Od minulého desetiletí jsme svědky toho, že se GPU stále častěji objevují v oblastech, jako je HPC (High-Performance Computing) a nejpopulárnější oblast, tedy hraní her. GPU se rok od roku zlepšují a nyní jsou schopny dělat neuvěřitelně skvělé věci, ale v posledních několika letech na sebe strhávají ještě větší pozornost díky hlubokému učení.

Jelikož modely hlubokého učení tráví při trénování velké množství času, ani výkonné CPU nebyly dostatečně efektivní, aby zvládly tolik výpočtů v daném čase, a to je oblast, kde GPU díky svému paralelismu jednoduše překonávají CPU. Než se však ponoříme do hloubky, pojďme nejprve pochopit několik věcí o GPU.
Co je to GPU?
GPU neboli „Graphics Processing Unit“ je mini verze celého počítače, ale určená pouze pro konkrétní úlohu. Na rozdíl od CPU vykonává více úloh najednou. GPU je vybaven vlastním procesorem, který je zabudován na vlastní základní desce spolu s v-ram nebo video ram, a také vhodnou tepelnou konstrukcí pro větrání a chlazení.
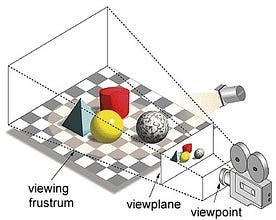
Pod pojmem „grafická procesorová jednotka“ se rozumí vykreslování obrazu na zadaných souřadnicích ve 2d nebo 3d prostoru. Viewport nebo viewpoint je perspektiva pohledu diváka na objekt v závislosti na typu použité projekce. Rasterizace a Ray-tracing jsou některé ze způsobů vykreslování 3d scén, oba tyto koncepty jsou založeny na typu projekce nazývané perspektivní projekce. Co je to perspektivní projekce?
Krátce řečeno, je to způsob, jakým se obraz vytváří na pohledové rovině nebo plátně, kde se rovnoběžné čáry sbíhají do sbíhajícího se bodu nazývaného „střed projekce“, a také jak se objekt vzdaluje od pohledu, zdá se být menší, přesně tak, jak to naše oči zobrazují v reálném světě, a to také pomáhá při chápání hloubky obrazu, což je důvod, proč vytváří realistické obrazy.
Kromě toho GPU zpracovávají také složitou geometrii, vektory, zdroje světla nebo osvětlení, textury, tvary atd. Protože nyní máme základní představu o GPU, pochopíme, proč se hojně využívá pro hluboké učení.
Proč jsou GPU lepší pro hluboké učení?
Jednou z nejobdivovanějších vlastností GPU je schopnost počítat procesy paralelně. V tomto bodě nastupuje koncept paralelních výpočtů. CPU obecně plní své úkoly sekvenčním způsobem. CPU lze rozdělit na jádra a každé jádro se zabývá vždy jednou úlohou. Předpokládejme, že procesor má 2 jádra. Pak na těchto dvou jádrech mohou běžet procesy dvou různých úloh, čímž se dosáhne multitaskingu.
Ale stále se tyto procesy vykonávají sériově.

To neznamená, že CPU nejsou dost dobré. Ve skutečnosti procesory opravdu dobře zvládají různé úlohy související s různými operacemi, jako je obsluha operačních systémů, zpracování tabulek, přehrávání HD videa, extrakce velkých souborů zip, a to vše najednou. To jsou některé věci, které GPU prostě nezvládne.
V čem spočívá rozdíl?
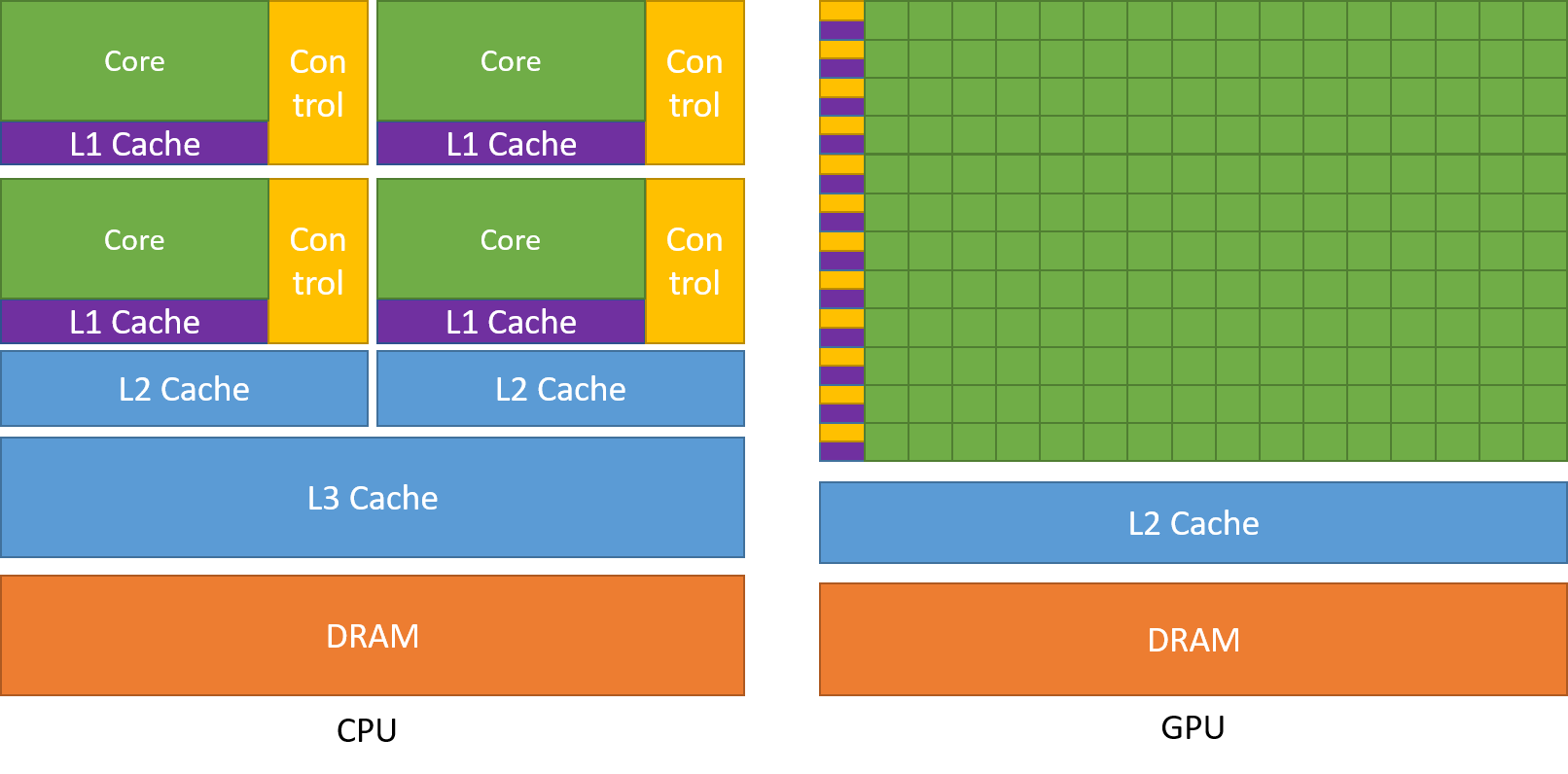
Jak již bylo řečeno, CPU je rozděleno na více jader, takže se mohou věnovat více úlohám současně, zatímco GPU bude mít stovky a tisíce jader, která se všechna věnují jedné úloze. Jedná se o jednoduché výpočty, které se provádějí častěji a jsou na sobě nezávislé. A obě ukládají často potřebná data do příslušné paměti cache, čímž dodržují princip „reference lokality“.
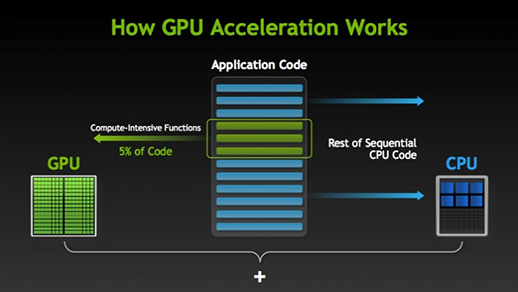
Když existuje část provádění, kterou lze provádět paralelně, jednoduše se přesune ke zpracování na GPU, kde se současně sekvenční úloha provede v CPU, a pak se obě části úlohy opět spojí dohromady.
Na trhu s GPU existují dva hlavní hráči, tj. společnosti AMD a Nvidia. Grafické procesory Nvidia jsou široce používány pro hluboké učení, protože mají rozsáhlou podporu ve fóru softwaru, ovladačů, CUDA a cuDNN. Takže pokud jde o umělou inteligenci a hluboké učení, je Nvidia dlouhodobě průkopníkem.
Říká se, že neuronové sítě jsou trapně paralelní, což znamená, že výpočty v neuronových sítích lze snadno provádět paralelně a jsou na sobě nezávislé.
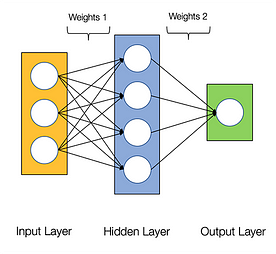
Některé výpočty, jako je výpočet vah a aktivačních funkcí jednotlivých vrstev, backpropagace, lze provádět paralelně. Existuje o tom také mnoho výzkumných prací.
GPU společnosti Nvidia jsou vybaveny specializovanými jádry známými jako jádra CUDA, která pomáhají při akceleraci hlubokého učení.
Co je CUDA?
CUDA je zkratka pro „Compute Unified Device Architecture“, která byla uvedena na trh v roce 2007, je to způsob, jakým lze dosáhnout paralelních výpočtů a optimalizovaným způsobem získat maximum z výkonu GPU, což vede k mnohem vyššímu výkonu při provádění úloh.

Sada nástrojů CUDA je kompletní balík, který se skládá z vývojového prostředí, které se používá k vytváření aplikací využívajících grafické procesory. Tato sada nástrojů obsahuje především kompilátor c/c++, ladicí program a knihovny. Také běhové prostředí CUDA má své ovladače, aby mohlo komunikovat s GPU. CUDA je také programovací jazyk, který je speciálně vytvořen pro zadávání pokynů GPU k provedení úlohy. Je také známý jako programování pro GPU.
Níže je jednoduchý program hello world jen pro představu, jak kód CUDA vypadá.
/* hello world program in cuda *\#include<stdio.h>#include<stdlib.h>#include<cuda.h>__global__ void demo() { printf("hello world!,my first cuda program");}int main() { printf("From main!\n"); demo<<<1,1>>>(); return 0;}

Co je cuDNN?

cuDNN je knihovna neuronových sítí, která je optimalizovaná pro GPU a dokáže plně využít GPU Nvidia. Tato knihovna se skládá z implementace konvoluce, dopředného a zpětného šíření, aktivačních funkcí a sdružování. Je to nepostradatelná knihovna, bez které nelze GPU pro trénování neuronových sítí použít.
Velký skok s jádry Tensor!
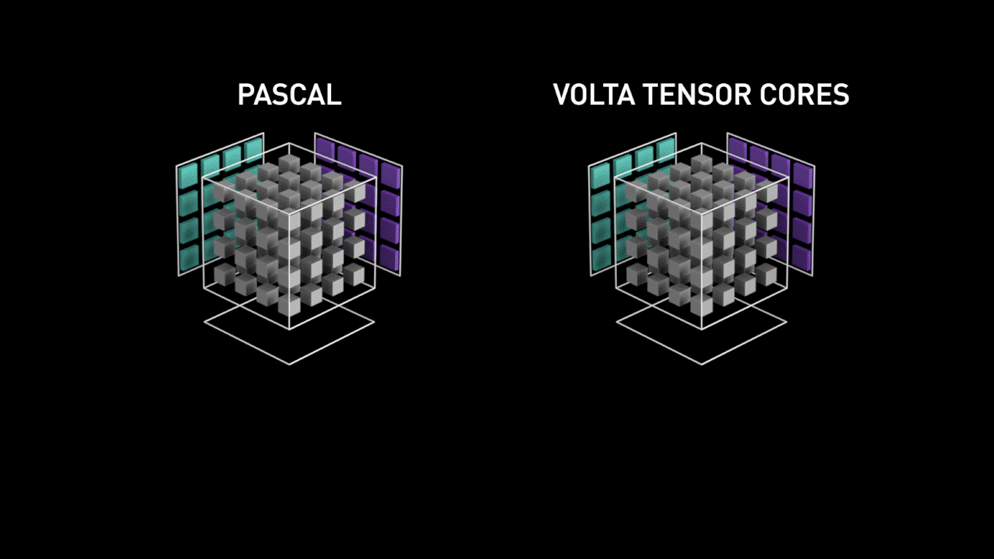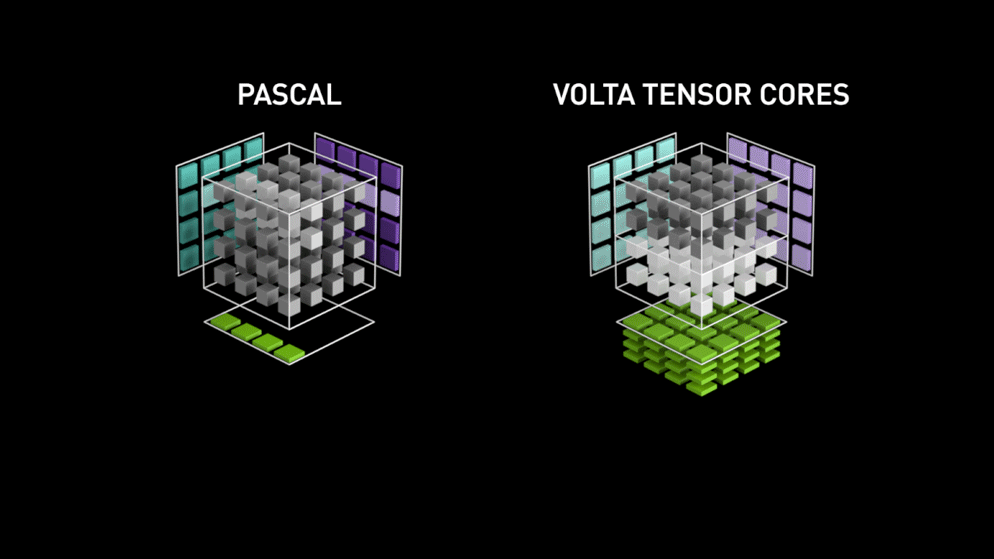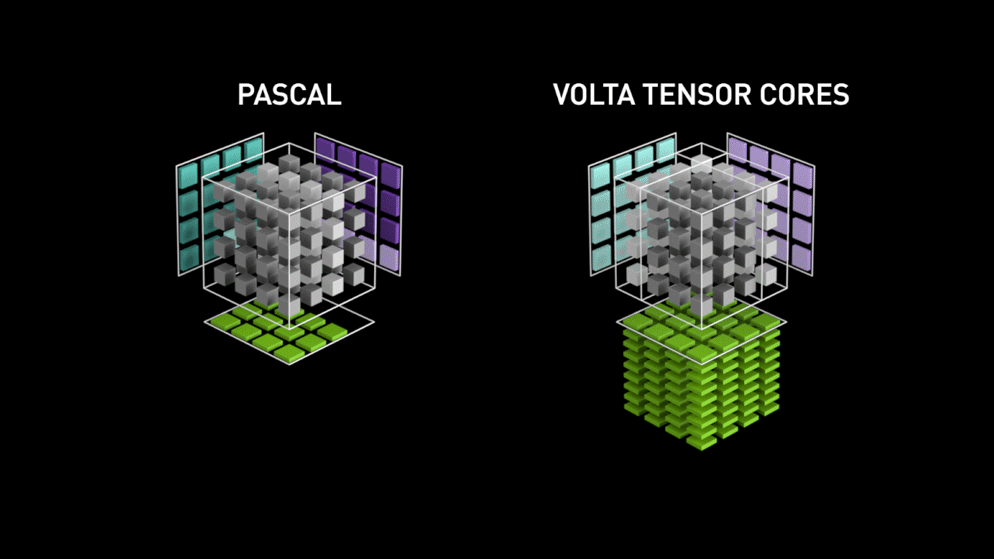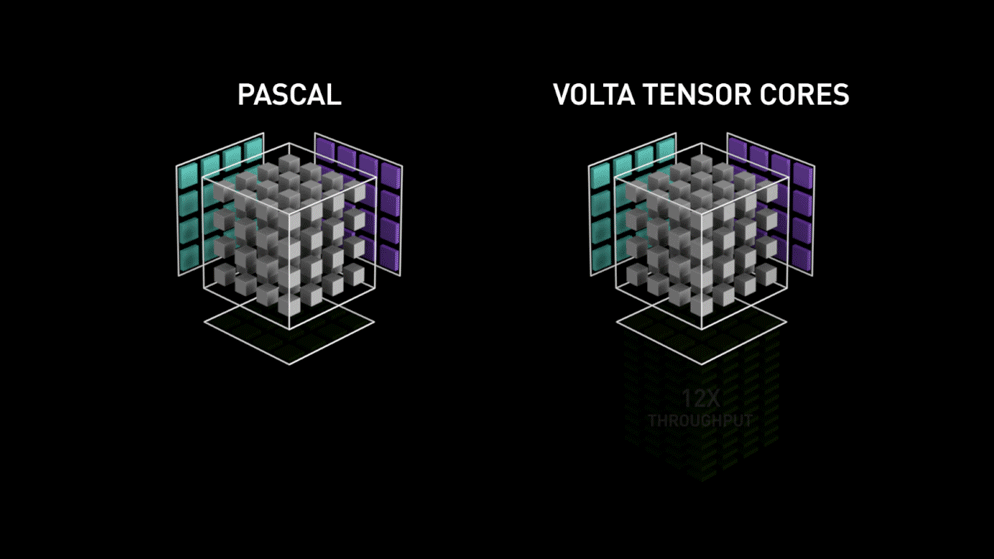
V roce 2018 uvedla společnost Nvidia na trh novou řadu svých GPU, tj. řadu 2000. Tyto karty, nazývané také RTX, jsou vybaveny tensorovými jádry, která jsou určena pro hluboké učení a jsou založena na architektuře Volta.

Tensorová jádra jsou konkrétní jádra, která provádějí maticové násobení matice 4 x 4 FP16 a sčítání s maticí 4 x 4 FP16 nebo FP32 s poloviční přesností, výstupem bude matice 4 x 4 FP16 nebo FP32 s plnou přesností.
Poznámka: „FP“ znamená floating-point (plovoucí desetinná čárka), abyste pochopili více o plovoucí desetinné čárce a přesnosti, podívejte se na tento blog.
Jak uvádí společnost Nvidia, nová generace tensorových jader založených na architektuře volta je mnohem rychlejší než jádra CUDA založená na architektuře Pascal. To dalo hlubokému učení obrovský impuls.
V době psaní tohoto blogu společnost Nvidia oznámila nejnovější řadu 3000 svých GPU, která přichází s architekturou Ampere. V ní 2x zvýšila výkon tenzorových jader. Přináší také nové hodnoty přesnosti jako TF32(tensor float 32), FP64(floating point 64). TF32 pracuje stejně jako FP32, ale se zrychlením až 20x, v důsledku toho všeho Nvidia tvrdí, že se doba inference nebo trénování modelů zkrátí z týdnů na hodiny.
AMD vs Nvidia

GPU AMD jsou slušné na hry, ale jakmile přijde na řadu hluboké učení, pak je prostě Nvidia daleko napřed. To ale neznamená, že GPU AMD jsou špatné. Je to dáno optimalizací softwaru a ovladači, které se aktivně neaktualizují, na straně Nvidie mají lepší ovladače s častými aktualizacemi a navrch CUDA, cuDNN pomáhá urychlovat výpočty.
Některé známé knihovny jako Tensorflow, PyTorch podporují CUDA. To znamená, že lze použít základní GPU řady GTX 1000. Na straně AMD je pro jejich GPU velmi malá softwarová podpora. Na straně hardwaru Nvidia představila dedikovaná tensorová jádra. AMD má pro akceleraci ROCm, ale to není tak dobré jako tensorová jádra a mnoho knihoven pro hluboké učení ROCm nepodporuje. Za posledních několik let nebyl z hlediska výkonu zaznamenán žádný velký skok.
Vzhledem ke všem těmto bodům Nvidia v hlubokém učení prostě vyniká.
Shrnutí
Na závěr ze všeho, co jsme se dozvěděli, je jasné, že od nynějška je Nvidia lídrem trhu, pokud jde o GPU, ale opravdu doufám, že i AMD ji v budoucnu dožene nebo alespoň udělá nějaká pozoruhodná zlepšení v nadcházející řadě svých GPU, protože už teď odvádí skvělou práci s ohledem na své CPU i.Ryzen.
Rozsah GPU v nadcházejících letech je obrovský, protože děláme nové inovace a průlomy v oblasti hlubokého učení, strojového učení a HPC. Akcelerace pomocí GPU se bude vždy hodit mnoha vývojářům a studentům, kteří se chtějí dostat do této oblasti, protože jejich ceny jsou také stále dostupnější. Děkujeme také široké komunitě, která také přispívá k rozvoji AI a HPC.
O autorovi

Prathmesh Patil
ML nadšenec, Data Science, Python vývojář.
LinkedIn: https://www.linkedin.com/in/prathmesh