Jeśli chcesz być w stanie efektywnie zarządzać aplikacjami webowymi w rozwoju i na produkcji, musisz zrozumieć zmienne środowiskowe.
Nie zawsze tak było. Jeszcze kilka lat temu mało kto konfigurował swoje aplikacje Rails za pomocą zmiennych środowiskowych. Ale wtedy stało się Heroku.
Heroku wprowadziło programistów do podejścia 12-factor app. W swoim manifeście 12-factor app wyłożyli wiele swoich najlepszych praktyk tworzenia aplikacji, które są łatwe do wdrożenia. Sekcja dotycząca zmiennych środowiskowych była szczególnie wpływowa.
Aplikacja dwunastego czynnika przechowuje konfigurację w zmiennych środowiskowych (często skracanych do env vars lub env). Zmienne środowiskowe są łatwe do zmiany pomiędzy wdrożeniami bez zmiany kodu; w przeciwieństwie do plików konfiguracyjnych, jest mała szansa, że zostaną przypadkowo zarejestrowane w repo kodu; i w przeciwieństwie do niestandardowych plików konfiguracyjnych lub innych mechanizmów konfiguracyjnych takich jak Właściwości Systemowe Javy, są one standardem niezależnym od języka i systemu operacyjnego.
Więcej Rubistów używa zmiennych środowiskowych niż kiedykolwiek. Ale często dzieje się to w sposób błędny. Używamy tych rzeczy bez zrozumienia jak one działają.
Ten post pokaże wam jak zmienne środowiskowe naprawdę działają – i co ważniejsze, jak NIE działają. Zbadamy również niektóre z najczęstszych sposobów zarządzania zmiennymi środowiskowymi w twoich aplikacjach Railsowych. Zaczynajmy!
UWAGA: Możesz przeczytać o zabezpieczaniu zmiennych środowiskowych tutaj.
- Każdy proces ma swój własny zestaw zmiennych środowiskowych
- Zmienne środowiskowe umierają wraz ze swoim procesem
- Proces pobiera swoje zmienne środowiskowe od swojego rodzica
- Rodzice mogą dostosować zmienne środowiskowe wysyłane do ich dzieci
- Dzieci nie mogą ustawiać zmiennych środowiskowych swoich rodziców
- Zmiany w środowisku nie synchronizują się pomiędzy uruchomionymi procesami
- Twoja powłoka jest tylko UI dla systemu zmiennych środowiskowych.
- Zmienne środowiskowe NIE są tym samym, co zmienne powłoki
- Zarządzanie zmiennymi środowiskowymi w praktyce
- Figaro
- Dotenv
- Secrets.yml?
- Plain old Linux
Każdy proces ma swój własny zestaw zmiennych środowiskowych
Każdy program, który uruchamiasz na swoim serwerze ma przynajmniej jeden proces. Ten proces dostaje swój własny zestaw zmiennych środowiskowych. Gdy już je ma, nic poza tym procesem nie może ich zmienić.
Zrozumiałym błędem popełnianym przez początkujących jest myślenie, że zmienne środowiskowe są w jakiś sposób ogólnoserwerowe. Usługi takie jak Heroku z pewnością sprawiają wrażenie, że ustawienie zmiennych środowiskowych jest odpowiednikiem edycji pliku konfiguracyjnego na dysku. Ale zmienne środowiskowe nie są niczym takim jak pliki konfiguracyjne.
Każdy program, który uruchamiasz na swoim serwerze, dostaje swój własny zestaw zmiennych środowiskowych w momencie, gdy go uruchamiasz.
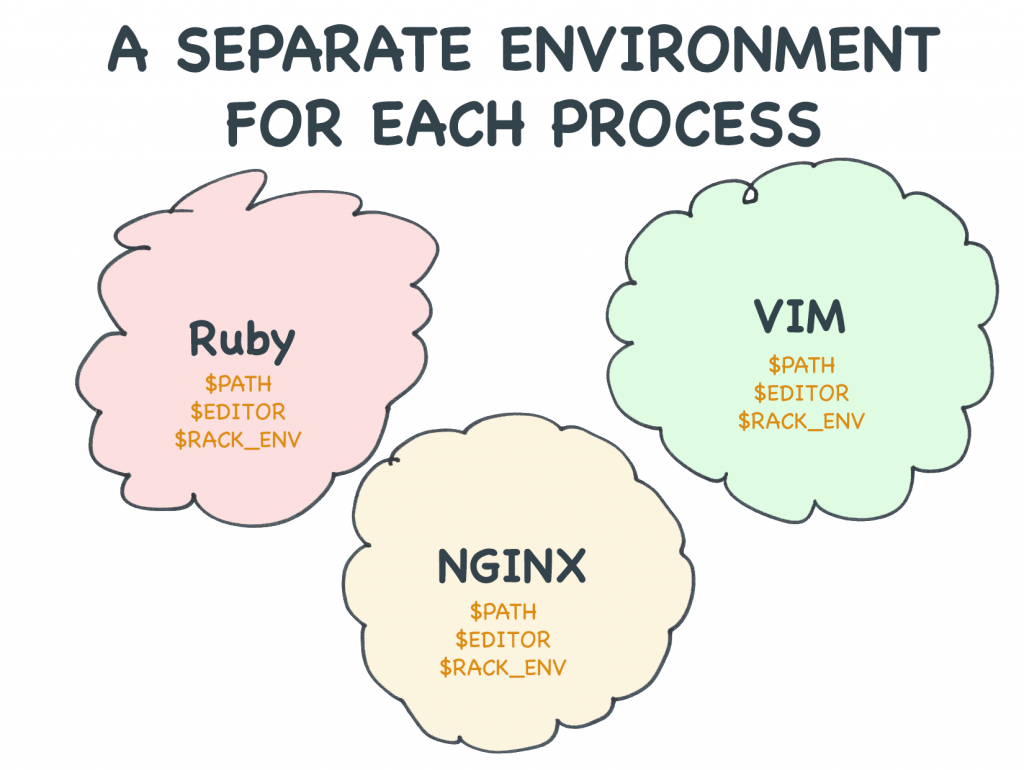 Każdy proces ma swoje własne środowisko.
Każdy proces ma swoje własne środowisko.
Zmienne środowiskowe umierają wraz ze swoim procesem
Czy kiedykolwiek ustawiłeś zmienną środowiskową, zrestartowałeś komputer i odkryłeś, że już jej nie ma? Ponieważ zmienne środowiskowe należą do procesów, oznacza to, że gdy proces kończy pracę, twoja zmienna środowiskowa znika.
Możesz się o tym przekonać ustawiając zmienną środowiskową w jednej sesji IRB, zamykając ją i próbując uzyskać dostęp do zmiennej w drugiej sesji IRB.
 Gdy proces się zamyka, jego zmienne środowiskowe są tracone
Gdy proces się zamyka, jego zmienne środowiskowe są tracone
To jest ta sama zasada, która powoduje utratę zmiennych środowiskowych, gdy twój serwer się restartuje, lub gdy wychodzisz z powłoki. Jeśli chcesz, by utrzymywały się one w sesjach, musisz przechowywać je w jakimś pliku konfiguracyjnym, takim jak .bashrc .
Proces pobiera swoje zmienne środowiskowe od swojego rodzica
Każdy proces ma rodzica. Dzieje się tak dlatego, że każdy program musi być uruchomiony przez jakiś inny program.
Jeśli używasz powłoki bash do uruchomienia vima, to rodzicem vima jest powłoka. Jeśli twoja aplikacja Rails używa imagemagick do identyfikacji obrazu, to rodzicem programu identify będzie twoja aplikacja Rails.
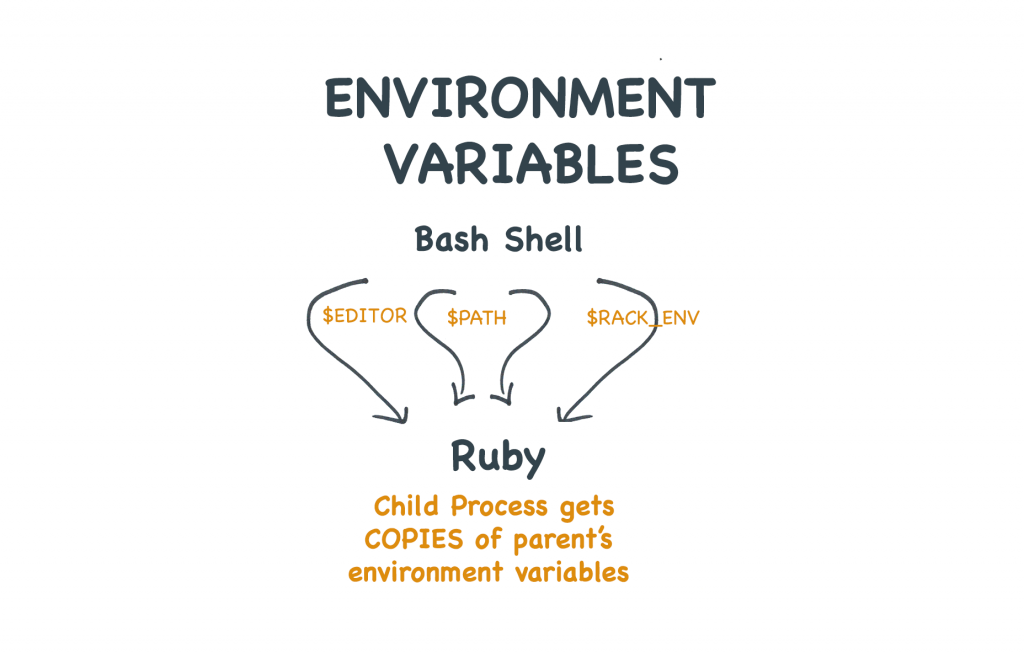 Procesy dziecięce dziedziczą env vars od swojego rodzica
Procesy dziecięce dziedziczą env vars od swojego rodzica
W poniższym przykładzie, ustawiam wartość zmiennej środowiskowej $MARCO w moim procesie IRB. Następnie używam back-ticks do wykonania shell out i echa wartości tej zmiennej.
Ponieważ IRB jest procesem rodzicielskim powłoki, którą właśnie utworzyłem, dostaje on kopię zmiennej środowiskowej $MARCO.
 Zmienne środowiskowe ustawione w Rubim są dziedziczone przez procesy-dzieci
Zmienne środowiskowe ustawione w Rubim są dziedziczone przez procesy-dzieci
Rodzice mogą dostosować zmienne środowiskowe wysyłane do ich dzieci
Domyślnie dziecko otrzymuje kopie każdej zmiennej środowiskowej, którą posiada jego rodzic. Ale rodzic ma nad tym kontrolę.
Z wiersza poleceń można użyć programu env. W bashu istnieje specjalna składnia do ustawiania zmiennych środowiskowych dla dziecka bez ustawiania ich dla rodzica.
 Użyj polecenia env aby ustawić zmienne środowiskowe dla dziecka bez ustawiania ich dla rodzica
Użyj polecenia env aby ustawić zmienne środowiskowe dla dziecka bez ustawiania ich dla rodzica
Jeśli wykonujesz powłokę z wnętrza Rubiego, możesz również dostarczyć niestandardowe zmienne środowiskowe do procesu dziecka bez zaśmiecania hasha ENV. Wystarczy użyć następującej składni z metodą system:
 Jak przekazać niestandardowe zmienne środowiskowe do metody systemowej Rubiego
Jak przekazać niestandardowe zmienne środowiskowe do metody systemowej Rubiego
Dzieci nie mogą ustawiać zmiennych środowiskowych swoich rodziców
Ponieważ dzieci otrzymują tylko kopie zmiennych środowiskowych swoich rodziców, zmiany dokonane przez dziecko nie mają wpływu na rodzica.
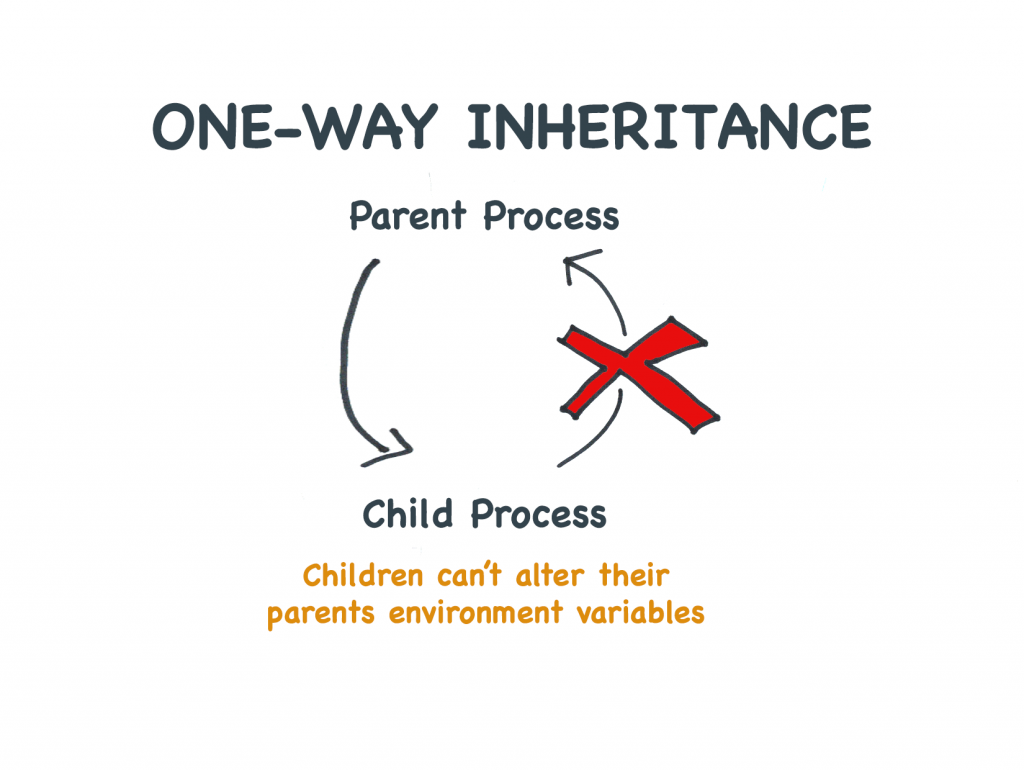 Zmienne środowiskowe są „przekazywane przez wartość”, a nie „przez referencję”
Zmienne środowiskowe są „przekazywane przez wartość”, a nie „przez referencję”
Tutaj używamy składni back-tick, aby wyłuskać i spróbować ustawić zmienną środowiskową. Podczas gdy zmienna zostanie ustawiona dla dziecka, nowa wartość nie zostanie przeniesiona do rodzica.
 Procesy dzieci nie mogą zmieniać zmiennych środowiskowych swoich rodziców
Procesy dzieci nie mogą zmieniać zmiennych środowiskowych swoich rodziców
Zmiany w środowisku nie synchronizują się pomiędzy uruchomionymi procesami
W poniższym przykładzie uruchamiam dwie kopie IRB obok siebie. Dodanie zmiennej do środowiska jednej sesji IRB nie ma żadnego wpływu na drugą sesję IRB.
 Dodanie zmiennej środowiskowej do jednego procesu nie zmienia jej dla innych procesów
Dodanie zmiennej środowiskowej do jednego procesu nie zmienia jej dla innych procesów
Twoja powłoka jest tylko UI dla systemu zmiennych środowiskowych.
Sam system jest częścią jądra OS. Oznacza to, że powłoka nie ma żadnej magicznej mocy nad zmiennymi środowiskowymi. Musi ona przestrzegać tych samych reguł, co każdy inny uruchamiany program.
Zmienne środowiskowe NIE są tym samym, co zmienne powłoki
Jednym z największych nieporozumień jest to, że powłoki zapewniają własne „lokalne” systemy zmiennych powłoki. Składnia dla używania zmiennych lokalnych jest często taka sama jak dla zmiennych środowiskowych. I początkujący często mylą te dwie rzeczy.
Ale zmienne lokalne nie są kopiowane do dzieci.
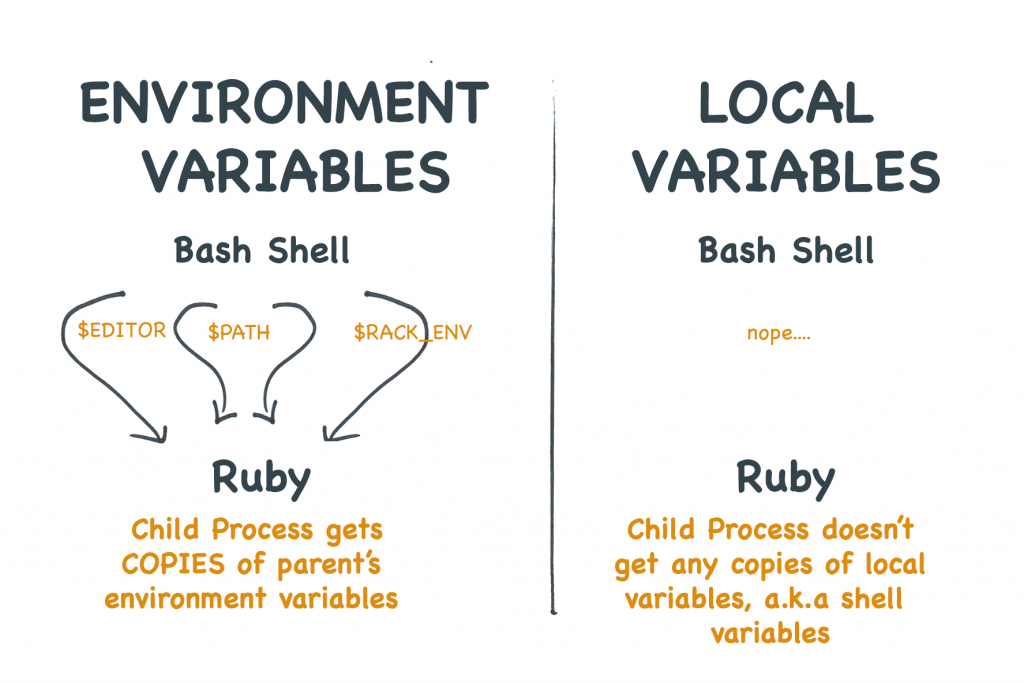 Zmienne środowiskowe nie są takie same jak zmienne powłoki
Zmienne środowiskowe nie są takie same jak zmienne powłoki
Przyjrzyjrzyjmy się przykładowi. Najpierw ustawiam lokalną zmienną powłoki o nazwie MARCO. Ponieważ jest to zmienna lokalna, nie jest ona kopiowana do żadnych procesów potomnych. W rezultacie, gdy próbuję ją wydrukować przez Ruby, nie działa.
Następnie, używam polecenia export, aby przekształcić zmienną lokalną w zmienną środowiskową. Teraz jest ona kopiowana do każdego nowego procesu tworzonego przez powłokę. Teraz zmienna środowiskowa jest dostępna dla Ruby.
 Zmienne lokalne nie są dostępne dla procesów potomnych. Eksport konwertuje zmienną lokalną na zmienną środowiskową.
Zmienne lokalne nie są dostępne dla procesów potomnych. Eksport konwertuje zmienną lokalną na zmienną środowiskową.
Zarządzanie zmiennymi środowiskowymi w praktyce
Jak to wszystko działa w prawdziwym świecie? Zróbmy przykład:
Załóżmy, że masz dwie aplikacje Rails działające na jednym komputerze. Używasz Honeybadgera do monitorowania tych aplikacji pod kątem wyjątków. Ale napotkałeś pewien problem.
Chciałbyś przechowywać klucz API Honeybadgera w zmiennej środowiskowej $HONEYBADGER_API_KEY. Ale twoje dwie aplikacje mają dwa oddzielne klucze API.
Jak jedna zmienna środowiskowa może mieć dwie różne wartości?
Mam nadzieję, że znasz już odpowiedź. Ponieważ zmienne środowiskowe są per-procesowe, a moje dwie aplikacje railsowe są uruchamiane w różnych procesach, nie ma powodu, dla którego każda z nich nie mogłaby mieć swojej własnej wartości dla $HONEYBADGER_API_KEY.
Teraz jedynym pytaniem jest jak to ustawić. Na szczęście istnieje kilka klejnotów, które sprawiają, że jest to naprawdę proste.
Figaro
Gdy zainstalujesz klejnot Figaro w swojej aplikacji Railsowej, wszelkie wartości, które wprowadzisz do config/application.yml zostaną załadowane do hasha ENV ruby podczas uruchamiania.
Po prostu zainstaluj klejnot:
# Gemfilegem "figaro"I zacznij dodawać elementy do application.yml. Bardzo ważne jest, abyś dodał ten plik do swojej .gitignore, abyś przypadkowo nie popełnił swoich sekretów.
# config/application.ymlHONEYBADGER_API_KEY: 12345Dotenv
Klejnot dotenv jest bardzo podobny do Figaro, z wyjątkiem tego, że ładuje zmienne środowiskowe z .env, i nie używa YAML.
Po prostu zainstaluj gem:
# Gemfilegem 'dotenv-rails'I dodaj swoje wartości konfiguracyjne do .env – i upewnij się, że git ignoruje plik, abyś przypadkowo nie opublikował go na github.
HONEYBADGER_API_KEY=12345Możesz wtedy uzyskać dostęp do wartości w swoim haszu Ruby ENV
ENVMożesz również uruchamiać polecenia w powłoce z predefiniowanym zestawem vars env w taki sposób:
dotenv ./my_script.shSecrets.yml?
Przepraszamy. Secrets.yml – choć fajny – nie ustawia zmiennych środowiskowych. Więc nie jest to tak naprawdę zamiennik dla klejnotów takich jak Figaro i dotenv.
Plain old Linux
Możliwe jest również utrzymanie unikalnych zestawów zmiennych środowiskowych dla każdej aplikacji używając podstawowych komend linuxowych. Jednym z podejść jest posiadanie każdej aplikacji działającej na twoim serwerze przez innego użytkownika. Możesz wtedy użyć .bashrc tego użytkownika do przechowywania wartości specyficznych dla aplikacji.