Z biegiem lat wiele osób miało problemy z pisownią mojego imienia. Kiedy byłem młodszy, zakładałem, że nie słyszeli imienia „Colin”. To było dość niezwykłe, gdzie mieszkałem. W ciągu ostatnich dwudziestu lat nazwa ta stała się bardziej popularna, ale kłopoty z pisownią nie poprawiły się. Okazuje się, że w dzisiejszych czasach jest jeszcze jeden problem: alternatywna pisownia. Czy „Collin” może być naprawdę tak powszechne jak „Colin”? I didn’t believe it.
Luckily the Social Security Administration keeps track of first names by date of birth and they make this data freely available, so I could answer that question.
As it turned out „Collin” experienced an dramatic jump in popularity around the turn of the century, momentarily eclipsing the (correct, of course) „Colin.”
The graph shows the relative popularity of „Colin” vs. „Collin for people born since 1940. W 1940 około 85 procent z dwóch nazw były za pomocą jednego „l”, który utrzymał się do późnych lat siedemdziesiątych; dwa „l” wariant wystartował szybko i krótko przekroczyła pojedynczego „l” wersji około 1999 przed dryfuje niższe kiedykolwiek od.
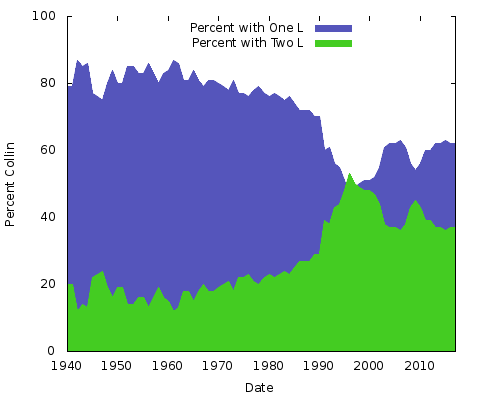
Co to wszystko znaczy? Nie mam pojęcia. Niezależnie od powodów, będą one inne dla innych par pisowni nazwisk. Można by zrobić to samo dla „Eric” vs. „Erik” lub „Rachel” vs. „Rachael” i wielu innych. Właściwie, zróbmy te dwa:
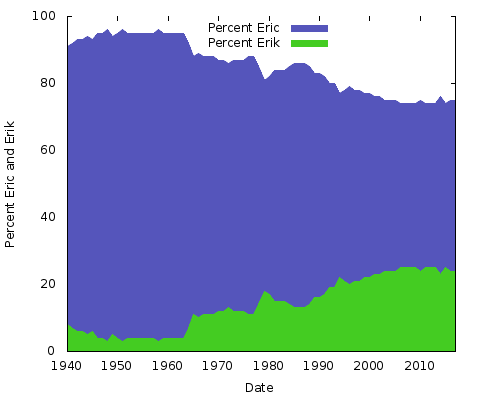
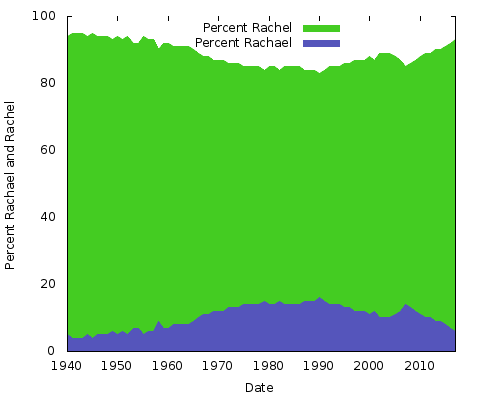
To są proste wykresy obszarowe. W tym celu wolę je od wykresów piętrowych; z tylko dwoma liniami, gdzie suma dwóch wartości osi Y zawsze wynosi 100%, skończyłoby się na tym, że dolna linia byłaby taka sama, a górna połowa jednolitego koloru. W ten sposób można uzyskać lepsze wyobrażenie o dużej zmianie w popularności dwóch pisowni.
Stosowany wykres obszaru byłby świetny do pokazania trendów więcej niż dwóch nazw: Na przykład można pokazać zmianę płci związanej z nazwiskami w czasie tylko z jednym nazwiskiem za pomocą wykresu, takiego jak ten powyżej, ale za pomocą jednego obrazu można ułożyć wiele nazwisk i przekazać te same informacje:
Social Security Baby Name Data
Dane pochodzą z witryny SSA, gdzie udostępniają publicznie 1000 najpopularniejszych imion niemowląt dla każdego roku urodzenia w ich rejestrach. Przed 1940 dane są dość skąpe, ponieważ administracja została założona dopiero w latach trzydziestych. Nadal można uzyskać nazwy sięgające 1880 roku, ale jest ich mniej, ponieważ tylko ludzie, którzy zapisali się w latach trzydziestych i później są włączone.
Uzyskaj dane na tej stronie SSA. It comes in a .zip archive holding separate files for every year of birth, and there’s a version of the data broken out by U.S. states.
The data look like
Linda,F,99686Mary,F,71688Patricia,F,51278Barbara,F,48791Sandra,F,34774Carol,F,33538Nancy,F,32442This is from the top of the 1947 file.
Będziesz chciał połączyć pliki z pojedynczymi latami w jeden i prawdopodobnie dodać kolumnę „Rok urodzenia” (YOB), aby ułatwić korzystanie z niego przy tworzeniu wykresów związanych z czasem. Napisałem mały skrypt w Ruby, który to zrobi.
Aby dostarczyć dane do pakietu do tworzenia wykresów, prawdopodobnie będziesz musiał je jeszcze trochę zmasakrować: Musisz przekształcić wiersze z pojedynczą nazwą w wiersze z kolumnami dla wszystkich punktów danych, które chcesz wykreślić na wykresie. Mogą one znajdować się w jednym pliku lub jeden plik na linię wykresu (Gnuplot pozwala na pracę w ten sposób, ładując wiele plików do jednego wykresu). Możesz to zrobić w Ruby lub Pythonie. Ja zrobiłem to za pomocą SQL i narzędzia „Q Text-as-Data”, a następnie podałem wynik do Gnuplota.