W tym poście nauczymy się skrobania stron internetowych za pomocą pythona. Używając pythona będziemy skrobać Yahoo Finance. Jest to świetne źródło danych giełdowych. Zakodujemy do tego scrapera. Używając tego scrapera będziesz w stanie wyskrobać dane o akcjach dowolnej firmy z Yahoo Finance. Jak wiesz, lubię upraszczać rzeczy, w tym celu będę również używał web scrapera, który zwiększy twoją wydajność skrobania.
Dlaczego to narzędzie? To narzędzie pomoże nam w skrobaniu dynamicznych stron internetowych przy użyciu milionów obrotowych serwerów proxy, abyśmy nie zostali zablokowani. Zapewnia również możliwość rozliczania. Używa chrome bez nagłówków do skrobania dynamicznych stron internetowych.
Generalnie, skrobanie stron internetowych jest podzielone na dwie części:
- Pobieranie danych przez żądanie HTTP
- Wyciąganie ważnych danych przez parsowanie HTML DOM
Biblioteki &Narzędzia
- Beautiful Soup jest biblioteką Pythona do wyciągania danych z plików HTML i XML.
- Żądania pozwalają na wysyłanie żądań HTTP w bardzo prosty sposób.
- Narzędzie do skrobania stron internetowych, aby wyodrębnić kod HTML docelowego adresu URL.
Skonfiguruj
Nasza konfiguracja jest całkiem prosta. Wystarczy utworzyć folder i zainstalować żądania Beautiful Soup &. Aby utworzyć folder i zainstalować biblioteki wpisz poniższe komendy. Zakładam, że masz już zainstalowany Python 3.x.
mkdir scraper
pip install beautifulsoup4
pip install requests
Teraz utwórz plik wewnątrz tego folderu o dowolnej nazwie. Ja używam scraping.py.
Po pierwsze, musisz zarejestrować się w API scrapingdog. Zapewni ci to 1000 DARMOWYCH kredytów. Następnie po prostu zaimportuj Piękna Zupa & żądania w swoim pliku. jak to.
from bs4 import BeautifulSoup
import requests
Co będziemy skrobać
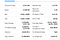
Tutaj jest lista pól, które będziemy wydobywać:
- Previous Close
- Open
- Bid
- Ask
- Day’s Range
- 52 Week Range
- Volume
- Avg. Volume
- Market Cap
- Beta
- PE Ratio
- EPS
- Earnings Rate
- Forward Dividend & Yield
- Ex-Dividend & Date
- 1y target EST
Preparing the Food
Teraz, skoro mamy już wszystkie składniki do przygotowania scrapera, powinniśmy wykonać żądanie GET do docelowego adresu URL, aby uzyskać surowe dane HTML. Jeśli nie jesteś zaznajomiony z narzędziem do skrobania, zachęcam do przejrzenia jego dokumentacji. Teraz będziemy skrobać Yahoo Finance dla danych finansowych używając biblioteki żądań, jak pokazano poniżej.
r = requests.get("https://api.scrapingdog.com/scrape?api_key=<your-api-key>&url=https://finance.yahoo.com/quote/AMZN?p=AMZN&.tsrc=fin-srch").text
To zapewni ci kod HTML tego docelowego adresu URL.
Teraz, musisz użyć BeautifulSoup do parsowania HTML.
soup = BeautifulSoup(r,'html.parser')
Teraz, na całej stronie, mamy cztery znaczniki „tbody”. Interesują nas dwa pierwsze, ponieważ obecnie nie potrzebujemy danych dostępnych wewnątrz trzeciego &czwartego znacznika „tbody”.
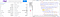
Najpierw poznamy wszystkie te znaczniki „tbody” za pomocą zmiennej „soup”.
alldata = soup.find_all("tbody")

Jak można zauważyć, pierwsze dwa „tbody” mają 8 znaczników „tr” i każdy znacznik „tr” ma dwa znaczniki „td”.
try:
table1 = alldata.find_all("tr")
except:
table1=Nonetry:
table2 = alldata.find_all("tr")
except:
table2 = None
Teraz każdy znacznik „tr” ma dwa znaczniki „td”. Pierwszy znacznik td składa się z nazwy właściwości, a drugi ma wartość tej właściwości. Jest to coś w rodzaju pary klucz-wartość.

W tym momencie zadeklarujemy listę i słownik przed uruchomieniem pętli for.
l={}
u=list()
Dla uproszczenia kodu będę uruchamiał dwie różne pętle „for” dla każdej tabeli. Najpierw dla „tabela1”
for i in range(0,len(table1)):
try:
table1_td = table1.find_all("td")
except:
table1_td = None l.text] = table1_td.text u.append(l)
l={}
Teraz, to co zrobiliśmy, to przechowujemy wszystkie znaczniki td w zmiennej „tabela1_td”. A następnie przechowujemy wartość pierwszego & drugiego znacznika td w „słowniku”. Następnie wypychamy słownik do listy. Ponieważ nie chcemy przechowywać zduplikowanych danych, na końcu uczynimy słownik pustym. Podobne kroki wykonamy dla „table2”.
for i in range(0,len(table2)):
try:
table2_td = table2.find_all("td")
except:
table2_td = None l.text] = table2_td.text u.append(l)
l={}
Na końcu, gdy wydrukujemy listę „u”, otrzymamy odpowiedź JSON.
{
"Yahoo finance":
}
Czy to nie jest niesamowite. Udało nam się zeskrobać finanse Yahoo w ciągu zaledwie 5 minut konfiguracji. Mamy tablicę Python Object zawierającą dane finansowe firmy Amazon. W ten sposób możemy zeskrobać dane z dowolnej strony internetowej.
Konkluzja
W tym artykule, zrozumieliśmy jak możemy zeskrobać dane używając narzędzia do skrobania danych & BeautifulSoup niezależnie od typu strony internetowej.
Nie krępuj się komentować i pytać mnie o cokolwiek. Możesz śledzić mnie na Twitterze i Medium. Dzięki za czytanie i proszę uderz w przycisk like! 👍
Dodatkowe zasoby
I jest lista! W tym momencie, powinieneś czuć się komfortowo pisząc swój pierwszy web scraper do zbierania danych z dowolnej strony internetowej. Oto kilka dodatkowych zasobów, które mogą okazać się pomocne podczas podróży w kierunku skrobania stron WWW:
- Lista usług proxy do skrobania stron WWW
- Lista przydatnych narzędzi do skrobania stron WWW
- Dokumentacja BeautifulSoup
- Dokumentacja Scrapingdog
- Przewodnik po skrobaniu stron WWW
.