În acest post, vom învăța web scraping cu python. Folosind python vom răzui Yahoo Finance. Aceasta este o sursă excelentă de date despre bursă. Vom codifica un scraper pentru aceasta. Folosind acest scraper, veți putea extrage date despre acțiuni ale oricărei companii de pe Yahoo Finance. După cum știți, îmi place să fac lucrurile destul de simple, pentru asta voi folosi, de asemenea, un web scraper care vă va crește eficiența răzuirii.
De ce acest instrument? Acest instrument ne va ajuta să răzuim site-uri web dinamice folosind milioane de proxy-uri rotative, astfel încât să nu fim blocați. De asemenea, oferă o facilitate de compensare. Folosește chrome fără antet pentru a răzui site-urile web dinamice.
În general, răzuirea web este împărțită în două părți:
- Obținerea datelor prin efectuarea unei cereri HTTP
- Extragerea datelor importante prin analizarea DOM-ului HTML
Biblioteci & Instrumente
- Beautiful Soup este o bibliotecă Python pentru extragerea de date din fișiere HTML și XML.
- Requests vă permite să trimiteți foarte ușor cereri HTTP.
- instrument de răzuire web pentru a extrage codul HTML al URL-ului țintă.
Setup
Setup-ul nostru este destul de simplu. Trebuie doar să creați un dosar și să instalați cererile Beautiful Soup &. Pentru crearea unui dosar și instalarea bibliotecilor, tastați comenzile date mai jos. Presupun că ați instalat deja Python 3.x.
mkdir scraper
pip install beautifulsoup4
pip install requests
Acum, creați un fișier în interiorul acelui dosar cu orice nume doriți. Eu folosesc scraping.py.
În primul rând, trebuie să vă înregistrați pentru API-ul scrapingdog. Acesta vă va oferi 1000 de credite GRATUITE. Apoi, trebuie doar să importați Cererile Beautiful Soup & în fișierul dvs. ca aceasta.
from bs4 import BeautifulSoup
import requests
Ce vom răzui
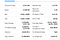
Iată lista de câmpuri pe care le vom extrage:
- Previous Close
- Open
- Bid
- Ask
- Day’s Range
- Day’s Range
- 52 Week Range
- Volume
- Avg. Volum
- Capitalizare bursieră
- Beta
- Raport PE
- EPS
- Taxă de profit
- Dividendele viitoare &Reducere
- Ex.Dividend & Data
- 1y target EST
Pregătirea hranei
Acum, din moment ce avem toate ingredientele pentru a pregăti scraperul, ar trebui să facem o cerere GET la URL-ul țintă pentru a obține datele HTML brute. Dacă nu sunteți familiarizați cu instrumentul de răzuire, v-aș îndemna să parcurgeți documentația acestuia. Acum vom răzui Yahoo Finance pentru date financiare folosind biblioteca de cereri, așa cum se arată mai jos.
r = requests.get("https://api.scrapingdog.com/scrape?api_key=<your-api-key>&url=https://finance.yahoo.com/quote/AMZN?p=AMZN&.tsrc=fin-srch").text
acest lucru vă va oferi un cod HTML al acelui URL țintă.
Acum, trebuie să folosiți BeautifulSoup pentru a analiza HTML.
soup = BeautifulSoup(r,'html.parser')
Acum, pe întreaga pagină, avem patru etichete „tbody”. Suntem interesați de primele două, deoarece în prezent nu avem nevoie de datele disponibile în interiorul celei de-a treia & a patra etichete „tbody”.
În primul rând, vom afla toate aceste etichete „tbody” folosind variabila „soup”.
alldata = soup.find_all("tbody")

După cum puteți observa că primele două „tbody” au 8 tag-uri „tr” și fiecare tag „tr” are două tag-uri „td”.
try:
table1 = alldata.find_all("tr")
except:
table1=Nonetry:
table2 = alldata.find_all("tr")
except:
table2 = None
Acum, fiecare etichetă „tr” are două etichete „td”. Prima etichetă td este formată din numele proprietății, iar cealaltă are valoarea acelei proprietăți. Este ceva de genul unei perechi cheie-valoare.

În acest moment, vom declara o listă și un dicționar înainte de a începe o buclă „for”.
l={}
u=list()
Pentru a simplifica codul, voi rula două bucle „for” diferite pentru fiecare tabel. Prima pentru „table1”
for i in range(0,len(table1)):
try:
table1_td = table1.find_all("td")
except:
table1_td = None l.text] = table1_td.text u.append(l)
l={}
Acum, ceea ce am făcut este să stocăm toate etichetele td într-o variabilă „table1_td”. Și apoi stocăm valoarea primului & al doilea tag td într-un „dicționar”. Apoi, introducem dicționarul într-o listă. Deoarece nu dorim să stocăm date duplicate, vom face ca dicționarul să fie gol la sfârșit. Pași similari vor fi urmați pentru „table2”.
for i in range(0,len(table2)):
try:
table2_td = table2.find_all("td")
except:
table2_td = None l.text] = table2_td.text u.append(l)
l={}
Apoi, la sfârșit, când imprimați lista „u” veți obține un răspuns JSON.
{
"Yahoo finance":
}
Nu este uimitor? Am reușit să răzuim Yahoo finance în doar 5 minute de configurare. Avem o matrice de obiecte python Object care conține datele financiare ale companiei Amazon. În acest fel, putem răzui datele de pe orice site web.
Concluzie
În acest articol, am înțeles cum putem răzui date folosind instrumentul de răzuire a datelor & BeautifulSoup indiferent de tipul de site web.
Nu ezitați să comentați și să mă întrebați orice. Mă puteți urmări pe Twitter și Medium. Vă mulțumim că ați citit și vă rugăm să apăsați butonul de like! 👍
Resurse suplimentare
Și iată lista! În acest moment, ar trebui să vă simțiți confortabil scriind primul dvs. web scraper pentru a aduna date de pe orice site web. Iată câteva resurse suplimentare pe care le puteți găsi utile în timpul călătoriei dvs. de răzuire web:
- Listă de servicii proxy de răzuire web
- Listă de instrumente de răzuire web la îndemână
- Documentație BeautySoup
- Documentație Scrapingdog
- Ghid pentru răzuirea web
.