Nel corso degli anni molte persone hanno avuto problemi a scrivere il mio nome. Quando ero più giovane ho dato per scontato che non avessero sentito il nome “Colin”. Era piuttosto insolito dove vivevo. Negli ultimi vent’anni il nome è diventato più popolare, ma i problemi di ortografia non sono migliorati. Si è scoperto che in questi giorni c’è un altro problema: un’ortografia alternativa. Potrebbe davvero “Collin” essere comune come “Colin”? Non ci credevo.
Per fortuna la Social Security Administration tiene traccia dei nomi per data di nascita e rende questi dati liberamente disponibili, così ho potuto rispondere a questa domanda.
Come si è scoperto “Collin” ha avuto un drammatico salto di popolarità intorno alla fine del secolo, eclissando momentaneamente il (corretto, ovviamente) “Colin.”
Il grafico mostra la popolarità relativa di “Colin” rispetto a “Collin per le persone nate dal 1940. Nel 1940 circa l’85% dei due nomi usavano una sola “l”, che persisteva fino alla fine degli anni settanta; la variante con due “l” è decollata rapidamente e ha superato brevemente la versione con una sola “l” intorno al 1999, prima di scendere più in basso da allora.
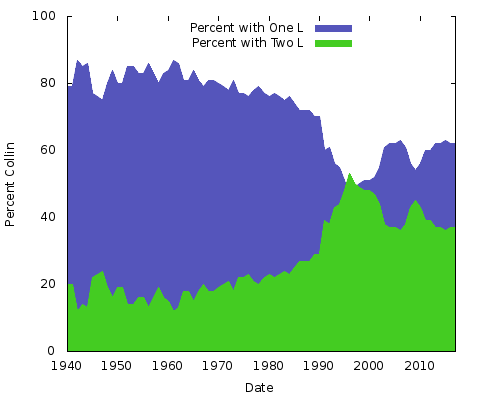
Cosa significa tutto questo? Non ne ho idea. Qualunque siano le ragioni, saranno diverse per altre coppie di nomi. Si potrebbe fare lo stesso per “Eric” contro “Erik” o “Rachel” contro “Rachael” e molti altri. In realtà, facciamo questi due:
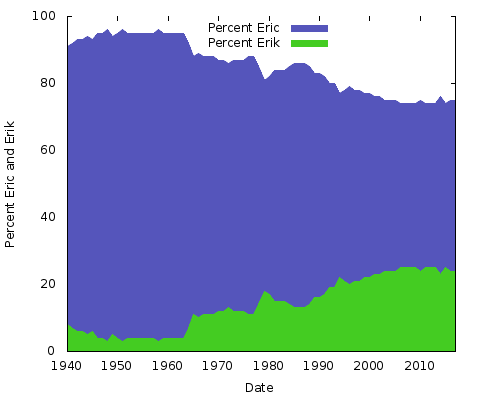
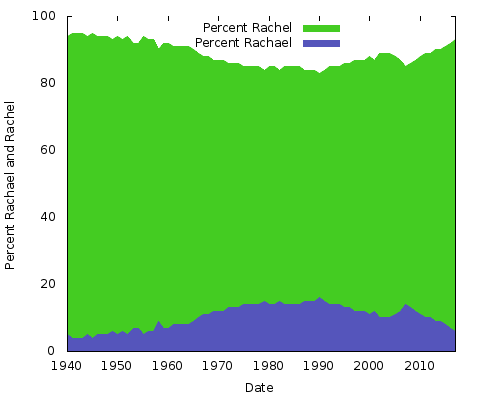
Sono semplici grafici ad area. Per questo scopo lo preferisco ad un grafico ad area impilato; con solo due linee, dove la somma dei due valori dell’asse Y ammonta sempre al 100% si finirebbe solo con la stessa linea inferiore e la metà superiore un colore solido. In questo modo si ha un’idea migliore del grande cambiamento di popolarità delle due ortografie.
Un grafico ad aree sovrapposte sarebbe ottimo per mostrare le tendenze di più di due nomi: Per esempio si potrebbe mostrare il cambiamento nel sesso associato ai nomi nel tempo con un solo nome usando un grafico come quello sopra, ma usando un’immagine si potrebbero impilare più nomi e trasmettere le stesse informazioni:
Social Security Baby Name Data
I dati provengono dal sito web della SSA dove rendono disponibili pubblicamente i primi 1000 nomi più popolari per ogni anno di nascita nei loro registri. Prima del 1940 i dati sono piuttosto scarsi, dato che l’amministrazione è stata istituita solo negli anni trenta. Si possono ancora ottenere nomi che vanno indietro fino al 1880, ma ce ne sono di meno, dato che sono incluse solo le persone che si sono iscritte negli anni trenta e oltre.
Prendi i dati su questa pagina SSA. Si trova in un archivio .zip che contiene file separati per ogni anno di nascita, e c’è una versione dei dati suddivisa per gli stati degli USA.
I dati appaiono come
Linda,F,99686Mary,F,71688Patricia,F,51278Barbara,F,48791Sandra,F,34774Carol,F,33538Nancy,F,32442Questo è dall’inizio del file del 1947.
Vorrete combinare i file dei singoli anni in uno solo e probabilmente aggiungere una colonna “Anno di nascita” (YOB) per renderne più facile l’uso per i grafici relativi al tempo. Ho scritto un piccolo script Ruby per fare il lavoro.
Per alimentare i dati con un pacchetto di grafici probabilmente avrete bisogno di massaggiare ancora un po’ i dati: Dovete trasformare le righe con un solo nome in righe con colonne per tutti i punti di dati che volete rappresentare. Questi potrebbero essere in un file o un file per linea nel grafico (Gnuplot ti permette di lavorare in questo modo, caricando più file in un grafico). Potresti farlo con Ruby o Python. Io l’ho fatto con SQL e lo strumento “Q Text-as-Data”, poi ho dato il risultato a Gnuplot.