De Raymond Yuan, Software Engineering Intern
În acest tutorial, vom învăța cum să folosim învățarea profundă pentru a compune imagini în stilul unei alte imagini (v-ați dorit vreodată să puteți picta ca Picasso sau Van Gogh?). Acest lucru este cunoscut sub numele de transfer de stil neural! Aceasta este o tehnică descrisă în lucrarea lui Leon A. Gatys, A Neural Algorithm of Artistic Style (Un algoritm neuronal al stilului artistic), care este o lectură excelentă și pe care ar trebui neapărat să o consultați.
Transferul de stil neuronal este o tehnică de optimizare utilizată pentru a lua trei imagini, o imagine de conținut, o imagine de referință a stilului (cum ar fi o lucrare de artă a unui pictor celebru) și imaginea de intrare pe care doriți să o stilizați – și a le amesteca împreună astfel încât imaginea de intrare să fie transformată pentru a arăta ca imaginea de conținut, dar „pictată” în stilul imaginii de stil.
De exemplu, să luăm o imagine a acestei broaște țestoase și tabloul The Great Wave off Kanagawa al lui Katsushika Hokusai:
Acum cum ar arăta dacă Hokusai ar decide să adauge textura sau stilul valurilor sale la imaginea broaștei țestoase? Ceva de genul acesta?
Este vorba de magie sau doar de învățare profundă? Din fericire, acest lucru nu implică nicio magie: transferul de stil este o tehnică distractivă și interesantă care prezintă capacitățile și reprezentările interne ale rețelelor neuronale.
Principiul transferului de stil neuronal este de a defini două funcții de distanță, una care descrie cât de diferit este conținutul a două imagini, Lcontent, și una care descrie diferența dintre cele două imagini în ceea ce privește stilul lor, Lstyle. Apoi, având în vedere trei imagini, o imagine de stil dorită, o imagine de conținut dorită și imaginea de intrare (inițializată cu imaginea de conținut), încercăm să transformăm imaginea de intrare pentru a minimiza distanța de conținut față de imaginea de conținut și distanța de stil față de imaginea de stil.
În rezumat, vom lua imaginea de intrare de bază, o imagine de conținut pe care vrem să o potrivim și imaginea de stil pe care vrem să o potrivim. Vom transforma imaginea de intrare de bază prin minimizarea distanțelor (pierderilor) de conținut și de stil cu backpropagation, creând o imagine care se potrivește cu conținutul imaginii de conținut și cu stilul imaginii de stil.
În acest proces, vom acumula experiență practică și ne vom dezvolta intuiția în jurul următoarelor concepte:
- Executare nerăbdătoare – folosim mediul de programare imperativă TensorFlow care evaluează imediat operațiile
- Învățați mai multe despre execuția nerăbdătoare
- Vedeți-o în acțiune (multe dintre tutoriale pot fi rulate în Colaboratory)
- Utilizarea API-ului funcțional pentru a defini un model – vom construi un subansamblu al modelului nostru care ne va oferi acces la necesarul de activări intermediare folosind Functional API
- Valorificarea hărților de caracteristici ale unui model preinstruit – vom învăța cum să folosim modelele preinstruite și hărțile de caracteristici ale acestora
- Crearea de bucle de instruire personalizate – vom examina cum să configurăm un optimizator pentru a minimiza o anumită pierdere în raport cu parametrii de intrare
- Vom urma pașii generali pentru a realiza transferul de stil:
- Cod:
- Implementare
- Definiți reprezentările de conținut și de stil
- De ce straturile intermediare?
- Model
- Definiți și creați funcțiile noastre de pierdere (distanțele de conținut și stil)
- Pierderea de stil:
- Run Gradient Descent
- Calculează pierderea și gradienții
- Aplică și execută procesul de transfer de stil
- Ce am acoperit:
Vom urma pașii generali pentru a realiza transferul de stil:
- Vizualizarea datelor
- Prelucrarea de bază/pregătirea datelor noastre
- Stabilirea funcțiilor de pierdere
- Crearea modelului
- Optimizarea pentru funcția de pierdere
Adresă: Acest post se adresează utilizatorilor intermediari care se simt confortabil cu conceptele de bază ale învățării automate. Pentru a profita la maxim de această postare, ar trebui:
- Citiți lucrarea lui Gatys – vom explica pe parcurs, dar lucrarea va oferi o înțelegere mai amănunțită a sarcinii
- Înțelegeți coborârea gradientului
Timp estimat: 60 min
Cod:
Codul complet pentru acest articol îl puteți găsi la acest link. Dacă doriți să parcurgeți pas cu pas acest exemplu, puteți găsi colab. aici.
Implementare
Vom începe prin a activa execuția nerăbdătoare. Executarea nerăbdătoare ne permite să lucrăm prin această tehnică în modul cel mai clar și mai ușor de citit.

Definiți reprezentările de conținut și de stil
Pentru a obține atât reprezentările de conținut, cât și cele de stil ale imaginii noastre, ne vom uita la unele straturi intermediare din cadrul modelului nostru. Straturile intermediare reprezintă hărți de caracteristici care devin din ce în ce mai bine ordonate pe măsură ce avansăm în adâncime. În acest caz, folosim arhitectura de rețea VGG19, o rețea de clasificare a imaginilor pregătită în prealabil. Aceste straturi intermediare sunt necesare pentru a defini reprezentarea conținutului și a stilului din imaginile noastre. Pentru o imagine de intrare, vom încerca să potrivim reprezentările țintă corespunzătoare stilului și conținutului la aceste straturi intermediare.
De ce straturile intermediare?
S-ar putea să vă întrebați de ce aceste ieșiri intermediare din cadrul rețelei noastre de clasificare a imaginilor preinstruite ne permit să definim reprezentările stilului și conținutului. La un nivel înalt, acest fenomen poate fi explicat prin faptul că, pentru ca o rețea să realizeze clasificarea imaginilor (ceea ce rețeaua noastră a fost antrenată să facă), trebuie să înțeleagă imaginea. Acest lucru implică luarea imaginii brute ca pixeli de intrare și construirea unei reprezentări interne prin transformări care transformă pixelii imaginii brute într-o înțelegere complexă a caracteristicilor prezente în imagine. Acesta este, de asemenea, parțial motivul pentru care rețelele neuronale convoluționale sunt capabile să generalizeze bine: ele sunt capabile să capteze invariantele și trăsăturile definitorii în cadrul claselor (de exemplu, pisici vs. câini) care sunt agnostice față de zgomotul de fond și alte perturbații. Astfel, undeva între momentul în care este introdusă imaginea brută și ieșirea etichetei de clasificare, modelul servește ca un extractor complex de caracteristici; prin urmare, prin accesarea straturilor intermediare, suntem capabili să descriem conținutul și stilul imaginilor de intrare.
În mod specific, vom extrage aceste straturi intermediare din rețeaua noastră:
Model
În acest caz, încărcăm VGG19 și introducem tensorul nostru de intrare în model. Acest lucru ne va permite să extragem hărțile de caracteristici (și, ulterior, reprezentările de conținut și stil) ale conținutului, stilului și imaginilor generate.
Utilizăm VGG19, așa cum se sugerează în lucrare. În plus, deoarece VGG19 este un model relativ simplu (în comparație cu ResNet, Inception etc.), hărțile de caracteristici funcționează de fapt mai bine pentru transferul de stil.
Pentru a accesa straturile intermediare corespunzătoare hărților noastre de caracteristici de stil și de conținut, obținem ieșirile corespunzătoare prin utilizarea API-ului funcțional Keras pentru a defini modelul nostru cu activările de ieșire dorite.
Cu API-ul funcțional, definirea unui model implică pur și simplu definirea intrării și a ieșirii: model = Model(inputs, outputs).
În fragmentul de cod de mai sus, vom încărca rețeaua noastră de clasificare a imaginilor preformată. Apoi vom prelua straturile de interes, așa cum am definit mai devreme. Apoi definim un model prin setarea intrărilor modelului la o imagine și a ieșirilor la ieșirile straturilor de stil și conținut. Cu alte cuvinte, am creat un model care va lua o imagine de intrare și va ieși din straturile intermediare de conținut și stil!
Definiți și creați funcțiile noastre de pierdere (distanțele de conținut și stil)
Definirea pierderii de conținut este de fapt destul de simplă. Vom transmite rețelei atât imaginea de conținut dorită, cât și imaginea noastră de intrare de bază. Aceasta va returna ieșirile stratului intermediar (din straturile definite mai sus) din modelul nostru. Apoi, luăm pur și simplu distanța euclidiană dintre cele două reprezentări intermediare ale acestor imagini.
Mai formal, pierderea de conținut este o funcție care descrie distanța de conținut dintre imaginea noastră de intrare x și imaginea noastră de conținut, p . Fie Cₙₙₙ o rețea neuronală convoluțională profundă preînvățată. Din nou, în acest caz folosim VGG19. Fie X o imagine oarecare, atunci Cₙₙ(x) este rețeaua alimentată de X. Fie Fˡᵢⱼ(x)∈ Cₙₙ(x)și Pˡᵢⱼ(x) ∈ Cₙₙ(x) descriu respectiva reprezentare intermediară a caracteristicilor rețelei cu intrările x și p la nivelul l . Apoi, descriem distanța (pierderea) de conținut în mod formal ca:
Realizăm backpropagarea în mod obișnuit astfel încât să minimizăm această pierdere de conținut. Astfel, modificăm imaginea inițială până când aceasta generează un răspuns similar într-un anumit strat (definit în content_layer) ca și imaginea originală a conținutului.
Acest lucru poate fi implementat destul de simplu. Din nou, aceasta va lua ca intrare hărțile caracteristicilor la un strat L într-o rețea alimentată de x, imaginea noastră de intrare, și p, imaginea noastră de conținut, și va returna distanța de conținut.
Pierderea de stil:
Calcularea pierderii de stil este un pic mai implicată, dar urmează același principiu, de data aceasta alimentând rețeaua noastră cu imaginea de intrare de bază și cu imaginea de stil. Cu toate acestea, în loc să comparăm ieșirile intermediare brute ale imaginii de intrare de bază și ale imaginii de stil, comparăm în schimb matricile Gram ale celor două ieșiri.
Matematic, descriem pierderea de stil a imaginii de intrare de bază, x, și a imaginii de stil, a, ca fiind distanța dintre reprezentarea stilului (matricile Gram) a acestor imagini. Descriem reprezentarea stilului unei imagini ca fiind corelația dintre diferitele răspunsuri ale filtrelor, dată de matricea Gram Gˡ, unde Gˡᵢⱼ este produsul interior dintre harta caracteristicilor vectorizate i și j din stratul l. Putem vedea că Gˡᵢⱼ generat pe harta de caracteristici pentru o anumită imagine reprezintă corelația dintre hărțile de caracteristici i și j.
Pentru a genera un stil pentru imaginea noastră de intrare de bază, efectuăm coborârea gradientului din imaginea de conținut pentru a o transforma într-o imagine care să corespundă reprezentării stilului imaginii originale. Facem acest lucru minimizând distanța medie pătratică dintre harta de corelație a caracteristicilor din imaginea stil și imaginea de intrare. Contribuția fiecărui strat la pierderea totală a stilului este descrisă de
unde Gˡᵢⱼ și Aˡᵢⱼ sunt reprezentarea stilului respectiv în stratul l al imaginii de intrare x și al imaginii stil a. Nl descrie numărul de hărți de caracteristici, fiecare având dimensiunea Ml=înălțime∗lățime. Astfel, pierderea totală a stilului în fiecare strat este
unde se ponderează contribuția pierderii fiecărui strat cu un factor wl. În cazul nostru, ponderăm fiecare strat în mod egal:
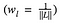
Acest lucru este implementat simplu:
Run Gradient Descent
Dacă nu sunteți familiarizați cu gradient descent/backpropagation sau dacă aveți nevoie de o reîmprospătare, ar trebui să consultați cu siguranță această resursă.
În acest caz, folosim optimizatorul Adam pentru a minimiza pierderea noastră. Actualizăm iterativ imaginea de ieșire astfel încât să ne minimizăm pierderea: nu actualizăm greutățile asociate rețelei noastre, ci, în schimb, antrenăm imaginea de intrare pentru a minimiza pierderea. Pentru a face acest lucru, trebuie să știm cum ne calculăm pierderea și gradienții. Rețineți că optimizatorul L-BFGS, care, dacă sunteți familiarizat cu acest algoritm, este recomandat, dar nu este utilizat în acest tutorial, deoarece o motivație principală din spatele acestui tutorial a fost ilustrarea celor mai bune practici cu execuția nerăbdătoare. Utilizând Adam, putem demonstra funcționalitatea benzii de autograd/gradient cu bucle de antrenare personalizate.
Calculează pierderea și gradienții
Vom defini o mică funcție ajutătoare care va încărca imaginea noastră de conținut și de stil, le va transmite prin rețeaua noastră, care va emite apoi reprezentările caracteristicilor de conținut și de stil din modelul nostru.
Aici folosim tf.GradientTape pentru a calcula gradientul. Acesta ne permite să profităm de diferențierea automată disponibilă prin operațiile de urmărire pentru a calcula ulterior gradientul. Acesta înregistrează operațiile din timpul trecerii înainte și apoi este capabil să calculeze gradientul funcției noastre de pierdere în raport cu imaginea de intrare pentru trecerea înapoi.
Apoi, calcularea gradienților este ușoară:
Aplică și execută procesul de transfer de stil
Și pentru a efectua efectiv transferul de stil:
Și asta este tot!
Să-l rulăm pe imaginea noastră cu broasca țestoasă și pe Marele val din Kanagawa a lui Hokusai:

Vezi procesul iterativ în timp:

Iată și alte exemple interesante despre ceea ce poate face transferul neuronal de stil. Verificați!
Încercați să vă creați propriile imagini!
Ce am acoperit:
- Am construit mai multe funcții de pierdere diferite și am folosit backpropagation pentru a transforma imaginea noastră de intrare pentru a minimiza aceste pierderi.
- Pentru a face acest lucru, am încărcat un model preformat și am folosit hărțile de caracteristici învățate de acesta pentru a descrie conținutul și reprezentarea stilului imaginilor noastre.
- Principalele noastre funcții de pierdere au fost în primul rând calcularea distanței în termenii acestor reprezentări diferite.
- Am implementat acest lucru cu un model personalizat și o execuție nerăbdătoare.
- Am construit modelul nostru personalizat cu API-ul funcțional.
- Executarea nerăbdătoare ne permite să lucrăm în mod dinamic cu tensori, folosind un flux de control python natural.
- Am manipulat direct tensori, ceea ce face mai ușoară depanarea și lucrul cu tensori.
Am actualizat iterativ imaginea noastră prin aplicarea regulilor de actualizare a optimizatorilor noștri folosind tf.gradient. Optimizatorul a minimizat pierderile date în raport cu imaginea noastră de intrare.
.