>
Neste post, vamos aprender a raspar a web com python. Usando python, vamos raspar o Yahoo Finance. Esta é uma ótima fonte para dados do mercado de ações. Nós vamos codificar um raspador para isso. Usando esse raspador você seria capaz de raspar dados de ações de qualquer empresa do yahoo finance. Como vocês sabem eu gosto de tornar as coisas bem simples, para isso, eu também estarei usando um raspador web que irá aumentar sua eficiência de raspagem.
Por que esta ferramenta? Esta ferramenta nos ajudará a raspar sites dinâmicos usando milhões de proxies rotativos para que não sejamos bloqueados. Ela também fornece uma facilidade de limpeza. Ela usa o cromo sem cabeçalho para raspar websites dinâmicos.
De modo geral, a raspagem da web é dividida em duas partes:
- Recuperar dados fazendo um pedido HTTP
- Extrair dados importantes analisando o HTML DOM
Bibliotecas & Ferramentas
- Beautiful Soup é uma biblioteca Python para extrair dados de arquivos HTML e XML.
- Pedidos permitem que você envie pedidos HTTP muito facilmente.
- ferramenta de raspagem web para extrair o código HTML da URL de destino.
Configuração
Nossa configuração é bem simples. Basta criar uma pasta e instalar o Beautiful Soup & pedidos. Para criar uma pasta e instalar bibliotecas, digite abaixo os comandos fornecidos. Estou assumindo que você já instalou o Python 3.x.
mkdir scraper
pip install beautifulsoup4
pip install requests
Agora, crie um arquivo dentro dessa pasta com qualquer nome que você goste. Estou usando o scraping.py.
Primeiro, você tem que se inscrever para a API do scrapingdog. Ela irá fornecer-lhe 1000 créditos GRÁTIS. Depois basta importar os pedidos de Beautiful Soup & no seu arquivo. assim.
from bs4 import BeautifulSoup
import requests
O que vamos raspar
Aqui está a lista de campos que vamos extrair:
>
- Fechamento Anterior
- Abrir
- Lance
- Ask
- Avalo do Dia
- Avalo da Semana
- Volume
- Avg. Volume
- Capa de mercado
- Beta
- RácioPE
- EPS
- Taxa de ganhos
- Dividendo futuro&Rendimento
- Ex-Dividendo & Data
- 1y alvo EST
>
>
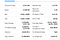
Preparando o alimento
Agora, Como temos todos os ingredientes para preparar o raspador, devemos fazer um pedido de GET para a URL de destino para obter os dados HTML brutos. Se você não está familiarizado com a ferramenta de raspagem, eu gostaria de pedir que você revise a sua documentação. Agora vamos raspar os dados financeiros do Yahoo Finance usando a biblioteca de solicitações como mostrado abaixo.
r = requests.get("https://api.scrapingdog.com/scrape?api_key=<your-api-key>&url=https://finance.yahoo.com/quote/AMZN?p=AMZN&.tsrc=fin-srch").text
esta irá fornecer um código HTML daquela URL de destino.
Agora, você tem que usar o BeautifulSoup para analisar HTML.
soup = BeautifulSoup(r,'html.parser')
Agora, na página inteira, temos quatro tags “tbody”. Estamos interessados nas duas primeiras porque atualmente não precisamos dos dados disponíveis dentro da terceira & quarta tag “tbody”.
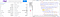
>
Primeiro, vamos descobrir todas essas tags “tbody” usando a variável “sopa”.
alldata = soup.find_all("tbody")
 >
>>
>
>
Como você pode notar que os dois primeiros “tbody” tem 8 tags “tr” e cada tag “tr” tem duas tags “td”.
try:
table1 = alldata.find_all("tr")
except:
table1=Nonetry:
table2 = alldata.find_all("tr")
except:
table2 = None
Agora, cada tag “tr” tem duas tags “td”. A primeira tag td consiste no nome da propriedade e a outra tem o valor dessa propriedade. É algo como um par chave-valor.

>
Neste ponto, vamos declarar uma lista e um dicionário antes de iniciar um para loop.
l={}
u=list()
Para tornar o código simples estarei executando dois loops “for” diferentes para cada tabela. Primeiro para “table1”
for i in range(0,len(table1)):
try:
table1_td = table1.find_all("td")
except:
table1_td = None l.text] = table1_td.text u.append(l)
l={}
Agora, o que fizemos foi armazenar todas as tags td em uma variável “table1_td”. E depois estamos armazenando o valor da primeira & segunda tag td em um “dicionário”. Depois estamos a empurrar o dicionário para uma lista. Como não queremos armazenar dados duplicados, vamos tornar o dicionário vazio no final. Passos semelhantes serão seguidos para “table2”.
for i in range(0,len(table2)):
try:
table2_td = table2.find_all("td")
except:
table2_td = None l.text] = table2_td.text u.append(l)
l={}
Então no final quando você imprime a lista “u” você recebe uma resposta JSON.
{
"Yahoo finance":
}
Não é incrível? Conseguimos raspar as finanças do Yahoo em apenas 5 minutos de configuração. Temos um array de objetos python contendo os dados financeiros da empresa Amazon. Desta forma, podemos raspar os dados de qualquer website.
Conclusion
Neste artigo, entendemos como podemos raspar os dados usando a ferramenta de raspagem de dados & BeautifulSoup independentemente do tipo de website.
Feel free to comment and ask me anything. Você pode me seguir no Twitter e no Médio. Obrigado por ler e por favor aperte o botão like! 👍
Recursos Adicionais
E lá está a lista! Neste ponto, você deve se sentir confortável escrevendo seu primeiro web scraper para coletar dados de qualquer site. Aqui estão alguns recursos adicionais que você pode achar úteis durante sua jornada de raspagem da web:
- Lista de serviços de proxy de raspagem da web
- Lista de ferramentas úteis de raspagem da web
- Documentação do BeautifulSoup
- Documentação do Scrapingdog
- Guia para raspagem da web