>
>
>
>
>
Por Raymond Yuan, Estagiário de Engenharia de Software
Neste tutorial, vamos aprender como usar o aprendizado profundo para compor imagens no estilo de outra imagem (já desejou poder pintar como Picasso ou Van Gogh?). Isto é conhecido como transferência de estilo neural! Esta é uma técnica delineada no papel de Leon A. Gatys, A Neural Algorithm of Artistic Style, que é uma ótima leitura, e você definitivamente deve checar.
Neural style transfer é uma técnica de otimização usada para pegar três imagens, uma imagem de conteúdo, uma imagem de referência de estilo (como uma obra de arte de um pintor famoso), e a imagem de entrada que você quer estilizar – e misturá-las de forma que a imagem de entrada seja transformada para se parecer com a imagem de conteúdo, mas “pintada” no estilo da imagem de estilo.
Por exemplo, vamos pegar uma imagem desta tartaruga e Katsushika Hokusai’s The Great Wave off Kanagawa:
Agora como seria se Hokusai decidisse adicionar a textura ou estilo de suas ondas à imagem da tartaruga? Algo assim?
Isto é magia ou apenas aprendizagem profunda? Felizmente, isto não envolve nenhuma magia: a transferência de estilo é uma técnica divertida e interessante que mostra as capacidades e representações internas das redes neurais.
O princípio da transferência de estilo neural é definir duas funções de distância, uma que descreve quão diferente é o conteúdo de duas imagens, Lcontent, e outra que descreve a diferença entre as duas imagens em termos do seu estilo, Lstyle. Então, dadas três imagens, uma imagem de estilo desejado, uma imagem de conteúdo desejado e a imagem de entrada (inicializada com a imagem de conteúdo), tentamos transformar a imagem de entrada para minimizar a distância de conteúdo com a imagem de conteúdo e a distância de estilo com a imagem de estilo.
Em resumo, vamos pegar a imagem de entrada base, uma imagem de conteúdo que queremos combinar, e a imagem de estilo que queremos combinar. Vamos transformar a imagem de entrada base, minimizando as distâncias (perdas) de conteúdo e estilo com retropropagação, criando uma imagem que combine com o conteúdo da imagem de conteúdo e o estilo da imagem de estilo.
No processo, vamos construir experiência prática e desenvolver a intuição em torno dos seguintes conceitos:
- Eager Execution – use o ambiente de programação imperativo de TensorFlow que avalia operações imediatamente
- Aprenda mais sobre eager execution
- Veja em ação (muitos dos tutoriais são executados em Colaboratory)
- Usando a API funcional para definir um modelo – vamos construir um subconjunto do nosso modelo que nos dará acesso ao ativações intermediárias usando a API funcional
- Alavancando mapas de características de um modelo pré-treinado – Aprenda como usar modelos pré-treinados e seus mapas de características
- Criar loops de treinamento personalizados – examinaremos como configurar um otimizador para minimizar uma determinada perda com respeito aos parâmetros de entrada
- Seguiremos os passos gerais para realizar a transferência de estilo:
- Código:
- Implementação
- Definir representações de conteúdo e estilo
- Por que camadas intermediárias?
- Modelo
- Definir e criar nossas funções de perda (distâncias de conteúdo e estilo)
- Perda de estilo:
- Descida de Gradiente Corrida
- Compute the loss and gradients
- Aplique e execute o processo de transferência de estilo
- O que cobrimos:
Seguiremos os passos gerais para realizar a transferência de estilo:
- Visualizar dados
- Pré-processamento básico/preparação dos nossos dados
- Configurar funções de perda
- Criar modelo
- Optimizar para função de perda
Audiência: Este post é voltado para usuários intermediários que se sentem confortáveis com os conceitos básicos de aprendizagem da máquina. Para tirar o máximo proveito deste post, você deve:
- Ler o papel de Gatys – vamos explicar ao longo do caminho, mas o papel irá fornecer uma compreensão mais profunda da tarefa
- Descida de gradiente de compreensão
Tempo estimado: 60 min
Código:
Você pode encontrar o código completo para este artigo neste link. Se você gostaria de passar por este exemplo, você pode encontrar o colab aqui.
Implementação
Comecemos por habilitar a execução ávida. A execução ávida permite-nos trabalhar através desta técnica da forma mais clara e legível.

Definir representações de conteúdo e estilo
A fim de obter tanto o conteúdo quanto as representações de estilo da nossa imagem, vamos olhar para algumas camadas intermediárias dentro do nosso modelo. As camadas intermediárias representam mapas de características que se tornam cada vez mais ordenadas à medida que você vai mais fundo. Neste caso, estamos usando a arquitetura de rede VGG19, uma rede pré-treinada de classificação de imagens. Estas camadas intermediárias são necessárias para definir a representação de conteúdo e estilo a partir das nossas imagens. Para uma imagem de entrada, tentaremos combinar as representações correspondentes de estilo e conteúdo alvo nestas camadas intermediárias.
Por que camadas intermediárias?
Você pode estar se perguntando por que estas saídas intermediárias dentro da nossa rede pré-treinada de classificação de imagens nos permitem definir representações de estilo e conteúdo. A um nível elevado, este fenómeno pode ser explicado pelo facto de que, para que uma rede realize a classificação de imagens (para a qual a nossa rede foi treinada), tem de compreender a imagem. Isto implica tomar a imagem bruta como pixéis de entrada e construir uma representação interna através de transformações que transformam os pixéis da imagem bruta numa compreensão complexa das características presentes dentro da imagem. Isto também é, em parte, o motivo pelo qual as redes neurais convolucionais são capazes de generalizar bem: elas são capazes de capturar as invariâncias e definir as características dentro das classes (por exemplo, gatos versus cães) que são agnósticos ao ruído de fundo e outros transtornos. Assim, em algum lugar entre onde a imagem bruta é alimentada e a etiqueta de classificação é emitida, o modelo serve como um extrator de características complexas; assim, ao acessar camadas intermediárias, somos capazes de descrever o conteúdo e o estilo das imagens de entrada.
Especificamente, vamos retirar essas camadas intermediárias da nossa rede:
Modelo
Neste caso, carregamos a VGG19, e alimentamos no nosso tensor de entrada o modelo. Isso nos permitirá extrair os mapas de características (e posteriormente as representações de conteúdo e estilo) do conteúdo, estilo e imagens geradas.
Usamos a VGG19, como sugerido no artigo. Além disso, como VGG19 é um modelo relativamente simples (comparado com ResNet, Inception, etc) os mapas de características funcionam melhor para transferência de estilo.
Para acessar as camadas intermediárias correspondentes aos nossos mapas de características de estilo e conteúdo, obtemos as saídas correspondentes usando a API Funcional Keras para definir nosso modelo com as ativações de saída desejadas.
Com a API Funcional, definir um modelo envolve simplesmente definir a entrada e a saída: model = Model(inputs, outputs).
No trecho de código acima, vamos carregar nossa rede de classificação de imagens pré-treinado. Em seguida, pegamos as camadas de interesse como definimos anteriormente. Depois definimos um Modelo definindo as entradas do modelo para uma imagem e as saídas para as saídas das camadas de estilo e conteúdo. Em outras palavras, criamos um modelo que irá pegar uma imagem de entrada e sair as camadas intermediárias de conteúdo e estilo!
Definir e criar nossas funções de perda (distâncias de conteúdo e estilo)
Nossa definição de perda de conteúdo é na verdade bastante simples. Vamos passar na rede tanto a imagem de conteúdo desejada como a nossa imagem de entrada base. Isto irá retornar as saídas da camada intermediária (a partir das camadas definidas acima) do nosso modelo. Em seguida, simplesmente tomamos a distância euclidiana entre as duas representações intermediárias dessas imagens.
Mais formalmente, a perda de conteúdo é uma função que descreve a distância do conteúdo da nossa imagem de entrada x e da nossa imagem de conteúdo, p . Deixe o Cₙₙ ser uma rede neural convolucional profunda e pré-treinada. Mais uma vez, neste caso usamos a VGG19. Que X seja qualquer imagem, então Cₙₙ(x) é a rede alimentada por X. Que Fˡᵢⱼ(x)∈ Cₙₙ(x)e Pˡᵢⱼ(x) ∈ Cₙₙ(x) descreva a respectiva representação de característica intermediária da rede com inputs x e p na camada l . Depois descrevemos a distância (perda) do conteúdo formalmente como:
Realizamos a retropropagação da forma usual de modo a minimizar esta perda de conteúdo. Assim alteramos a imagem inicial até que ela gere uma resposta similar em uma determinada camada (definida em content_layer) como a imagem de conteúdo original.
Esta pode ser implementada de forma bastante simples. Mais uma vez, ele tomará como entrada os mapas de característica em uma camada L em uma rede alimentada por x, nossa imagem de entrada, e p, nossa imagem de conteúdo, e retornará a distância de conteúdo.
Perda de estilo:
Perda de estilo de computação é um pouco mais envolvido, mas segue o mesmo princípio, desta vez alimentando nossa rede a imagem de entrada base e a imagem de estilo. Entretanto, ao invés de comparar as saídas intermediárias brutas da imagem de entrada base e da imagem de estilo, nós comparamos as matrizes Gram das duas saídas.
Matematicamente, nós descrevemos a perda de estilo da imagem de entrada base, x, e a imagem de estilo, a, como a distância entre a representação de estilo (as matrizes gram) destas imagens. Descrevemos a representação de estilo de uma imagem como a correlação entre as diferentes respostas de filtro dadas pela matriz de Gram Gˡ, onde Gˡᵢⱼ é o produto interno entre o mapa de características vetorizadas i e j na camada l. Podemos ver que Gˡᵢⱼ gerado sobre o mapa de características para uma determinada imagem representa a correlação entre os mapas de características i e j.
Para gerar um estilo para a nossa imagem base de entrada, realizamos uma descida gradual a partir da imagem de conteúdo para transformá-la em uma imagem que corresponda à representação de estilo da imagem original. Fazemos isso minimizando a distância média ao quadrado entre o mapa de correlação de características da imagem de estilo e a imagem de entrada. A contribuição de cada camada para a perda total de estilo é descrita por
>onde Gˡᵢⱼ e Aˡᵢⱼ são a respectiva representação de estilo na camada l da imagem de entrada x e da imagem de estilo a. Nl descreve o número de mapas de características, cada um do tamanho Ml=height∗width. Assim, a perda total de estilo em cada camada é
onde pesamos a contribuição da perda de cada camada por algum fator wl. No nosso caso, pesamos cada camada igualmente:
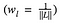
Isto é implementado de forma simples:
Descida de Gradiente Corrida
Se você não está familiarizado com descida de gradiente/backpropagation ou precisa de um refresher, você deve definitivamente verificar este recurso.
Neste caso, nós usamos o otimizador Adam para minimizar a nossa perda. Nós atualizamos iterativamente nossa imagem de saída de forma a minimizar nossa perda: não atualizamos os pesos associados à nossa rede, mas ao invés disso treinamos nossa imagem de entrada para minimizar a perda. Para fazer isso, precisamos saber como calculamos nossa perda e gradientes. Note que o otimizador L-BFGS, que se você está familiarizado com este algoritmo é recomendado, mas não é usado neste tutorial porque uma das principais motivações por trás deste tutorial foi ilustrar as melhores práticas com a execução ávida. Usando Adam, podemos demonstrar a funcionalidade de autograduação/gradiente de fita com loops de treinamento personalizados.
Compute the loss and gradients
Definiremos uma pequena função de ajuda que irá carregar nosso conteúdo e imagem de estilo, alimentá-los através de nossa rede, que irá então sair as representações de conteúdo e estilo do nosso modelo.
Aqui usamos tf.GradientTape para calcular o gradiente. Ele nos permite tirar vantagem da diferenciação automática disponível através de operações de rastreamento para o cálculo do gradiente posteriormente. Ele registra as operações durante a passagem para frente e então é capaz de computar o gradiente da nossa função de perda com relação à nossa imagem de entrada para a passagem para trás.
Então o cálculo dos gradientes é fácil:
Aplique e execute o processo de transferência de estilo
E para realmente executar a transferência de estilo:
E é isso!
>
Vamos executá-lo na nossa imagem da tartaruga e Hokusai’s The Great Wave off Kanagawa:

Veja o processo iterativo ao longo do tempo:

>Aqui estão alguns outros exemplos legais do que a transferência do estilo neural pode fazer. Confira!
Texa as suas próprias imagens!
O que cobrimos:
- Construímos várias funções de perda diferentes e usamos backpropagation para transformar nossa imagem de entrada a fim de minimizar essas perdas.
- Para fazer isso, carregamos em um modelo pré-treinado e usamos seus mapas de características aprendidas para descrever o conteúdo e a representação de estilo de nossas imagens.
- As nossas principais funções de perda foram principalmente o cálculo da distância em termos destas diferentes representações.
- Implementamos isto com um modelo personalizado e de execução ávida.
- Construímos nosso modelo personalizado com a API funcional.
- Execução de python permite-nos trabalhar dinamicamente com tensores, usando um fluxo de controle de python natural.
- Manipulamos diretamente os tensores, o que facilita a depuração e o trabalho com tensores.
Atualizamos iterativamente nossa imagem aplicando nossas regras de atualização de otimizadores usando o tf.gradient. O otimizador minimizou as perdas dadas em relação à nossa imagem de entrada.