By Raymond Yuan, Software Engineering Intern
W tym tutorialu dowiemy się, jak wykorzystać głębokie uczenie do komponowania obrazów w stylu innego obrazu (czy kiedykolwiek chciałeś malować jak Picasso lub Van Gogh?). Jest to znane jako neuronowe przenoszenie stylów! Jest to technika przedstawiona w artykule Leona A. Gatysa, A Neural Algorithm of Artistic Style, który jest świetną lekturą i zdecydowanie powinieneś go sprawdzić.
Neuronowe przenoszenie stylów jest techniką optymalizacji używaną do wzięcia trzech obrazów, obrazu zawartości, obrazu odniesienia stylu (takiego jak dzieło sztuki słynnego malarza) i obrazu wejściowego, który chcesz stylizować – i zmieszania ich razem tak, że obraz wejściowy jest przekształcony, aby wyglądał jak obraz zawartości, ale „namalowany” w stylu obrazu stylu.
Na przykład, weźmy obraz tego żółwia i obraz Katsushika Hokusai’s The Great Wave off Kanagawa:
A teraz jak by to wyglądało, gdyby Hokusai postanowił dodać do obrazu żółwia fakturę lub styl swoich fal? Coś takiego?
Czy to magia czy po prostu głębokie uczenie? Na szczęście nie wiąże się to z żadną magią: przenoszenie stylów jest zabawną i interesującą techniką, która pokazuje możliwości i wewnętrzne reprezentacje sieci neuronowych.
Zasada neuronowego przenoszenia stylów polega na zdefiniowaniu dwóch funkcji odległości, jednej, która opisuje, jak różna jest treść dwóch obrazów, Lcontent, i jednej, która opisuje różnicę między tymi dwoma obrazami pod względem ich stylu, Lstyle. Następnie, biorąc pod uwagę trzy obrazy, pożądany obraz stylu, pożądany obraz zawartości i obraz wejściowy (zainicjowany obrazem zawartości), próbujemy przekształcić obraz wejściowy, aby zminimalizować odległość zawartości z obrazem zawartości i jego odległość stylu z obrazem stylu.
Podsumowując, weźmiemy bazowy obraz wejściowy, obraz zawartości, który chcemy dopasować i obraz stylu, który chcemy dopasować. Przekształcimy bazowy obraz wejściowy, minimalizując odległości (straty) treści i stylu za pomocą wstecznej propagacji, tworząc obraz, który pasuje do treści obrazu treści i stylu obrazu stylu.
W procesie, będziemy budować praktyczne doświadczenie i rozwijać intuicję wokół następujących pojęć:
- Eager Execution – użyj imperatywnego środowiska programistycznego TensorFlow, które ocenia operacje natychmiast
- Dowiedz się więcej o eager execution
- Zobacz to w akcji (wiele tutoriali można uruchomić w Colaboratory)
- Używanie Functional API do definiowania modelu – zbudujemy podzbiór naszego modelu, który da nam dostęp do niezbędnych. pośrednich aktywacji za pomocą Functional API
- Leveraging feature maps of a pretrained model – dowiemy się jak korzystać z modeli pretrained i ich feature maps
- Tworzenie niestandardowych pętli treningowych – zbadamy jak skonfigurować optymalizator, aby zminimalizować daną stratę względem parametrów wejściowych
- Podążymy za ogólnymi krokami, aby wykonać transfer stylu:
- Kod:
- Implementacja
- Zdefiniuj reprezentacje treści i stylu
- Dlaczego warstwy pośrednie?
- Model
- Zdefiniuj i utwórz nasze funkcje straty (odległości treści i stylu)
- Strata stylu:
- Run Gradient Descent
- Oblicz stratę i gradienty
- Zastosuj i uruchom proces przenoszenia stylów
- Czym się zajmowaliśmy:
Podążymy za ogólnymi krokami, aby wykonać transfer stylu:
- Visualize data
- Basic Preprocessing/preparing our data
- Set up loss functions
- Create model
- Optimize for loss function
Audience: Ten post jest skierowany do średnio zaawansowanych użytkowników, którzy czują się komfortowo z podstawowymi koncepcjami uczenia maszynowego. Aby uzyskać jak najwięcej z tego postu, powinieneś:
- Przeczytać artykuł Gatysa – wyjaśnimy po drodze, ale artykuł zapewni bardziej dogłębne zrozumienie zadania
- Zrozumieć zejście gradientowe
Czas szacowany: 60 min
Kod:
Pełny kod do tego artykułu można znaleźć pod tym linkiem. Jeśli chciałbyś prześledzić ten przykład, możesz znaleźć kolabo tutaj.
Implementacja
Zaczniemy od włączenia eager execution. Eager execution pozwala nam przepracować tę technikę w najbardziej przejrzysty i czytelny sposób.

Zdefiniuj reprezentacje treści i stylu
Aby uzyskać zarówno reprezentacje treści jak i stylu naszego obrazu, przyjrzymy się pewnym warstwom pośrednim w naszym modelu. Warstwy pośrednie reprezentują mapy cech, które stają się coraz bardziej uporządkowane, gdy schodzimy głębiej. W tym przypadku używamy architektury sieci VGG19, wstępnie wytrenowanej sieci klasyfikacji obrazów. Te warstwy pośrednie są niezbędne do zdefiniowania reprezentacji treści i stylu z naszych obrazów. Dla obrazu wejściowego, spróbujemy dopasować odpowiednie reprezentacje docelowe stylu i treści w tych warstwach pośrednich.
Dlaczego warstwy pośrednie?
Możesz się zastanawiać, dlaczego te pośrednie wyjścia w naszej wstępnie wytrenowanej sieci klasyfikacji obrazów pozwalają nam zdefiniować reprezentacje stylu i treści. Na wysokim poziomie, zjawisko to może być wyjaśnione przez fakt, że aby sieć mogła wykonać klasyfikację obrazu (do czego nasza sieć została wytrenowana), musi zrozumieć obraz. Wymaga to wzięcia surowego obrazu jako pikseli wejściowych i zbudowania wewnętrznej reprezentacji poprzez transformacje, które przekształcają surowe piksele obrazu w złożone zrozumienie cech obecnych w obrazie. Jest to również częściowo dlaczego konwencjonalne sieci neuronowe są w stanie dobrze generalizować: są one w stanie uchwycić niezmienniki i cechy definiujące w ramach klas (np. koty vs. psy), które są niezależne od szumu tła i innych uciążliwości. W ten sposób, gdzieś pomiędzy wprowadzeniem surowego obrazu a wyprowadzeniem etykiety klasyfikacyjnej, model służy jako złożony ekstraktor cech; stąd, poprzez dostęp do warstw pośrednich, jesteśmy w stanie opisać zawartość i styl obrazów wejściowych.
Specyficznie wyciągniemy te warstwy pośrednie z naszej sieci:
Model
W tym przypadku, ładujemy VGG19 i wprowadzamy nasz tensor wejściowy do modelu. To pozwoli nam wyodrębnić mapy cech (a następnie reprezentacje treści i stylu) treści, stylu i wygenerowanych obrazów.
Używamy VGG19, jak sugeruje artykuł. Ponadto, ponieważ VGG19 jest stosunkowo prostym modelem (w porównaniu z ResNet, Inception, itp.), mapy cech faktycznie działają lepiej dla transferu stylu.
Aby uzyskać dostęp do warstw pośrednich odpowiadających naszym mapom cech stylu i treści, uzyskujemy odpowiednie wyjścia za pomocą Keras Functional API, aby zdefiniować nasz model z pożądanymi aktywacjami wyjściowymi.
Z Functional API, definiowanie modelu polega po prostu na określeniu wejścia i wyjścia: model = Model(inputs, outputs).
W powyższym snippecie kodu, załadujemy naszą wstępnie wytrenowaną sieć klasyfikacji obrazów. Następnie pobieramy interesujące nas warstwy, które zdefiniowaliśmy wcześniej. Następnie definiujemy model, ustawiając jego dane wejściowe na obraz, a dane wyjściowe na wyjścia warstw stylu i treści. Innymi słowy, stworzyliśmy model, który będzie pobierał obraz wejściowy i wyprowadzał warstwy pośrednie treści i stylu!
Zdefiniuj i utwórz nasze funkcje straty (odległości treści i stylu)
Nasza definicja straty treści jest właściwie dość prosta. Przekażemy sieci zarówno pożądany obraz zawartości, jak i nasz bazowy obraz wejściowy. To zwróci wyjścia warstwy pośredniej (z warstw zdefiniowanych powyżej) z naszego modelu. Następnie po prostu weźmiemy odległość euklidesową między dwoma pośrednimi reprezentacjami tych obrazów.
Bardziej formalnie, strata treści jest funkcją, która opisuje odległość treści od naszego obrazu wejściowego x i naszego obrazu zawartości, p . Niech Cₙₙ będzie wstępnie wytrenowaną głęboką konwolucyjną siecią neuronową. Ponownie, w tym przypadku używamy VGG19. Niech X będzie dowolnym obrazem, wtedy Cₙₙ(x) jest siecią zasilaną przez X. Niech Fˡᵢⱼ(x)∈ Cₙₙ(x)i Pˡᵢⱼ(x) ∈ Cₙₙ(x) opisują odpowiednią pośrednią reprezentację cech sieci z wejściami x i p w warstwie l . Następnie opisujemy odległość (stratę) zawartości formalnie jako:
Wykonujemy wsteczną propagację w zwykły sposób tak, aby zminimalizować stratę zawartości. W ten sposób zmieniamy początkowy obraz, dopóki nie wygeneruje on podobnej odpowiedzi w pewnej warstwie (zdefiniowanej w content_layer) jak oryginalny obraz zawartości.
To może być zaimplementowane całkiem prosto. Ponownie weźmie jako dane wejściowe mapy cech na warstwie L w sieci zasilanej przez x, nasz obraz wejściowy, i p, nasz obraz zawartości, i zwróci odległość zawartości.
Strata stylu:
Obliczanie straty stylu jest nieco bardziej zaangażowane, ale podąża za tą samą zasadą, tym razem karmiąc naszą sieć bazowym obrazem wejściowym i obrazem stylu. Jednak zamiast porównywać surowe wyjścia pośrednie bazowego obrazu wejściowego i obrazu stylu, porównujemy macierze Grama tych dwóch wyjść.
Matematycznie, opisujemy stratę stylu bazowego obrazu wejściowego, x, i obrazu stylu, a, jako odległość między reprezentacją stylu (macierze Grama) tych obrazów. Reprezentację stylu obrazu opisujemy jako korelację pomiędzy różnymi odpowiedziami filtrów, daną przez macierz Grama Gˡ, gdzie Gˡᵢⱼ jest iloczynem wewnętrznym pomiędzy zwektoryzowaną mapą cech i oraz j w warstwie l. Widzimy, że Gˡᵢⱼ wygenerowane nad mapą cech dla danego obrazu reprezentuje korelację między mapami cech i oraz j.
Aby wygenerować styl dla naszego bazowego obrazu wejściowego, wykonujemy zejście gradientowe z obrazu zawartości, aby przekształcić go w obraz, który pasuje do reprezentacji stylu oryginalnego obrazu. Robimy to poprzez minimalizację średniej kwadratowej odległości pomiędzy mapą korelacji cech obrazu stylu i obrazu wejściowego. Udział każdej warstwy w całkowitej stracie stylu jest opisany wzorem
gdzie Gˡᵢⱼ i Aˡᵢⱼ to odpowiednie reprezentacje stylu w warstwie l obrazu wejściowego x i obrazu stylu a. Nl określa liczbę map cech, z których każda ma rozmiar Ml=wysokość∗szerokość. Zatem całkowita strata stylu w każdej warstwie wynosi
gdzie ważymy udział straty każdej warstwy przez pewien współczynnik wl. W naszym przypadku ważymy każdą warstwę po równo:
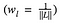
Realizuje się to w prosty sposób:
Run Gradient Descent
Jeśli nie jesteś zaznajomiony z gradient descent/backpropagation lub potrzebujesz odświeżenia, powinieneś zdecydowanie sprawdzić ten zasób.
W tym przypadku używamy optymalizatora Adam w celu zminimalizowania naszej straty. Iteracyjnie aktualizujemy nasz obraz wyjściowy tak, aby zminimalizować naszą stratę: nie aktualizujemy wag związanych z naszą siecią, ale zamiast tego trenujemy nasz obraz wejściowy, aby zminimalizować stratę. Aby to zrobić, musimy wiedzieć, jak obliczamy stratę i gradienty. Zauważ, że optymalizator L-BFGS, który jest zalecany, jeśli jesteś zaznajomiony z tym algorytmem, nie jest używany w tym tutorialu, ponieważ podstawową motywacją tego tutorialu było zilustrowanie najlepszych praktyk z eager execution. Używając Adama, możemy zademonstrować funkcjonalność autograd/gradient tape z niestandardowymi pętlami treningowymi.
Oblicz stratę i gradienty
Zdefiniujemy małą funkcję pomocniczą, która załaduje nasz obraz zawartości i stylu, przepuści je przez naszą sieć, która następnie wyprowadzi reprezentacje cech zawartości i stylu z naszego modelu.
Tutaj użyjemy tf.GradientTape do obliczenia gradientu. Pozwala nam to na skorzystanie z automatycznego różnicowania dostępnego poprzez śledzenie operacji w celu późniejszego obliczenia gradientu. Zapisuje on operacje podczas przejścia w przód, a następnie jest w stanie obliczyć gradient naszej funkcji straty w odniesieniu do obrazu wejściowego dla przejścia w tył.
Obliczanie gradientów jest łatwe:
Zastosuj i uruchom proces przenoszenia stylów
Aby faktycznie wykonać przenoszenie stylów:
I to wszystko!
Uruchommy go na naszym obrazie żółwia i obrazu Hokusai Wielka fala u wybrzeży Kanagawy:

Zobacz iteracyjny proces w czasie:

Oto kilka innych fajnych przykładów tego, co potrafi neuronowe przekazywanie stylów. Sprawdź to!
Wypróbuj własne obrazy!
Czym się zajmowaliśmy:
- Zbudowaliśmy kilka różnych funkcji strat i użyliśmy wstecznej propagacji do przekształcenia naszego obrazu wejściowego w celu zminimalizowania tych strat.
- Aby to zrobić, wczytaliśmy wstępnie wytrenowany model i użyliśmy jego wyuczonych map cech do opisania zawartości i reprezentacji stylu naszych obrazów.
- Nasze główne funkcje strat były przede wszystkim obliczaniem odległości w kategoriach tych różnych reprezentacji.
- Zaimplementowaliśmy to za pomocą niestandardowego modelu i chętnego wykonania.
- Zbudowaliśmy nasz niestandardowy model za pomocą Functional API.
- Eager execution pozwala nam dynamicznie pracować z tensorami, używając naturalnego pythonowego przepływu sterowania.
- Manipulowaliśmy bezpośrednio tensorami, co ułatwia debugowanie i pracę z tensorami.
Iteracyjnie aktualizowaliśmy nasz obraz poprzez zastosowanie reguł aktualizacji naszych optymalizatorów przy użyciu tf.gradient. Optymalizator zminimalizował podane straty w odniesieniu do naszego obrazu wejściowego.