python-controlestroom.
- We manipuleerden tensors direct, wat het debuggen en werken met tensors makkelijker maakt.
We hebben onze afbeelding iteratief bijgewerkt door onze optimizers update regels toe te passen met tf.gradient. De optimizer minimaliseerde de gegeven verliezen ten opzichte van onze invoerafbeelding.