actualizar : Introduzimos uma aplicação de aprendizagem interactiva para a aprendizagem de máquinas / IA ,>>>><<
>
Importar as bibliotecas requeridas
>
import numpy as np import pandas as pd eps = np.finfo(float).eps from numpy import log2 as log
>
‘eps’ aqui é o número representativo mais pequeno. Por vezes obtemos log(0) ou 0 no denominador, para evitar que o utilizemos.
Definir o conjunto de dados:
Criar o conjunto de dados pandas :
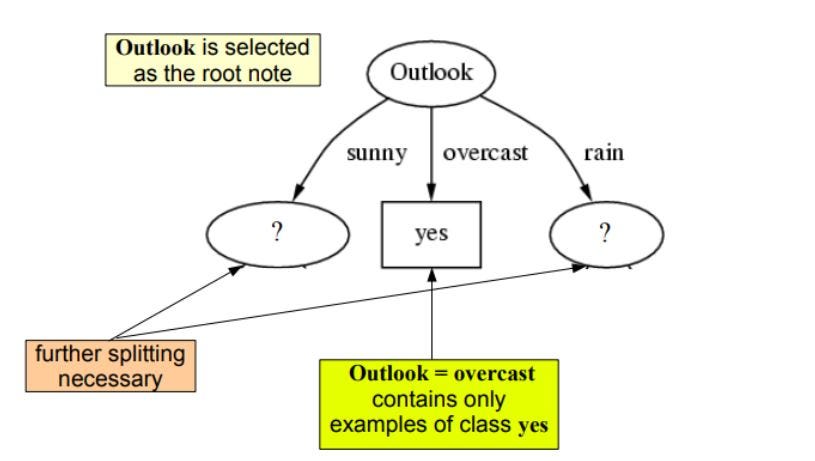
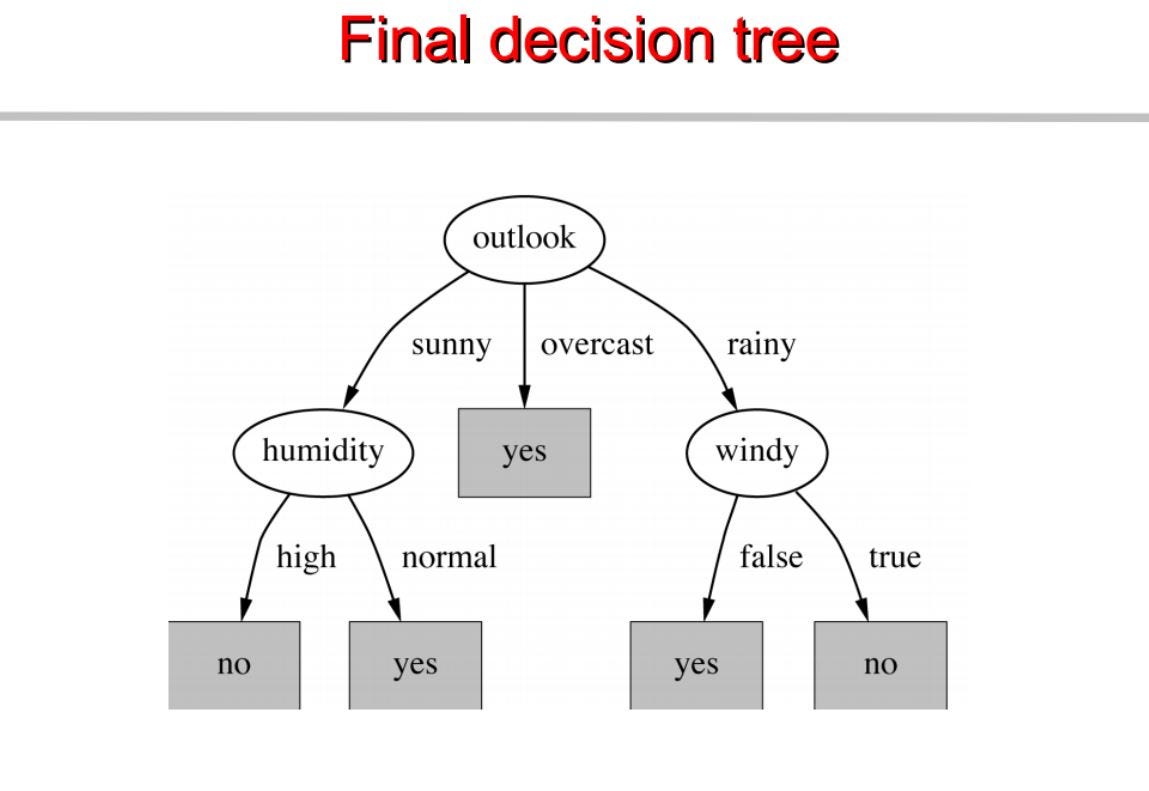
Agora vamos tentar lembrar os passos para criar uma árvore de decisão….
>
1.compute the entropy for data-set2.for every attribute/feature: 1.calculate entropy for all categorical values 2.take average information entropy for the current attribute 3.calculate gain for the current attribute3. pick the highest gain attribute. 4. Repeat until we get the tree we desired
find the Entropy and then Information Gain for splitting the data set.
Definiremos uma função que assume a classe (vetor da variável alvo) e encontra a entropia dessa classe.
Se a fração é ‘pi’, é a proporção de um número de elementos nesse grupo de divisão para o número de elementos no grupo antes da divisão (grupo pai).
resposta é a mesma que obtivemos em nosso artigo anterior
2 .Agora defina uma função {ent} para calcular a entropia de cada atributo :
entropia de cada atributo com seu nome :
a_entropy = {k:ent(df,k) for k in df.keys()} a_entropy
3. calcular o ganho de informação de cada atributo :
defina uma função para calcular IG (infogain) :
IG(attr) = entropia do conjunto de dados – entropia do atributo