In questo post, stiamo per imparare il web scraping con python. Usando Python faremo lo scraping di Yahoo Finance. Questa è una grande fonte di dati sul mercato azionario. Noi codificheremo uno scraper per questo. Usando questo scraper sarete in grado di raschiare i dati azionari di qualsiasi azienda da Yahoo Finance. Come sapete mi piace rendere le cose abbastanza semplici, per questo, userò anche un web scraper che aumenterà la vostra efficienza di scraping.
Perché questo strumento? Questo strumento ci aiuterà a raschiare siti web dinamici utilizzando milioni di proxy rotanti in modo da non essere bloccati. Fornisce anche una struttura di compensazione. Utilizza chrome senza intestazione per raschiare siti web dinamici.
Generalmente, il web scraping è diviso in due parti:
- Raccolta di dati facendo una richiesta HTTP
- Estrazione di dati importanti analizzando il DOM HTML
Librerie & Strumenti
- Beautiful Soup è una libreria Python per tirare fuori dati da file HTML e XML.
- Le richieste ti permettono di inviare richieste HTTP molto facilmente.
- strumento di web scraping per estrarre il codice HTML dell’URL di destinazione.
Setup
La nostra configurazione è abbastanza semplice. Basta creare una cartella e installare le richieste di Beautiful Soup &. Per creare una cartella e installare le librerie digitare i comandi sotto indicati. Sto assumendo che tu abbia già installato Python 3.x.
mkdir scraper
pip install beautifulsoup4
pip install requests
Ora, crea un file all’interno di quella cartella con qualsiasi nome tu voglia. Io sto usando scraping.py.
Prima di tutto, devi iscriverti all’API di scrapingdog. Ti fornirà 1000 crediti GRATUITI. Poi basta importare Beautiful Soup & richieste nel tuo file. come questo.
from bs4 import BeautifulSoup
import requests
Cosa stiamo andando a raschiare
Ecco la lista dei campi che estrarremo:
- Previous Close
- Open
- Bid
- Ask
- Day’s Range
- 52 Week Range
- Volume
- Avg. Volume
- Capitale di mercato
- Beta
- Rapporto PE
- EPS
- Tasso di guadagno
- Dividendo &Rendimento
- Ex-Dividendo & Data
- 1y target EST
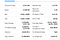
Preparazione del cibo
Ora, dato che abbiamo tutti gli ingredienti per preparare lo scraper, dovremmo fare una richiesta GET all’URL di destinazione per ottenere i dati HTML grezzi. Se non avete familiarità con lo strumento di scraping, vi invito a consultare la sua documentazione. Ora raschieremo Yahoo Finance per i dati finanziari usando la libreria di richieste come mostrato qui sotto.
r = requests.get("https://api.scrapingdog.com/scrape?api_key=<your-api-key>&url=https://finance.yahoo.com/quote/AMZN?p=AMZN&.tsrc=fin-srch").text
Questo vi fornirà un codice HTML di quell’URL di destinazione.
Ora, dovete usare BeautifulSoup per analizzare l’HTML.
soup = BeautifulSoup(r,'html.parser')
Ora, sull’intera pagina, abbiamo quattro tag “tbody”. Siamo interessati ai primi due perché attualmente non abbiamo bisogno dei dati disponibili all’interno del terzo &quarto tag “tbody”.
Primo, scopriremo tutti quei tag “tbody” usando la variabile “soup”.
alldata = soup.find_all("tbody")

Come puoi notare i primi due “tbody” hanno 8 tag “tr” e ogni tag “tr” ha due tag “td”.
try:
table1 = alldata.find_all("tr")
except:
table1=Nonetry:
table2 = alldata.find_all("tr")
except:
table2 = None
Ora, ogni tag “tr” ha due tag “td”. Il primo tag td consiste nel nome della proprietà e l’altro ha il valore di quella proprietà. È qualcosa come una coppia chiave-valore.

A questo punto, dichiareremo una lista e un dizionario prima di iniziare un ciclo for.
l={}
u=list()
Per rendere il codice semplice eseguirò due diversi cicli “for” per ogni tabella. Prima per “table1”
for i in range(0,len(table1)):
try:
table1_td = table1.find_all("td")
except:
table1_td = None l.text] = table1_td.text u.append(l)
l={}
Ora, quello che abbiamo fatto è memorizzare tutti i tag td in una variabile “table1_td”. E poi stiamo memorizzando il valore del primo &secondo tag td in un “dizionario”. Poi spingiamo il dizionario in una lista. Poiché non vogliamo memorizzare dati duplicati, alla fine renderemo il dizionario vuoto. Passi simili saranno seguiti per “table2”.
for i in range(0,len(table2)):
try:
table2_td = table2.find_all("td")
except:
table2_td = None l.text] = table2_td.text u.append(l)
l={}
Quindi alla fine quando si stampa la lista “u” si ottiene una risposta JSON.
{
"Yahoo finance":
}
Non è incredibile? Siamo riusciti a raschiare Yahoo Finance in soli 5 minuti di configurazione. Abbiamo un array di oggetti python contenente i dati finanziari della società Amazon. In questo modo, possiamo raschiare i dati da qualsiasi sito web.
Conclusione
In questo articolo, abbiamo capito come possiamo raschiare i dati usando lo strumento di raschiamento dati & BeautifulSoup indipendentemente dal tipo di sito web.
Sentitevi liberi di commentare e chiedermi qualsiasi cosa. Potete seguirmi su Twitter e Medium. Grazie per aver letto e per favore premi il pulsante “mi piace”! 👍
Risorse aggiuntive
E questo è l’elenco! A questo punto, dovresti sentirti a tuo agio nello scrivere il tuo primo web scraper per raccogliere dati da qualsiasi sito web. Qui ci sono alcune risorse aggiuntive che potresti trovare utili durante il tuo viaggio di web scraping:
- Lista di servizi proxy di web scraping
- Lista di strumenti pratici di web scraping
- Documentazione BeautifulSoup
- Documentazione Scrapingdog
- Guida al web scraping