Under åren har många människor haft problem med att stava mitt namn. När jag var yngre antog jag att de inte hade hört namnet ”Colin”. Det var ganska ovanligt där jag bodde. Under de senaste tjugo åren har namnet blivit mer populärt men stavningsproblemen har inte blivit bättre. Det visar sig att det numera finns ett annat problem: en alternativ stavning. Kan ”Collin” verkligen vara lika vanligt som ”Colin”? Jag trodde inte på det.
Troligtvis håller Social Security Administration reda på förnamn efter födelsedatum och de gör dessa uppgifter fritt tillgängliga, så jag kunde besvara den frågan.
Det visade sig att ”Collin” upplevde ett dramatiskt uppsving i popularitet runt sekelskiftet 1900, och för tillfället överskuggade det (korrekta, förstås) ”Colin”.
Grafen visar den relativa populariteten av ”Colin” jämfört med ”Collin” för personer födda sedan 1940. År 1940 använde cirka 85 procent av de två namnen ett ”l”, vilket kvarstod till slutet av sjuttiotalet; varianten med två ”l” tog snabbt fart och överträffade kortvarigt den enkla ”l”-versionen runt 1999 innan den drev lägre sedan dess.
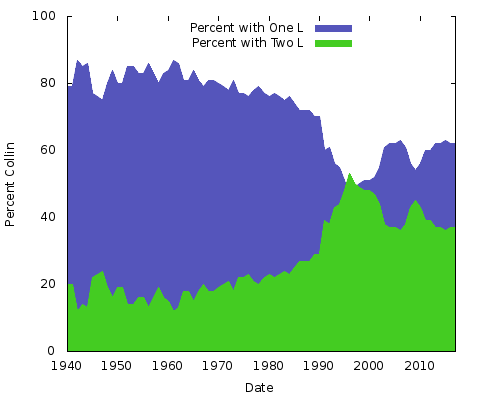
Vad betyder allt detta? Jag har ingen aning. Oavsett orsakerna kommer de att vara annorlunda för andra par av namnstavningar. Man skulle kunna göra samma sak för ”Eric” vs. ”Erik” eller ”Rachel” vs. ”Rachael” och många andra. Egentligen kan vi göra dessa två:
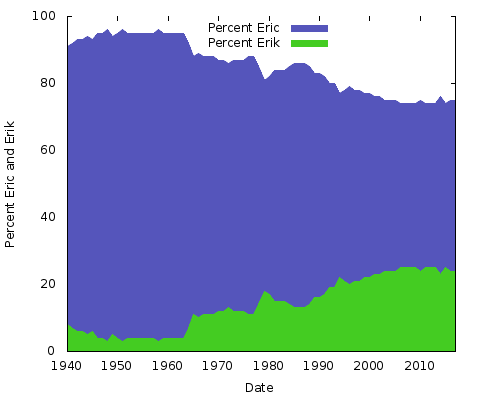
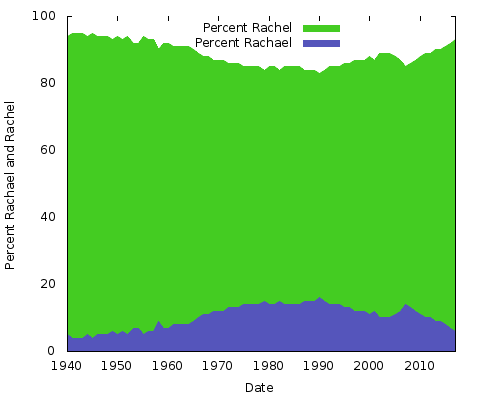
Dessa är enkla områdesdiagram. För det här ändamålet föredrar jag det framför ett staplat områdesdiagram; med bara två linjer, där summan av de två värdena på Y-axeln alltid uppgår till 100 %, skulle du bara få samma nedre linje och den övre halvan en enfärgad färg. På så sätt får man en bättre uppfattning om den stora förändringen i popularitet för de två stavningarna.
Ett staplat områdesdiagram skulle vara utmärkt för att visa trender för fler än två namn: Du kan till exempel visa förändringar i könstillhörighet i samband med namn över tid med bara ett namn med hjälp av ett diagram som det ovan, men med hjälp av en bild kan du stapla flera namn och förmedla samma information:
Social Security Baby Name Data
Data kommer från SSA:s webbplats där de gör de 1000 populäraste barnnamnen offentligt tillgängliga för varje födelseår i deras register. Före 1940 är uppgifterna ganska sparsamma, eftersom administrationen inrättades först på trettiotalet. Du kan fortfarande få fram namn som går tillbaka till 1880, men det är färre eftersom endast personer som registrerades på trettiotalet och senare finns med.
Hämta uppgifterna på denna SSA-sida. Den kommer i ett .zip-arkiv med separata filer för varje födelseår, och det finns en version av uppgifterna uppdelade efter delstater i USA.
Data ser ut som
Linda,F,99686Mary,F,71688Patricia,F,51278Barbara,F,48791Sandra,F,34774Carol,F,33538Nancy,F,32442Detta är från början av 1947 års fil.
Du kommer att vilja kombinera de enskilda årsfilerna till en och förmodligen lägga till en kolumn ”Födelseår” (YOB) för att göra det lättare att använda den för tidsrelaterade grafer. Jag skrev ett litet Ruby-skript för att göra jobbet.
För att mata data till ett grafiskt paket behöver du förmodligen massera data lite mer: Du måste omvandla raderna med ett enda namn till rader med kolumner för alla datapunkter som du vill grafera. Dessa kan finnas i en fil eller en fil per rad i grafen (Gnuplot låter dig arbeta på det sättet, genom att ladda flera filer till en graf.) Du kan göra detta med Ruby eller Python. Jag gjorde det med SQL och verktyget ”Q Text-as-Data” och matade sedan resultatet till Gnuplot.