Se vuoi essere in grado di gestire efficacemente le applicazioni web in sviluppo e in produzione, devi capire le variabili d’ambiente.
Non è sempre stato così. Solo pochi anni fa, quasi nessuno configurava le proprie applicazioni Rails con variabili d’ambiente. Ma poi è arrivato Heroku.
Heroku ha introdotto gli sviluppatori all’approccio delle app a 12 fattori. Nel loro manifesto delle app a 12 fattori, espongono molte delle loro migliori pratiche per creare app che sono facili da distribuire. La sezione sulle variabili d’ambiente è stata particolarmente influente.
L’app a dodici fattori memorizza la configurazione in variabili d’ambiente (spesso abbreviato in env vars o env). Le variabili d’ambiente sono facili da cambiare tra un deploy e l’altro senza cambiare alcun codice; a differenza dei file di configurazione, c’è poca possibilità che vengano controllate accidentalmente nel repo del codice; e a differenza dei file di configurazione personalizzati, o di altri meccanismi di configurazione come le Java System Properties, sono uno standard indipendente dalla lingua e dal sistema operativo.
Sono più numerosi che mai i rubyisti che usano le variabili d’ambiente. Ma spesso è in un modo carico di difficoltà. Usiamo queste cose senza capire veramente come funzionano.
Questo post ti mostrerà come funzionano veramente le variabili d’ambiente – e, forse più importante, come NON funzionano. Esploreremo anche alcuni dei modi più comuni di gestire le variabili d’ambiente nelle vostre applicazioni Rails. Iniziamo!
NOTA: Potete leggere come proteggere le variabili d’ambiente qui.
- Ogni processo ha il suo set di variabili d’ambiente
- Le variabili d’ambiente muoiono con il loro processo
- Un processo ottiene le sue variabili d’ambiente dal suo genitore
- I genitori possono personalizzare le variabili d’ambiente inviate ai loro figli
- I bambini non possono impostare le variabili d’ambiente dei loro genitori
- Le modifiche all’ambiente non si sincronizzano tra i processi in esecuzione
- La tua shell è solo un’interfaccia utente per il sistema delle variabili d’ambiente.
- Le variabili d’ambiente NON sono la stessa cosa delle variabili di shell
- Gestire le variabili d’ambiente in pratica
- Figaro
- Dotenv
- Secrets.yml?
- Plain old Linux
Ogni processo ha il suo set di variabili d’ambiente
Ogni programma che eseguite sul vostro server ha almeno un processo. Quel processo ha il proprio set di variabili d’ambiente. Una volta che le ha, niente al di fuori di quel processo può cambiarle.
Un errore comprensibile che i principianti fanno è pensare che le variabili d’ambiente siano in qualche modo a livello di server. Servizi come Heroku fanno sembrare che impostare le variabili d’ambiente sia l’equivalente di modificare un file di configurazione su disco. Ma le variabili d’ambiente non sono affatto come i file di configurazione.
Ogni programma che si esegue sul server ottiene il proprio set di variabili d’ambiente nel momento in cui lo si lancia.
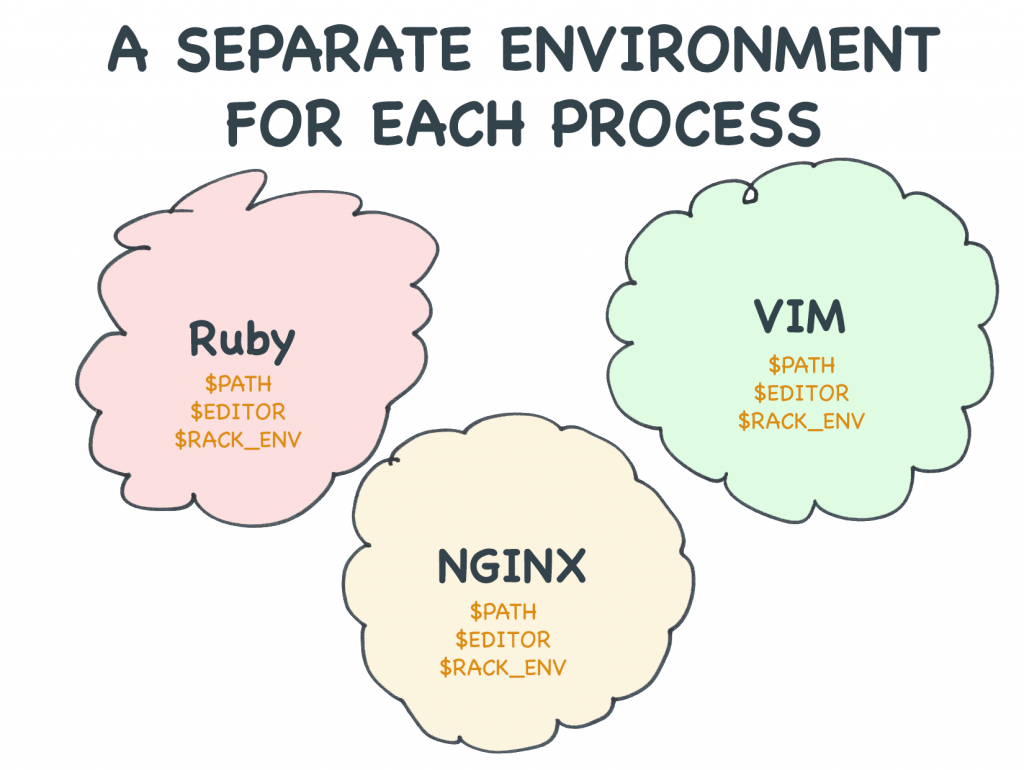 Ogni processo ha il proprio ambiente.
Ogni processo ha il proprio ambiente.
Le variabili d’ambiente muoiono con il loro processo
Hai mai impostato una variabile d’ambiente, riavviato e scoperto che era sparita? Poiché le variabili d’ambiente appartengono ai processi, ciò significa che ogni volta che il processo esce, la vostra variabile d’ambiente sparisce.
Lo potete vedere impostando una variabile d’ambiente in una sessione IRB, chiudendola, e cercando di accedere alla variabile in una seconda sessione irb.
 Quando un processo si chiude, le sue variabili d’ambiente vengono perse
Quando un processo si chiude, le sue variabili d’ambiente vengono perse
Questo è lo stesso principio che vi fa perdere le variabili d’ambiente quando il vostro server si riavvia, o quando uscite dalla vostra shell. Se volete che persistano attraverso le sessioni, dovete memorizzarle in qualche tipo di file di configurazione come .bashrc .
Un processo ottiene le sue variabili d’ambiente dal suo genitore
Ogni processo ha un genitore. Questo perché ogni programma deve essere avviato da qualche altro programma.
Se usate la vostra shell bash per lanciare vim, allora il genitore di vim è la shell. Se la vostra applicazione Rails usa imagemagick per identificare un’immagine, allora il genitore del programma identify sarà la vostra applicazione Rails.
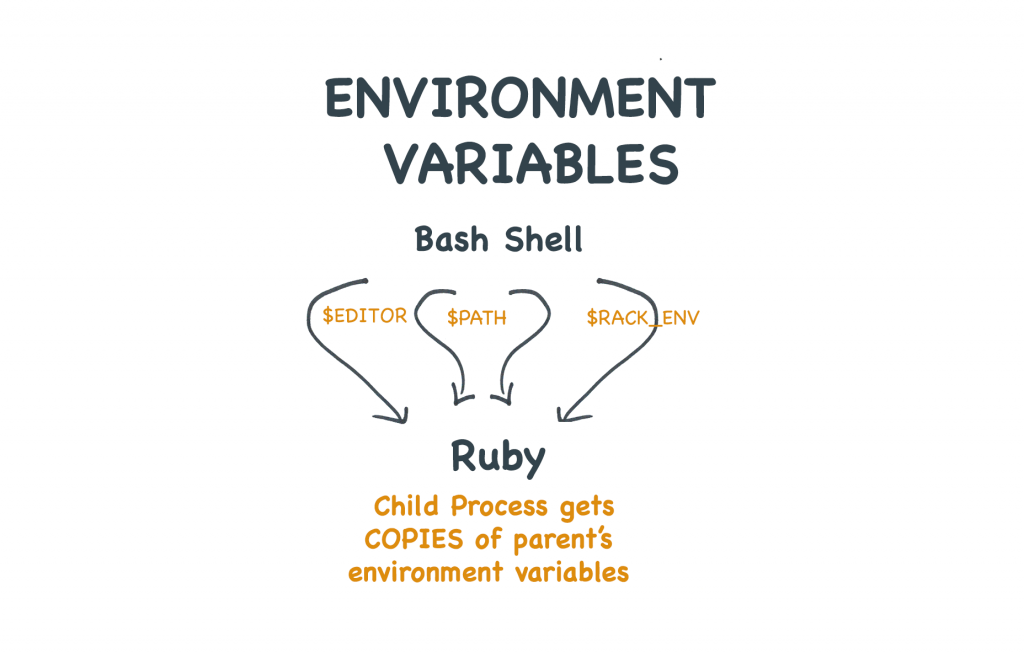 I processi figli ereditano env vars dal loro genitore
I processi figli ereditano env vars dal loro genitore
Nell’esempio sotto, sto impostando il valore della variabile d’ambiente $MARCO nel mio processo IRB. Poi uso i back-tick per fare la shell e l’echo del valore di quella variabile.
Siccome IRB è il processo padre della shell che ho appena creato, riceve una copia della variabile d’ambiente $MARCO.
 Le variabili d’ambiente impostate in Ruby sono ereditate dai processi figli
Le variabili d’ambiente impostate in Ruby sono ereditate dai processi figli
I genitori possono personalizzare le variabili d’ambiente inviate ai loro figli
Di default un figlio riceve le copie di ogni variabile d’ambiente che ha il suo genitore. Ma il genitore ha il controllo su questo.
Dalla linea di comando, si può usare il programma env. E in bash c’è una sintassi speciale per impostare le variabili d’ambiente sul bambino senza impostarle sul genitore.
 Utilizza il comando env per impostare le variabili d’ambiente per un bambino senza impostarle sul genitore
Utilizza il comando env per impostare le variabili d’ambiente per un bambino senza impostarle sul genitore
Se stai facendo lo shelling da dentro Ruby puoi anche fornire variabili d’ambiente personalizzate al processo figlio senza sporcare il tuo hash ENV. Usa semplicemente la seguente sintassi con il metodo system:
 Come passare variabili d’ambiente personalizzate nel metodo di sistema di Ruby
Come passare variabili d’ambiente personalizzate nel metodo di sistema di Ruby
I bambini non possono impostare le variabili d’ambiente dei loro genitori
Siccome i bambini ricevono solo copie delle variabili d’ambiente dei loro genitori, i cambiamenti fatti dai bambini non hanno effetto sui genitori.
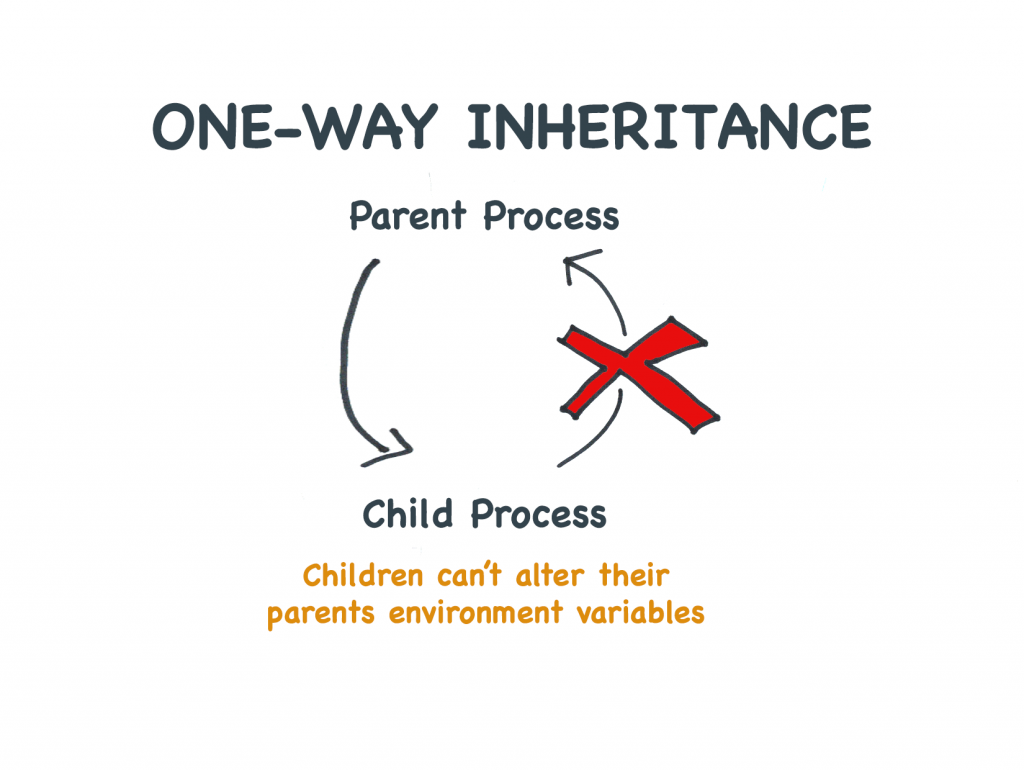 Le variabili d’ambiente sono “passate per valore” non “per riferimento”
Le variabili d’ambiente sono “passate per valore” non “per riferimento”
Qui, usiamo la sintassi back-tick per sgusciare fuori e provare a impostare una variabile d’ambiente. Mentre la variabile sarà impostata per il figlio, il nuovo valore non arriva al genitore.
 I processi figli non possono cambiare le vars d’ambiente dei genitori
I processi figli non possono cambiare le vars d’ambiente dei genitori
Le modifiche all’ambiente non si sincronizzano tra i processi in esecuzione
Nell’esempio seguente sto eseguendo due copie di IRB fianco a fianco. Aggiungere una variabile all’ambiente di una sessione IRB non ha alcun effetto sull’altra sessione IRB.
 Aggiungere una variabile d’ambiente a un processo non la cambia per gli altri processi
Aggiungere una variabile d’ambiente a un processo non la cambia per gli altri processi
La tua shell è solo un’interfaccia utente per il sistema delle variabili d’ambiente.
Il sistema stesso è parte del kernel del sistema operativo. Ciò significa che la shell non ha alcun potere magico sulle variabili d’ambiente. Deve seguire le stesse regole di ogni altro programma che si esegue.
Le variabili d’ambiente NON sono la stessa cosa delle variabili di shell
Uno dei più grandi malintesi avviene perché le shell forniscono i propri sistemi di variabili “locali”. La sintassi per usare le variabili locali è spesso la stessa delle variabili d’ambiente. E i principianti spesso confondono le due cose.
Ma le variabili locali non vengono copiate nei figli.
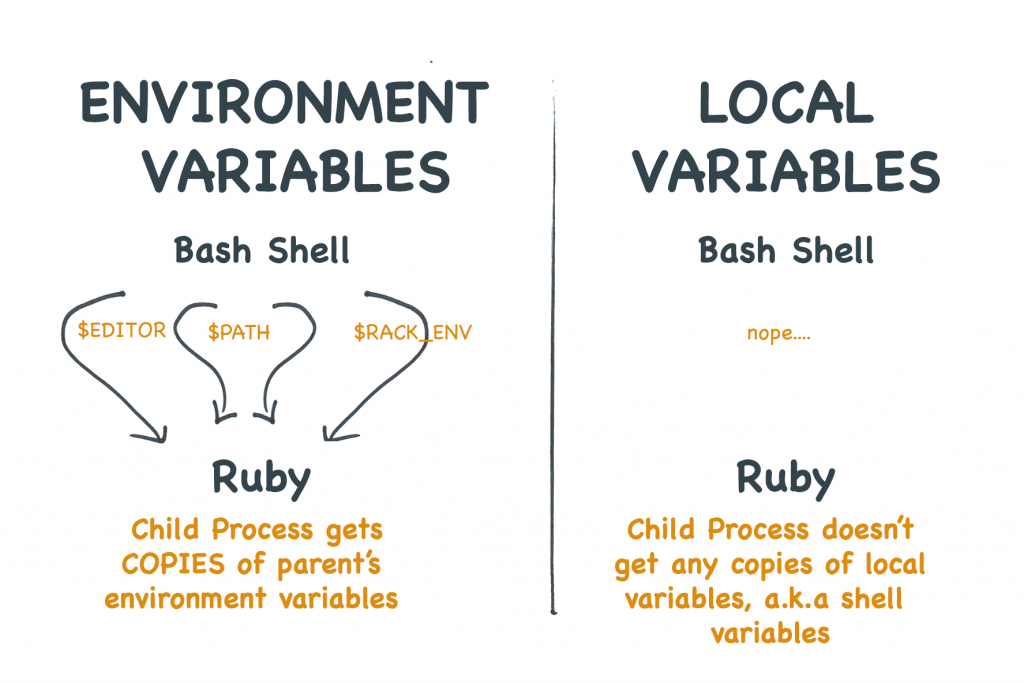 Le variabili d’ambiente non sono la stessa cosa delle variabili di shell
Le variabili d’ambiente non sono la stessa cosa delle variabili di shell
Diamo un’occhiata a un esempio. Per prima cosa ho impostato una variabile di shell locale chiamata MARCO. Poiché questa è una variabile locale, non viene copiata in nessun processo figlio. Di conseguenza, quando provo a stamparla tramite Ruby, non funziona.
Poi, uso il comando export per convertire la variabile locale in una variabile d’ambiente. Ora viene copiata in ogni nuovo processo che questa shell crea. Ora la variabile d’ambiente è disponibile per Ruby.
 Le variabili locali non sono disponibili per i processi figli. L’esportazione converte la variabile locale in una variabile d’ambiente.
Le variabili locali non sono disponibili per i processi figli. L’esportazione converte la variabile locale in una variabile d’ambiente.
Gestire le variabili d’ambiente in pratica
Come funziona tutto questo nel mondo reale? Facciamo un esempio:
Supponiamo che abbiate due applicazioni Rails in esecuzione su un singolo computer. State usando Honeybadger per monitorare queste applicazioni per le eccezioni. Ma avete incontrato un problema.
Vorreste memorizzare la vostra chiave API Honeybadger nella variabile d’ambiente $HONEYBADGER_API_KEY. Ma le vostre due applicazioni hanno due chiavi API separate.
Come può una variabile d’ambiente avere due valori diversi?
Ora spero che conosciate la risposta. Poiché le variabili d’ambiente sono per processo, e le mie due applicazioni su rotaia sono eseguite in processi diversi, non c’è ragione per cui non possano avere ciascuna il proprio valore per $HONEYBADGER_API_KEY.
Ora l’unica domanda è come impostarlo. Fortunatamente ci sono alcune gemme che lo rendono davvero facile.
Figaro
Quando installate la gemma Figaro nella vostra applicazione Rails, qualsiasi valore inserito in config/application.yml sarà caricato nell’hash di ruby ENV all’avvio.
Basta installare la gemma:
# Gemfilegem "figaro"E iniziare ad aggiungere elementi ad application.yml. È molto importante che tu aggiunga questo file al tuo .gitignore, in modo da non commettere accidentalmente i tuoi segreti.
# config/application.ymlHONEYBADGER_API_KEY: 12345Dotenv
La gemma dotenv è molto simile a Figaro, tranne che carica le variabili di ambiente da .env, e non usa YAML.
Basta installare la gemma:
# Gemfilegem 'dotenv-rails'E aggiungere i valori di configurazione a .env – e assicurati di ignorare il file con git in modo da non pubblicarlo accidentalmente su github.
HONEYBADGER_API_KEY=12345Puoi quindi accedere ai valori nel tuo hash di Ruby ENV
ENVPuoi anche eseguire comandi nella shell con il tuo set predefinito di env vars così:
dotenv ./my_script.shSecrets.yml?
Scusa. Secrets.yml – anche se bello – non imposta le variabili d’ambiente. Quindi non è davvero un rimpiazzo per gemme come Figaro e dotenv.
Plain old Linux
È anche possibile mantenere insiemi unici di variabili d’ambiente per app usando comandi linux di base. Un approccio è quello di avere ogni app in esecuzione sul vostro server di proprietà di un utente diverso. È quindi possibile utilizzare il .bashrc dell’utente per memorizzare i valori specifici dell’applicazione.