Als je webapps in ontwikkeling en in productie effectief wilt kunnen beheren, moet je omgevingsvariabelen begrijpen.
Dit was niet altijd het geval. Nog maar een paar jaar geleden configureerde bijna niemand zijn Rails apps met omgevingsvariabelen. Maar toen kwam Heroku.
Heroku introduceerde ontwikkelaars tot de 12-factor app aanpak. In hun 12-factor app manifesto leggen ze veel van hun best practices uit voor het maken van apps die gemakkelijk te implementeren zijn. Vooral de sectie over omgevingsvariabelen is invloedrijk geweest.
De twaalf-factor app slaat config op in omgevingsvariabelen (vaak afgekort tot env vars of env). Env vars zijn makkelijk te veranderen tussen deploys zonder code te veranderen; in tegenstelling tot config files, is er weinig kans dat ze per ongeluk in de code repo gecheckt worden; en in tegenstelling tot custom config files, of andere config mechanismen zoals Java System Properties, zijn ze een taal- en OS-agnostische standaard.
Meer Rubyisten gebruiken omgevingsvariabelen dan ooit. Maar vaak is het op een ladingsgewijze manier. We gebruiken deze dingen zonder echt te begrijpen hoe ze werken.
Deze post zal je laten zien hoe omgevingsvariabelen echt werken – en misschien nog belangrijker, hoe ze NIET werken. We zullen ook enkele van de meest voorkomende manieren verkennen om omgevingsvariabelen in je Rails-apps te beheren. Laten we beginnen!
NOTE: Je kunt hier lezen over het beveiligen van omgevingsvariabelen.
- Elk proces heeft zijn eigen set omgevingsvariabelen
- Milieuvariabelen sterven met hun proces
- Een proces krijgt zijn omgevingsvariabelen van zijn ouder
- Parenten kunnen de omgevingsvariabelen die naar hun kinderen worden gestuurd, aanpassen
- Kinderen kunnen de omgevingsvariabelen van hun ouders niet instellen
- Veranderingen aan de omgeving worden niet gesynchroniseerd tussen draaiende processen
- Jouw shell is slechts een UI voor het omgevingsvariabele systeem.
- Omgevingsvariabelen zijn NIET hetzelfde als shellvariabelen
- Het beheren van omgevingsvariabelen in de praktijk
- Figaro
- Dotenv
- Secrets.yml?
- Plain old Linux
Elk proces heeft zijn eigen set omgevingsvariabelen
Elk programma dat je op je server draait, heeft ten minste één proces. Dat proces krijgt zijn eigen set omgevingsvariabelen. Zodra het deze heeft, kan niets buiten dat proces ze veranderen.
Een begrijpelijke fout die beginners maken, is om te denken dat omgevingsvariabelen op de een of andere manier serverbreed zijn. Diensten zoals Heroku laten het zeker lijken alsof het instellen van de omgevingsvariabelen het equivalent is van het bewerken van een config-bestand op schijf. Maar omgevingsvariabelen lijken in niets op configuratiebestanden.
Elk programma dat u op uw server uitvoert, krijgt zijn eigen set omgevingsvariabelen op het moment dat u het start.
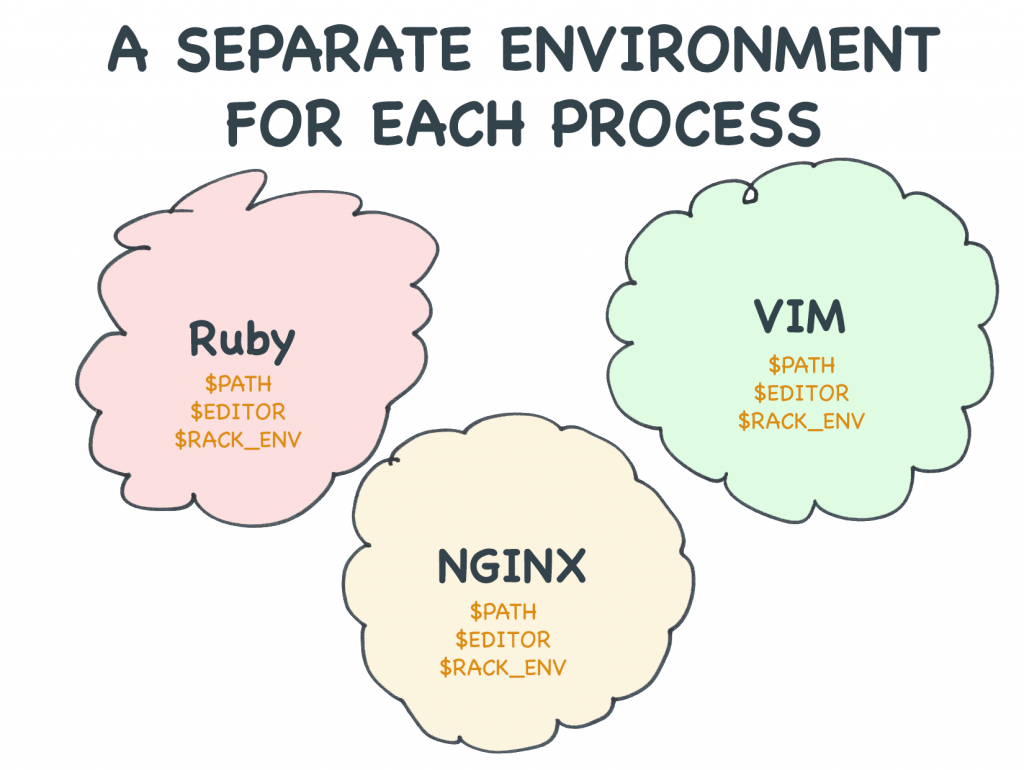 Elk proces heeft zijn eigen omgeving.
Elk proces heeft zijn eigen omgeving.
Milieuvariabelen sterven met hun proces
Heb je ooit een omgevingsvariabele ingesteld, opnieuw opgestart en ontdekt dat deze was verdwenen? Aangezien omgevingsvariabelen bij processen horen, betekent dit dat wanneer het proces stopt, je omgevingsvariabele ook weggaat.
Je kunt dit zien door een omgevingsvariabele in te stellen in een IRB sessie, deze af te sluiten, en te proberen de variabele in een 2e IRB sessie te openen.
 Wanneer een proces wordt afgesloten, gaan zijn omgevingsvariabelen verloren
Wanneer een proces wordt afgesloten, gaan zijn omgevingsvariabelen verloren
Dit is hetzelfde principe dat ervoor zorgt dat je omgevingsvariabelen verliest wanneer je server opnieuw wordt opgestart, of wanneer je je shell afsluit. Als je wilt dat ze blijven bestaan tussen sessies, moet je ze opslaan in een soort configuratiebestand zoals .bashrc .
Een proces krijgt zijn omgevingsvariabelen van zijn ouder
Elk proces heeft een ouder. Dat komt omdat elk programma moet worden gestart door een ander programma.
Als je je bash shell gebruikt om vim te starten, dan is vim’s ouder de shell. Als je Rails-app imagemagick gebruikt om een afbeelding te identificeren, dan is de ouder van het identify-programma je Rails-app.
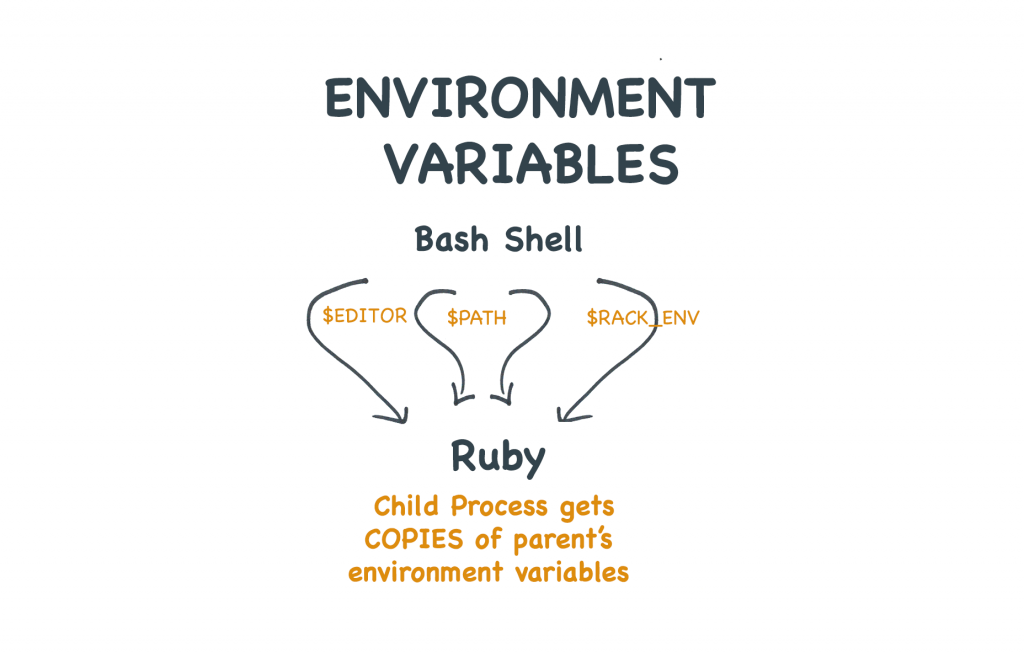 Kindprocessen erven env vars van hun ouder
Kindprocessen erven env vars van hun ouder
In het onderstaande voorbeeld stel ik de waarde van de omgevingsvariabele $MARCO in mijn IRB-proces in. Daarna gebruik ik back-ticks om de shell te verlaten en de waarde van die variabele te echoën.
Doordat IRB het ouderproces is van de shell die ik zojuist heb gemaakt, krijgt het een kopie van de $MARCO omgevingsvariabele.
 Omgevingsvariabelen die in Ruby zijn ingesteld, worden geërfd door kindprocessen
Omgevingsvariabelen die in Ruby zijn ingesteld, worden geërfd door kindprocessen
Parenten kunnen de omgevingsvariabelen die naar hun kinderen worden gestuurd, aanpassen
Standaard krijgt een kind kopieën van elke omgevingsvariabele die zijn ouder heeft. Maar de ouder heeft hier controle over.
Vanaf de commandoregel, kun je het env programma gebruiken. En in bash is er een speciale syntax om env vars op het kind in te stellen zonder ze op de ouder in te stellen.
 Gebruik het env commando om omgevingsvariabelen op een kind in te stellen zonder ze op de ouder in te stellen
Gebruik het env commando om omgevingsvariabelen op een kind in te stellen zonder ze op de ouder in te stellen
Als je vanuit Ruby shells uitvoert, kun je ook aangepaste omgevingsvariabelen aan het kindproces geven zonder je ENV hash te vervuilen. Gebruik gewoon de volgende syntaxis met de system methode:
 Hoe u aangepaste omgevingsvariabelen kunt doorgeven aan Ruby’s systeemmethode
Hoe u aangepaste omgevingsvariabelen kunt doorgeven aan Ruby’s systeemmethode
Kinderen kunnen de omgevingsvariabelen van hun ouders niet instellen
Omdat kinderen alleen kopieën krijgen van de omgevingsvariabelen van hun ouders, hebben wijzigingen die door het kind worden aangebracht geen effect op de ouder.
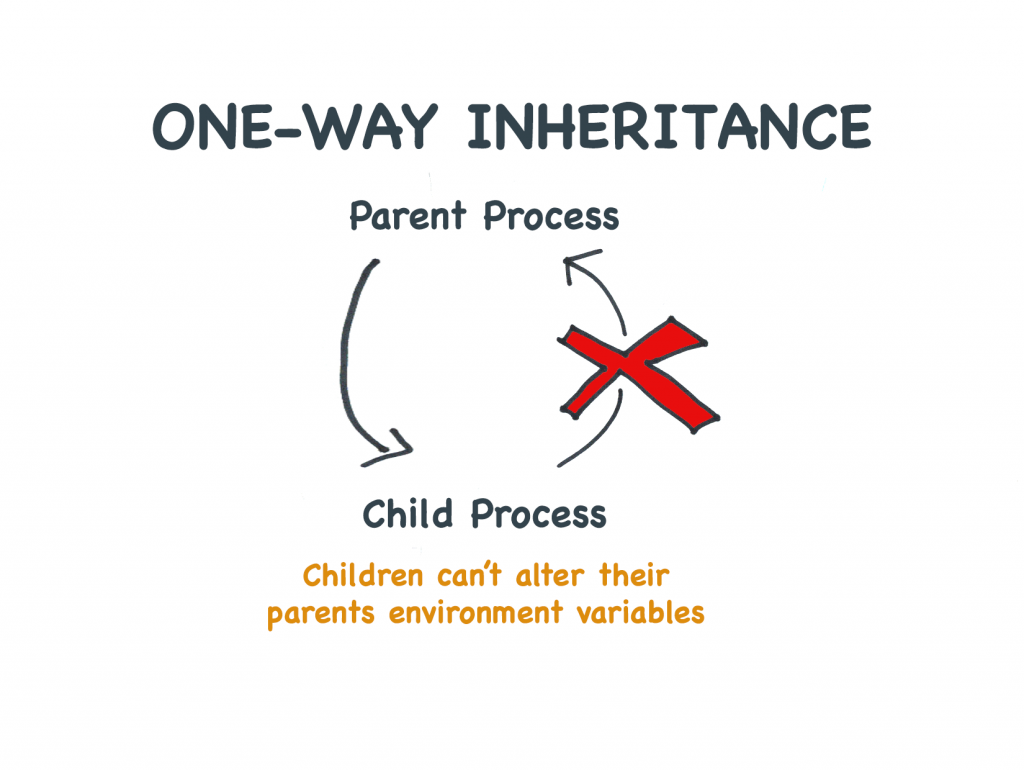 Milieuvariabelen worden “by value” doorgegeven, niet “by reference”
Milieuvariabelen worden “by value” doorgegeven, niet “by reference”
Hier gebruiken we de back-tick syntaxis om uit te schelpen en te proberen een omgevingsvariabele in te stellen. Hoewel de variabele wordt ingesteld voor het kind, borrelt de nieuwe waarde niet op naar de ouder
 Kindprocessen kunnen de omgevingsvariabelen van hun ouders niet wijzigen
Kindprocessen kunnen de omgevingsvariabelen van hun ouders niet wijzigen
Veranderingen aan de omgeving worden niet gesynchroniseerd tussen draaiende processen
In het onderstaande voorbeeld draai ik twee kopieën van IRB naast elkaar. Het toevoegen van een variabele aan de omgeving van de ene IRB sessie heeft geen effect op de andere IRB sessie.
 Een omgevingsvariabele toevoegen aan een proces verandert niets voor andere processen
Een omgevingsvariabele toevoegen aan een proces verandert niets voor andere processen
Jouw shell is slechts een UI voor het omgevingsvariabele systeem.
Het systeem zelf is onderdeel van de OS kernel. Dat betekent dat de shell geen magische macht heeft over omgevingsvariabelen. Het moet dezelfde regels volgen als elk ander programma dat je draait.
Omgevingsvariabelen zijn NIET hetzelfde als shellvariabelen
Eén van de grootste misverstanden gebeurt omdat shells wel hun eigen “lokale” shellvariabele-systemen bieden. De syntaxis voor het gebruik van lokale variabelen is vaak hetzelfde als voor omgevingsvariabelen. En beginners verwarren vaak de twee.
Maar lokale variabelen worden niet gekopieerd naar de children.
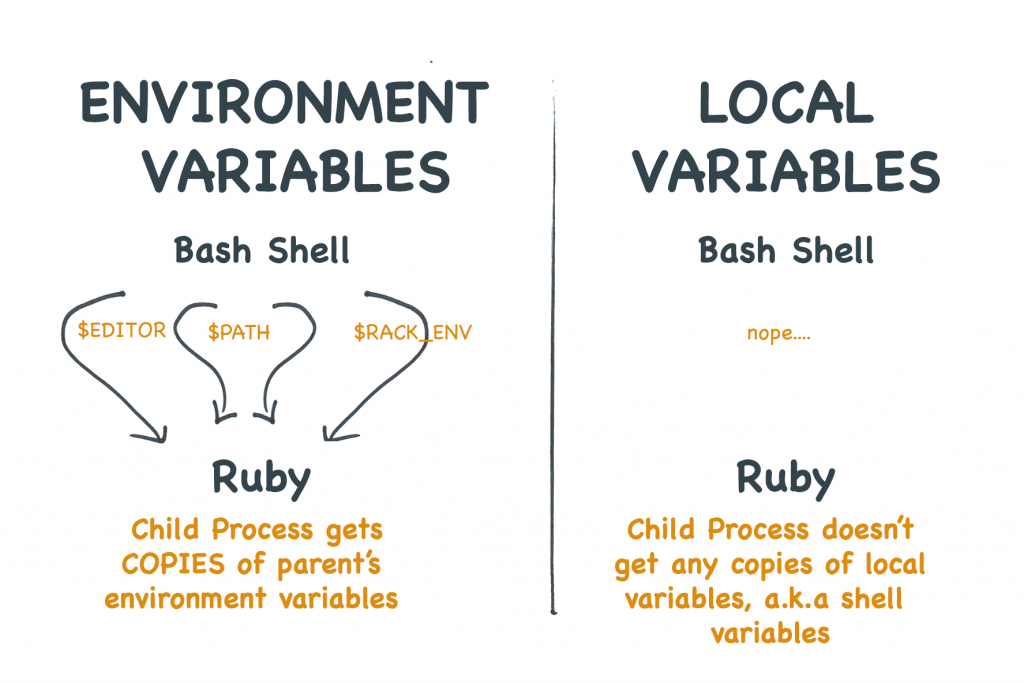 Omgevingsvariabelen zijn niet hetzelfde als shellvariabelen
Omgevingsvariabelen zijn niet hetzelfde als shellvariabelen
Laten we eens kijken naar een voorbeeld. Eerst stel ik een lokale shell variabele in met de naam MARCO. Omdat dit een lokale variabele is, wordt hij niet gekopieerd naar een kindproces. Als gevolg daarvan, wanneer ik het probeer af te drukken via Ruby, werkt het niet.
Naar aanleiding hiervan, gebruik ik het export commando om de lokale variabele om te zetten in een omgevingsvariabele. Nu wordt het gekopieerd naar elk nieuw proces dat deze commandoregel aanmaakt. Nu is de omgevingsvariabele beschikbaar voor Ruby.
 Lokale variabelen zijn niet beschikbaar voor kinderprocessen. Export converteert de lokale variabele naar een omgevingsvariabele.
Lokale variabelen zijn niet beschikbaar voor kinderprocessen. Export converteert de lokale variabele naar een omgevingsvariabele.
Het beheren van omgevingsvariabelen in de praktijk
Hoe werkt dit allemaal in de echte wereld? Laten we een voorbeeld doen:
Stel dat je twee Rails applicaties hebt draaien op een enkele computer. U gebruikt Honeybadger om deze apps te controleren op uitzonderingen. Maar je bent tegen een probleem aangelopen.
Je wilt je Honeybadger API-sleutel opslaan in de omgevingsvariabele $HONEYBADGER_API_KEY. Maar je twee apps hebben twee verschillende API-sleutels.
Hoe kan één omgevingsvariabele twee verschillende waarden hebben?
Nu hoop ik dat je het antwoord weet. Aangezien omgevingsvariabelen per proces zijn, en mijn twee rails-apps in verschillende processen worden uitgevoerd, is er geen reden waarom ze niet elk hun eigen waarde voor $HONEYBADGER_API_KEY kunnen hebben.
Nu is de enige vraag hoe je het instelt. Gelukkig zijn er een paar gems die dit heel gemakkelijk maken.
Figaro
Als je de Figaro gem in je Rails app installeert, worden alle waarden die je in config/application.yml invoert bij het opstarten in de ruby ENV hash geladen.
Je installeert de gem gewoon:
# Gemfilegem "figaro"En begint items aan application.yml toe te voegen. Het is erg belangrijk dat je dit bestand toevoegt aan je .gitignore, zodat je niet per ongeluk je secrets commit.
# config/application.ymlHONEYBADGER_API_KEY: 12345Dotenv
De dotenv gem lijkt erg op Figaro, behalve dat het omgevingsvariabelen laadt vanuit .env, en het gebruikt geen YAML.
Installeer gewoon de gem:
# Gemfilegem 'dotenv-rails'En voeg je configuratiewaarden toe aan .env – en zorg ervoor dat je het bestand git ignore zodat je het niet per ongeluk publiceert op github.
HONEYBADGER_API_KEY=12345U kunt dan de waarden in uw Ruby ENV hash
ENVU kunt ook commando’s in de shell uitvoeren met uw voorgedefinieerde set van env vars zoals dit:
dotenv ./my_script.shSecrets.yml?
Sorry. Secrets.yml – hoewel cool – stelt geen omgevingsvariabelen in. Dus het is niet echt een vervanging voor edelstenen zoals Figaro en dotenv.
Plain old Linux
Het is ook mogelijk om unieke sets omgevingsvariabelen per app te onderhouden met behulp van basis Linux-commando’s. Eén benadering is om elke app die op je server draait, eigendom te laten zijn van een andere gebruiker. U kunt dan de .bashrc van de gebruiker gebruiken om applicatie-specifieke waarden op te slaan.