Di Raymond Yuan, Software Engineering Intern
In questo tutorial, impareremo come usare il deep learning per comporre immagini nello stile di un’altra immagine (avete mai desiderato di poter dipingere come Picasso o Van Gogh?). Questo è noto come trasferimento di stile neurale! Si tratta di una tecnica delineata nell’articolo di Leon A. Gatys, A Neural Algorithm of Artistic Style, che è un’ottima lettura, e dovreste assolutamente darci un’occhiata.
Il trasferimento neurale dello stile è una tecnica di ottimizzazione utilizzata per prendere tre immagini, un’immagine di contenuto, un’immagine di riferimento dello stile (come un’opera d’arte di un famoso pittore), e l’immagine di input che si vuole stilizzare – e fonderle insieme in modo che l’immagine di input sia trasformata per assomigliare all’immagine di contenuto, ma “dipinta” nello stile dell’immagine dello stile.
Per esempio, prendiamo un’immagine di questa tartaruga e La grande onda al largo di Kanagawa di Katsushika Hokusai:
Ora come sarebbe se Hokusai decidesse di aggiungere la trama o lo stile delle sue onde all’immagine della tartaruga? Qualcosa del genere?
È magia o solo apprendimento profondo? Fortunatamente, non si tratta di magia: il trasferimento di stile è una tecnica divertente e interessante che mette in mostra le capacità e le rappresentazioni interne delle reti neurali.
Il principio del trasferimento di stile neurale consiste nel definire due funzioni di distanza, una che descrive quanto diverso sia il contenuto di due immagini, Lcontent, e una che descrive la differenza tra le due immagini in termini di stile, Lstyle. Poi, date tre immagini, un’immagine di stile desiderata, un’immagine di contenuto desiderata e l’immagine di input (inizializzata con l’immagine di contenuto), cerchiamo di trasformare l’immagine di input per minimizzare la distanza di contenuto con l’immagine di contenuto e la sua distanza di stile con l’immagine di stile.
In sintesi, prenderemo l’immagine di input di base, un’immagine di contenuto che vogliamo abbinare e l’immagine di stile che vogliamo abbinare. Trasformeremo l’immagine di input di base minimizzando le distanze (perdite) di contenuto e di stile con la backpropagation, creando un’immagine che corrisponde al contenuto dell’immagine di contenuto e allo stile dell’immagine di stile.
Nel processo, costruiremo esperienza pratica e svilupperemo l’intuizione intorno ai seguenti concetti:
- Eager Execution – usare l’ambiente di programmazione imperativa di TensorFlow che valuta le operazioni immediatamente
- Imparare di più sulla eager execution
- Vederla in azione (molti dei tutorial sono eseguibili in Colaboratory)
- Usare Functional API per definire un modello – costruiremo un sottoinsieme del nostro modello che ci darà accesso alle necessarie attivazioni intermedie usando l’API Funzionale
- Sfruttare le mappe delle caratteristiche di un modello preaddestrato – Impareremo come usare i modelli preaddestrati e le loro mappe delle caratteristiche
- Creare cicli di addestramento personalizzati – esamineremo come impostare un ottimizzatore per minimizzare una data perdita rispetto ai parametri di input
- Seguiremo i passi generali per eseguire il trasferimento di stile:
- Codice:
- Implementazione
- Definire le rappresentazioni di contenuto e stile
- Perché gli strati intermedi?
- Modello
- Definire e creare le nostre funzioni di perdita (distanze di contenuto e stile)
- Style Loss:
- Run Gradient Descent
- Computeranno la perdita e i gradienti
- Applicare ed eseguire il processo di trasferimento dello stile
- Cosa abbiamo fatto:
Seguiremo i passi generali per eseguire il trasferimento di stile:
- Visualizzare i dati
- Preparare i nostri dati
- Impostare le funzioni di perdita
- Creare il modello
- Ottimizzare la funzione di perdita
Audience: Questo post è orientato verso utenti intermedi che sono a loro agio con i concetti di base dell’apprendimento automatico. Per ottenere il massimo da questo post, dovreste:
- Leggere il documento di Gatys – vi spiegheremo lungo la strada, ma il documento fornirà una comprensione più approfondita del compito
- Comprendere la discesa del gradiente
Tempo stimato: 60 min
Codice:
Puoi trovare il codice completo di questo articolo a questo link. Se volete fare un passo attraverso questo esempio, potete trovare il colab qui.
Implementazione
Inizieremo abilitando l’eager execution. L’eager execution ci permette di lavorare attraverso questa tecnica nel modo più chiaro e leggibile.

Definire le rappresentazioni di contenuto e stile
Per ottenere sia le rappresentazioni di contenuto che di stile della nostra immagine, guarderemo alcuni livelli intermedi all’interno del nostro modello. I livelli intermedi rappresentano mappe di caratteristiche che diventano sempre più ordinate man mano che si va più in profondità. In questo caso, stiamo usando l’architettura di rete VGG19, una rete di classificazione delle immagini preaddestrata. Questi strati intermedi sono necessari per definire la rappresentazione del contenuto e dello stile dalle nostre immagini. Per un’immagine in ingresso, cercheremo di far corrispondere le rappresentazioni target di stile e contenuto corrispondenti a questi strati intermedi.
Perché gli strati intermedi?
Vi starete chiedendo perché queste uscite intermedie all’interno della nostra rete di classificazione di immagini preaddestrate ci permettono di definire le rappresentazioni di stile e contenuto. Ad un livello superiore, questo fenomeno può essere spiegato dal fatto che, affinché una rete possa eseguire la classificazione delle immagini (che la nostra rete è stata addestrata a fare), deve comprendere l’immagine. Questo implica prendere l’immagine grezza come pixel di input e costruire una rappresentazione interna attraverso trasformazioni che trasformano i pixel dell’immagine grezza in una comprensione complessa delle caratteristiche presenti nell’immagine. Questo è anche in parte il motivo per cui le reti neurali convoluzionali sono in grado di generalizzare bene: sono in grado di catturare le invarianze e le caratteristiche che definiscono le classi (ad esempio, gatti vs. cani) che sono agnostiche al rumore di fondo e altri disturbi. Così, da qualche parte tra il punto in cui l’immagine grezza viene immessa e l’etichetta di classificazione è in uscita, il modello serve come un estrattore di caratteristiche complesse; quindi, accedendo agli strati intermedi, siamo in grado di descrivere il contenuto e lo stile delle immagini in ingresso.
Specificamente estrarremo questi strati intermedi dalla nostra rete:
Modello
In questo caso, carichiamo VGG19, e immettiamo il nostro tensore di ingresso al modello. Questo ci permetterà di estrarre le mappe delle caratteristiche (e successivamente le rappresentazioni del contenuto e dello stile) del contenuto, dello stile e delle immagini generate.
Utilizziamo VGG19, come suggerito nel documento. Inoltre, poiché VGG19 è un modello relativamente semplice (rispetto a ResNet, Inception, ecc.) le mappe delle caratteristiche funzionano effettivamente meglio per il trasferimento dello stile.
Per accedere agli strati intermedi corrispondenti alle nostre mappe delle caratteristiche di stile e contenuto, otteniamo gli output corrispondenti utilizzando l’API funzionale di Keras per definire il nostro modello con le attivazioni di output desiderate.
Con l’API funzionale, definire un modello comporta semplicemente la definizione dell’input e dell’output: model = Model(inputs, outputs).
Nel frammento di codice di cui sopra, carichiamo la nostra rete di classificazione delle immagini preaddestrata. Poi prendiamo i livelli di interesse come abbiamo definito in precedenza. Poi definiamo un modello impostando gli input del modello su un’immagine e gli output sugli output dei livelli stile e contenuto. In altre parole, abbiamo creato un modello che prenderà in input un’immagine e in output gli strati intermedi di contenuto e stile!
Definire e creare le nostre funzioni di perdita (distanze di contenuto e stile)
La nostra definizione di perdita di contenuto è in realtà abbastanza semplice. Passeremo alla rete sia l’immagine di contenuto desiderata che la nostra immagine di base in ingresso. Questo restituirà gli output degli strati intermedi (dagli strati definiti sopra) dal nostro modello. Poi prendiamo semplicemente la distanza euclidea tra le due rappresentazioni intermedie di quelle immagini.
Più formalmente, la perdita di contenuto è una funzione che descrive la distanza del contenuto dalla nostra immagine di input x e la nostra immagine di contenuto, p . Lasciamo che Cₙₙ sia una rete neurale convoluzionale profonda pre-addestrata. Anche in questo caso usiamo VGG19. Sia X una qualsiasi immagine, allora Cₙₙ(x) è la rete alimentata da X. Sia Fˡᵢⱼ(x)∈ Cₙₙ(x)e Pˡᵢⱼ(x) ∈ Cₙₙ(x) a descrivere la rispettiva rappresentazione intermedia delle caratteristiche della rete con ingressi x e p allo strato l . Poi descriviamo la distanza di contenuto (perdita) formalmente come:
Eseguiamo la backpropagation nel solito modo in modo da minimizzare questa perdita di contenuto. Cambiamo quindi l’immagine iniziale fino a quando non genera una risposta simile in un certo strato (definito in content_layer) come l’immagine di contenuto originale.
Questo può essere implementato abbastanza semplicemente. Ancora una volta prenderà come input le mappe delle caratteristiche ad uno strato L in una rete alimentata da x, la nostra immagine di input, e p, la nostra immagine di contenuto, e restituirà la distanza del contenuto.
Style Loss:
Il calcolo della perdita di stile è un po’ più complesso, ma segue lo stesso principio, questa volta alimentando la nostra rete con l’immagine di input di base e l’immagine di stile. Tuttavia, invece di confrontare gli output intermedi grezzi dell’immagine di input di base e dell’immagine di stile, confrontiamo le matrici di Gram dei due output.
Matematicamente, descriviamo la perdita di stile dell’immagine di input di base, x, e dell’immagine di stile, a, come la distanza tra la rappresentazione di stile (le matrici di Gram) di queste immagini. Descriviamo la rappresentazione di stile di un’immagine come la correlazione tra diverse risposte del filtro date dalla matrice di Gram Gˡ, dove Gˡᵢⱼ è il prodotto interno tra la mappa vettoriale delle caratteristiche i e j nel livello l. Possiamo vedere che Gˡᵢⱼ generato sulla mappa delle caratteristiche per una data immagine rappresenta la correlazione tra le mappe delle caratteristiche i e j.
Per generare uno stile per la nostra immagine di input di base, eseguiamo una discesa a gradiente dall’immagine del contenuto per trasformarla in un’immagine che corrisponde alla rappresentazione dello stile dell’immagine originale. Lo facciamo minimizzando la distanza quadratica media tra la mappa di correlazione delle caratteristiche dell’immagine di stile e l’immagine di input. Il contributo di ogni strato alla perdita totale dello stile è descritto da
dove Gˡᵢⱼ e Aˡᵢⱼ sono le rispettive rappresentazioni di stile nello strato l dell’immagine di input x e dell’immagine di stile a. Nl descrive il numero di mappe di caratteristiche, ciascuna di dimensioni Ml=altezza∗ larghezza. Così, la perdita totale dello stile attraverso ogni strato è
dove pesiamo il contributo della perdita di ogni strato per qualche fattore wl. Nel nostro caso, pesiamo ogni strato equamente:
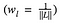
Questo è implementato semplicemente:
Run Gradient Descent
Se non avete familiarità con il gradient descent/backpropagation o avete bisogno di un ripasso, dovreste assolutamente controllare questa risorsa.
In questo caso, usiamo l’ottimizzatore Adam per minimizzare la nostra perdita. Aggiorniamo iterativamente la nostra immagine di uscita in modo che minimizzi la nostra perdita: non aggiorniamo i pesi associati alla nostra rete, ma invece addestriamo la nostra immagine di ingresso per minimizzare la perdita. Per fare questo, dobbiamo sapere come calcoliamo la nostra perdita e i gradienti. Notate che l’ottimizzatore L-BFGS, che se avete familiarità con questo algoritmo è raccomandato, ma non è usato in questo tutorial perché una motivazione primaria dietro questo tutorial era quella di illustrare le migliori pratiche con l’eager execution. Usando Adam, possiamo dimostrare la funzionalità del nastro autograd/gradiente con cicli di addestramento personalizzati.
Computeranno la perdita e i gradienti
Definiremo una piccola funzione helper che caricherà il nostro contenuto e l’immagine dello stile, li alimenterà attraverso la nostra rete, che poi produrrà le rappresentazioni delle caratteristiche di contenuto e stile dal nostro modello.
Qui usiamo tf.GradientTape per calcolare il gradiente. Ci permette di sfruttare la differenziazione automatica disponibile tracciando le operazioni per calcolare il gradiente in seguito. Registra le operazioni durante il passaggio in avanti e poi è in grado di calcolare il gradiente della nostra funzione di perdita rispetto alla nostra immagine di input per il passaggio all’indietro.
Quindi calcolare i gradienti è facile:
Applicare ed eseguire il processo di trasferimento dello stile
E per eseguire effettivamente il trasferimento dello stile:
E questo è quanto!
Eseguiamolo sulla nostra immagine della tartaruga e su La grande onda al largo di Kanagawa di Hokusai:

Guarda il processo iterativo nel tempo:

Qui ci sono altri esempi interessanti di cosa può fare il trasferimento di stile neurale. Date un’occhiata!
Prova le tue immagini!
Cosa abbiamo fatto:
- Abbiamo costruito diverse funzioni di perdita e usato la backpropagation per trasformare la nostra immagine di input al fine di minimizzare queste perdite.
- Per fare questo, abbiamo caricato un modello preaddestrato e usato le sue mappe di caratteristiche apprese per descrivere il contenuto e la rappresentazione dello stile delle nostre immagini.
- Le nostre principali funzioni di perdita erano principalmente il calcolo della distanza in termini di queste diverse rappresentazioni.
- Lo abbiamo implementato con un modello personalizzato e l’esecuzione eager.
- Abbiamo costruito il nostro modello personalizzato con l’API funzionale.
- L’eager execution ci permette di lavorare dinamicamente con i tensori, usando un flusso di controllo naturale di Python.
- Abbiamo manipolato direttamente i tensori, il che rende più facile il debug e il lavoro con i tensori.
Abbiamo aggiornato iterativamente la nostra immagine applicando le regole di aggiornamento dei nostri ottimizzatori usando tf.gradient. L’ottimizzatore ha minimizzato le perdite date rispetto alla nostra immagine di input.