
update : Wprowadziliśmy interaktywną aplikację do nauki dla uczenia maszynowego / AI,>> Sprawdź to za darmo teraz <<
Importuj wymagane biblioteki
import numpy as np
import pandas as pd
eps = np.finfo(float).eps
from numpy import log2 as log
’eps’ tutaj jest najmniejszą reprezentowalną liczbą. Czasami otrzymujemy log(0) lub 0 w mianowniku, aby tego uniknąć będziemy używać tego.
Zdefiniuj zbiór danych:
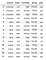
Utwórz ramkę danych pandas :
Teraz spróbujmy przypomnieć sobie kroki tworzenia drzewa decyzyjnego….
1.compute the entropy for data-set2.for every attribute/feature:
1.calculate entropy for all categorical values
2.take average information entropy for the current attribute
3.calculate gain for the current attribute3. pick the highest gain attribute.
4. Repeat until we get the tree we desired
- znajdź Entropię, a następnie Zysk Informacyjny dla podziału zbioru danych.
Zdefiniujemy funkcję, która przyjmuje klasę (wektor zmiennych docelowych) i znajduje entropię tej klasy.
Tutaj ułamek to 'pi’, jest to stosunek liczby elementów w tej podzielonej grupie do liczby elementów w grupie przed podziałem(grupa macierzysta).

2 .Teraz zdefiniuj funkcję {ent} do obliczenia entropii każdego atrybutu :
zapamiętaj entropię każdego atrybutu z jego nazwą :
a_entropy = {k:ent(df,k) for k in df.keys()}
a_entropy

3. Oblicz zysk Info każdego atrybutu :
zdefiniuj funkcję do obliczania IG (infogain) :
IG(attr) = entropia zbioru danych – entropia atrybutu
def ig(e_dataset,e_attr):
return(e_dataset-e_attr)
zapisz IG każdego attr w dict :
#entropy_node = entropy of dataset
#a_entropy = entropy of k(th) attrIG = {k:ig(entropy_node,a_entropy) for k in a_entropy}

jak widzimy outlook ma najwyższy info gain 0.24 , dlatego wybierzemy outook jako węzeł na tym poziomie do podziału.
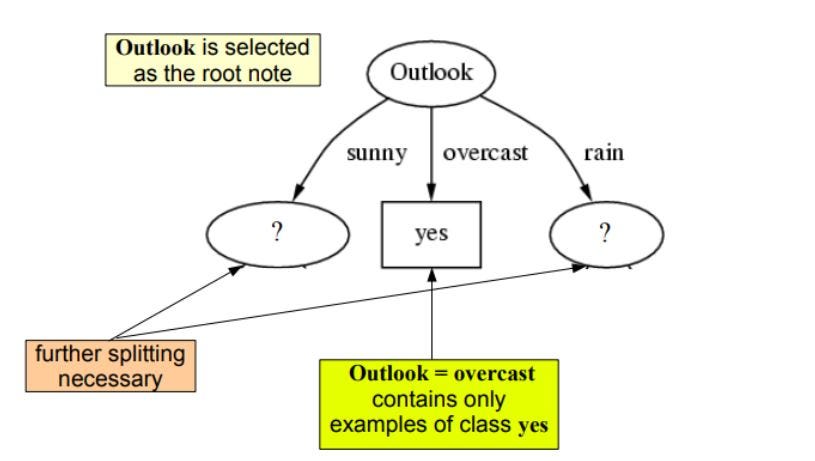
Teraz aby kontynuować nasze drzewo użyjemy rekurencji
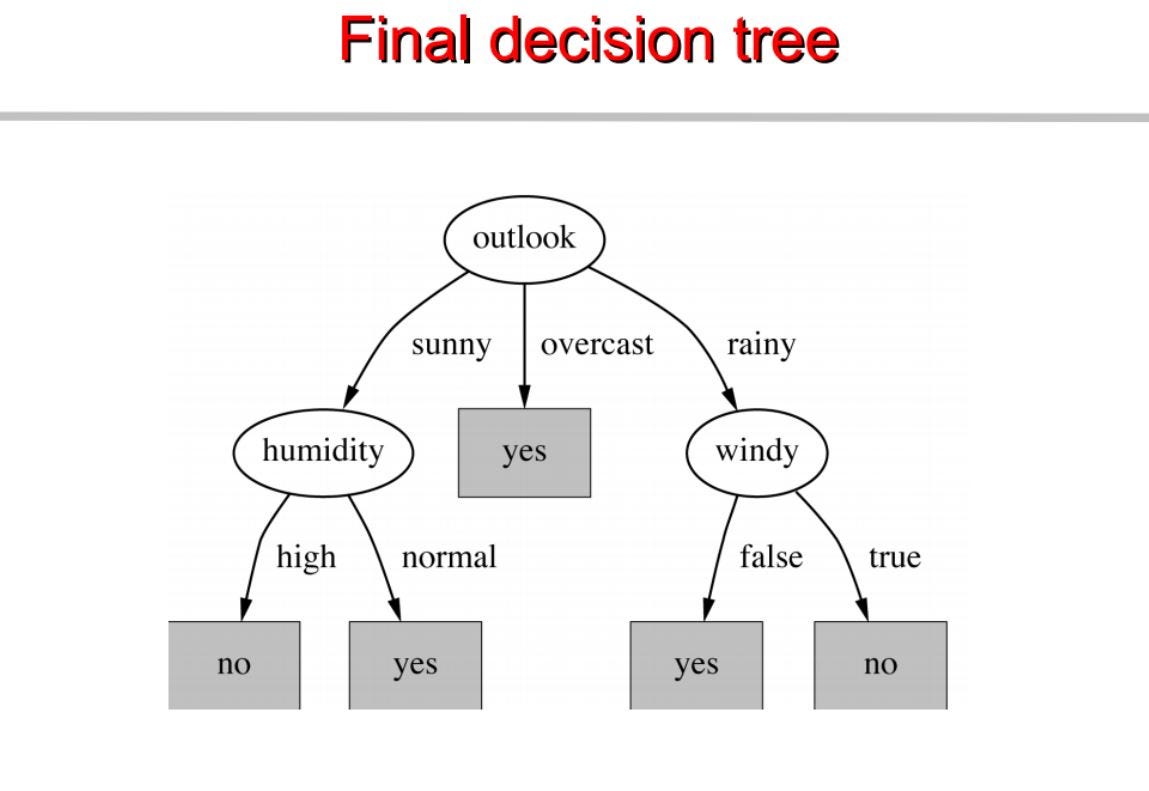
Powtarzamy to samo dla poddrzew aż do uzyskania drzewa.

Na tej podstawie budujemy drzewo decyzyjne. Poniżej znajduje się kompletny kod.

visit pytholabs.com for amazing courses
.