Sinds het afgelopen decennium hebben we GPU’s steeds vaker in beeld zien komen op gebieden als HPC (High-Performance Computing) en het meest populaire gebied, namelijk gaming. GPU’s zijn jaar na jaar verbeterd en zijn nu in staat om ongelooflijk goede dingen te doen, maar de laatste paar jaar krijgen ze nog meer aandacht vanwege deep learning.

Aangezien deep learning-modellen veel tijd besteden aan training, waren zelfs krachtige CPU’s niet efficiënt genoeg om zoveel berekeningen tegelijk uit te voeren en dit is het gebied waar GPU’s simpelweg beter presteerden dan CPU’s vanwege hun parallellisme. Maar voordat we de diepte ingaan, moeten we eerst een paar dingen over GPU’s begrijpen.
Wat is de GPU?
Een GPU of ‘Graphics Processing Unit’ is een miniversie van een hele computer, maar dan alleen gewijd aan een specifieke taak. Het is anders dan een CPU die meerdere taken tegelijk uitvoert. GPU’s hebben een eigen processor die is ingebouwd op een eigen moederbord, gekoppeld aan een v-ram of video ram, en ook een goed thermisch ontwerp voor ventilatie en koeling.
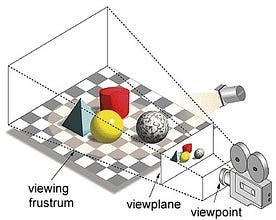
In de term “grafische verwerkingseenheid” verwijst “grafische weergave” naar het renderen van een beeld op gespecificeerde coördinaten in een 2d- of 3d-ruimte. Een viewport of viewpoint is het perspectief van een kijker die naar een object kijkt, afhankelijk van het gebruikte type projectie. Rasterisatie en Ray-tracing zijn enkele van de manieren om 3d scènes te renderen, beide concepten zijn gebaseerd op een type projectie dat perspectiefprojectie wordt genoemd. Wat is perspectief projectie?
In het kort, het is de manier waarop een beeld wordt gevormd op een beeldvlak of canvas waar de parallelle lijnen convergeren naar een convergerende punt genaamd ‘centrum van projectie’ ook als het object zich verwijdert van het gezichtspunt lijkt het kleiner te zijn, precies hoe onze ogen in de echte wereld afbeelden en dit helpt ook bij het begrijpen van diepte in een afbeelding, dat is de reden waarom het realistische beelden produceert.
Meer GPU’s verwerken ook complexe geometrie, vectoren, lichtbronnen of belichtingen, texturen, vormen, enz. Aangezien we nu een basisidee hebben over GPU, laten we begrijpen waarom het zwaar wordt gebruikt voor deep learning.
Waarom GPU’s beter zijn voor deep learning?
Een van de meest bewonderde kenmerken van een GPU is het vermogen om processen parallel te berekenen. Dit is het punt waar het concept van parallel computing zijn intrede doet. Een CPU voltooit zijn taak in het algemeen op een sequentiële manier. Een CPU kan worden onderverdeeld in cores en elke core voert één taak tegelijk uit. Stel dat een CPU 2 cores heeft. Dan kunnen twee verschillende taakprocessen op deze twee kernen draaien, waardoor multitasking wordt bereikt.
Maar toch worden deze processen op een seriële manier uitgevoerd.

Dit wil niet zeggen dat CPU’s niet goed genoeg zijn. Sterker nog, CPU’s zijn echt goed in het uitvoeren van verschillende taken met betrekking tot verschillende bewerkingen, zoals het bedienen van besturingssystemen, het verwerken van spreadsheets, het afspelen van HD-video’s, het uitpakken van grote zip-bestanden, en dat allemaal tegelijkertijd. Dit zijn enkele dingen die een GPU gewoon niet kan.
Waar ligt het verschil?
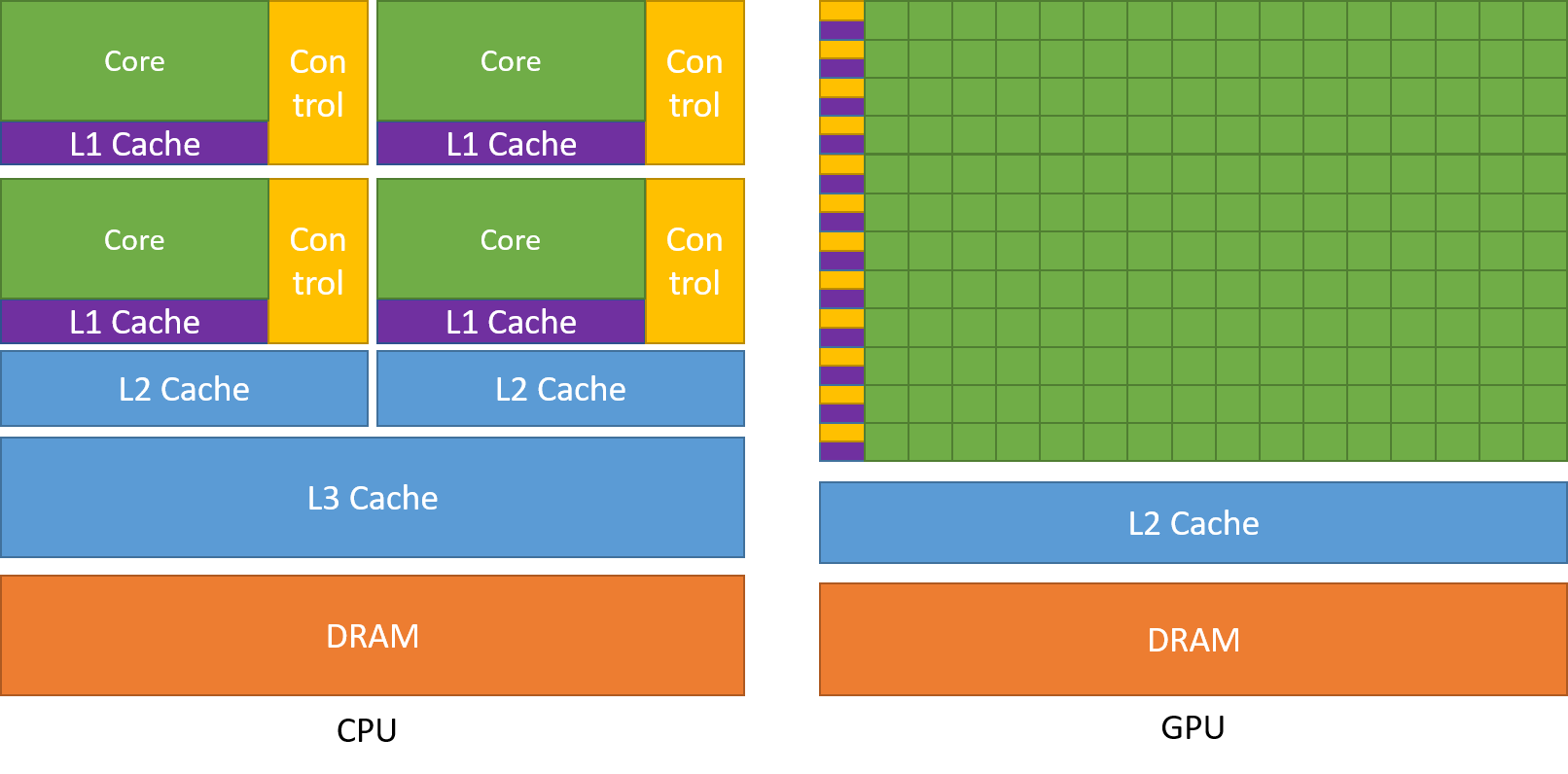
Zoals eerder besproken is een CPU verdeeld in meerdere kernen, zodat ze meerdere taken tegelijk kunnen uitvoeren, terwijl GPU’s beschikken over honderden of duizenden cores, die allemaal worden ingezet voor één enkele taak. Dit zijn eenvoudige berekeningen die vaker worden uitgevoerd en onafhankelijk zijn van elkaar. En beide slaan vaak benodigde gegevens op in hun respectieve cachegeheugen, waarbij het principe van ‘locality reference’ wordt gevolgd.
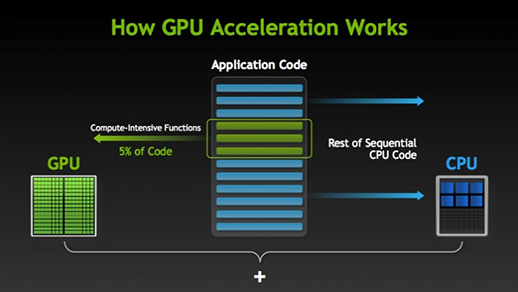
Er zijn veel software en games die voordeel kunnen halen uit GPU’s voor de uitvoering. Het idee hierachter is om sommige delen van de taak of applicatiecode parallel te maken, maar niet de volledige processen. Dit komt omdat de meeste processen van de taak alleen op sequentiële wijze moeten worden uitgevoerd. Bijvoorbeeld het inloggen op een systeem of applicatie hoeft niet parallel te worden uitgevoerd.
Wanneer een deel van de uitvoering parallel kan worden uitgevoerd, wordt dit eenvoudigweg naar de GPU overgeheveld voor verwerking, terwijl op hetzelfde moment een sequentiële taak in de CPU wordt uitgevoerd, waarna beide delen van de taak weer worden gecombineerd.
In de GPU-markt zijn er twee belangrijke spelers, AMD en Nvidia. Nvidia GPU’s worden veel gebruikt voor deep learning omdat ze uitgebreide ondersteuning hebben in de forum software, drivers, CUDA, en cuDNN. Op het gebied van AI en deep learning is Nvidia dus al lange tijd de pionier.
Van neurale netwerken wordt gezegd dat ze gênant parallel zijn, wat betekent dat berekeningen in neurale netwerken gemakkelijk parallel kunnen worden uitgevoerd en dat ze onafhankelijk van elkaar zijn.
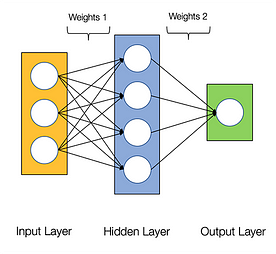
Sommige berekeningen, zoals de berekening van gewichten en activeringsfuncties van elke laag, backpropagatie, kunnen parallel worden uitgevoerd. Er zijn ook veel onderzoekspapers over beschikbaar.
Nvidia GPU’s worden geleverd met gespecialiseerde kernen die bekend staan als CUDA-kernen die helpen bij het versnellen van deep learning.
Wat is CUDA?
CUDA staat voor ‘Compute Unified Device Architecture’ die werd gelanceerd in het jaar 2007, het is een manier waarop u parallel computergebruik kunt bereiken en het meeste uit uw GPU-kracht kunt halen op een geoptimaliseerde manier, wat resulteert in veel betere prestaties tijdens het uitvoeren van taken.

De CUDA-toolkit is een compleet pakket dat bestaat uit een ontwikkelomgeving die wordt gebruikt om toepassingen te bouwen die gebruikmaken van GPU’s. Deze toolkit bevat voornamelijk c/c++ compiler, debugger, en bibliotheken. Ook heeft de CUDA runtime zijn drivers zodat het kan communiceren met de GPU. CUDA is ook een programmeertaal die specifiek is gemaakt voor het instrueren van de GPU voor het uitvoeren van een taak. Het staat ook bekend als GPU programmeren.
Hieronder staat een eenvoudig “hello world” programma om een idee te krijgen van hoe CUDA code eruit ziet.
/* hello world program in cuda *\#include<stdio.h>#include<stdlib.h>#include<cuda.h>__global__ void demo() { printf("hello world!,my first cuda program");}int main() { printf("From main!\n"); demo<<<1,1>>>(); return 0;}

Wat is cuDNN?

cuDNN is een neurale netwerkbibliotheek die GPU geoptimaliseerd is en volledig gebruik kan maken van de Nvidia GPU. Deze bibliotheek bestaat uit de implementatie van convolutie, voorwaartse en achterwaartse propagatie, activeringsfuncties, en pooling. Het is een must bibliotheek zonder welke u GPU niet kunt gebruiken voor het trainen van neurale netwerken.
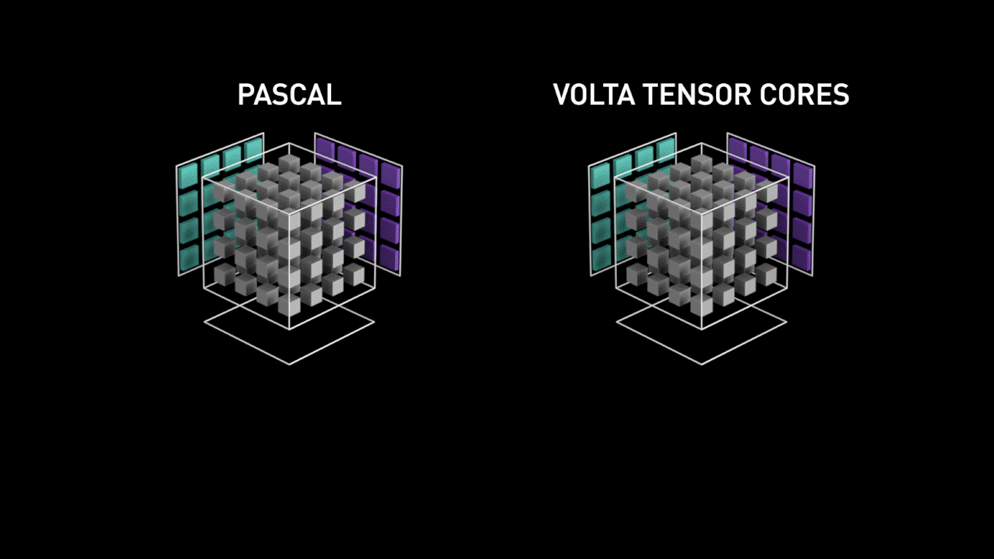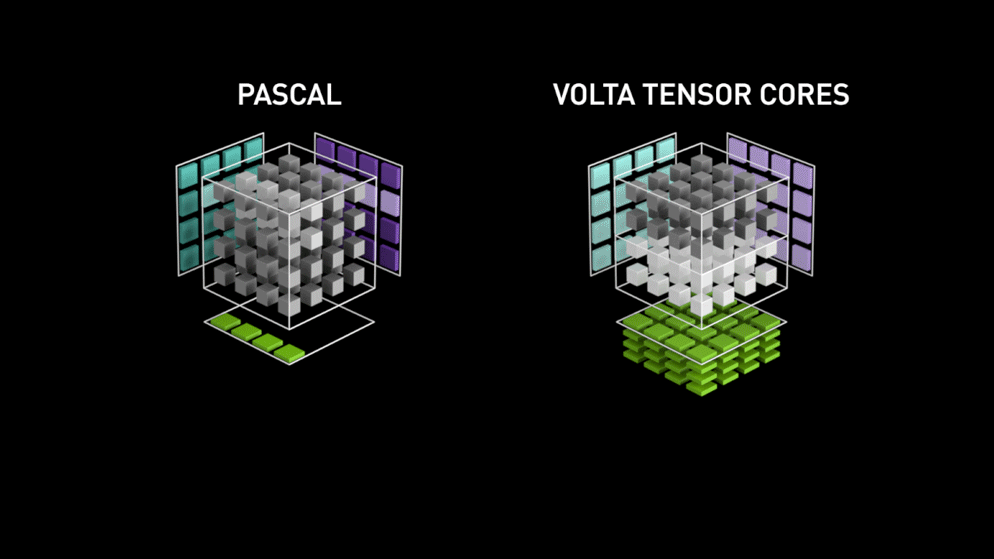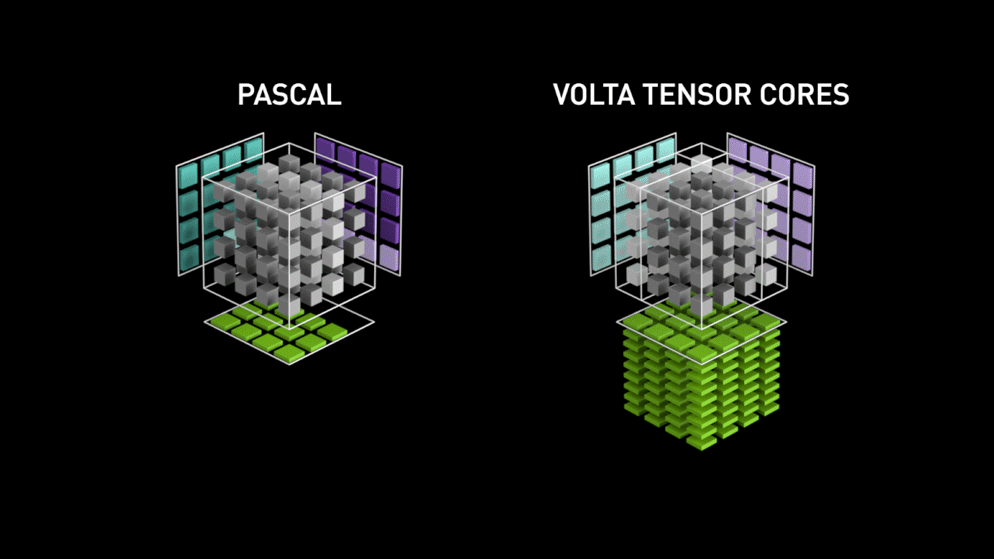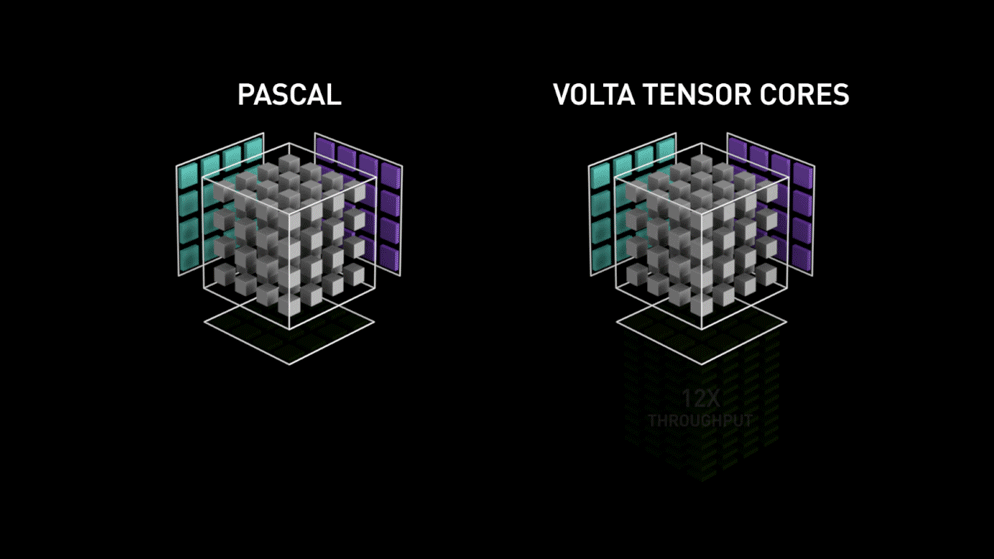
Een grote sprong met Tensor cores!
Terug in het jaar 2018 lanceerde Nvidia een nieuwe line-up van hun GPU’s, d.w.z. 2000-serie. Deze kaarten, ook RTX genoemd, worden geleverd met tensorkernen die zijn gewijd aan deep learning en zijn gebaseerd op de Volta-architectuur.

Tensor cores zijn specifieke cores die matrixvermenigvuldiging van 4 x 4 FP16 matrix en optelling met 4 x 4 matrix FP16 of FP32 in half-precisie uitvoeren, de output zal resulteren in 4 x 4 FP16 of FP32 matrix met volledige precisie.
Note: ‘FP’ staat voor floating-point om meer te begrijpen over floating-point en precisie check deze blog.
Zoals verklaard door Nvidia, is de nieuwe generatie tensor cores gebaseerd op volta architectuur veel sneller dan CUDA cores gebaseerd op Pascal architectuur. Dit gaf een enorme boost aan deep learning.
Tijdens het schrijven van deze blog kondigde Nvidia de nieuwste 3000-serie van hun GPU-reeks aan, die wordt geleverd met de Ampere-architectuur. Hierbij zijn de prestaties van de tensor cores met 2x verbeterd. Ook zijn er nieuwe precisiewaarden zoals TF32 (tensor float 32) en FP64 (floating point 64). De TF32 werkt hetzelfde als FP32 maar met een speedup tot 20x, als resultaat van dit alles claimt Nvidia dat de inferentie of trainingstijd van modellen zal worden teruggebracht van weken tot uren.
AMD vs Nvidia

AMD GPU’s zijn fatsoenlijk voor gaming, maar zodra deep learning in beeld komt, dan ligt Nvidia simpelweg ver voor. Dat wil niet zeggen dat AMD GPU’s slecht zijn. Het is te wijten aan de software-optimalisatie en drivers die niet actief wordt bijgewerkt, aan de Nvidia kant hebben ze betere drivers met frequente updates en op de top van dat CUDA, cuDNN helpt bij het versnellen van de berekening.
Enkele bekende bibliotheken zoals Tensorflow, PyTorch ondersteuning voor CUDA. Het betekent dat entry-level GPU’s van de GTX 1000-serie kunnen worden gebruikt. Aan de AMD-kant is er zeer weinig software-ondersteuning voor hun GPU’s. Aan de hardware kant heeft Nvidia speciale tensor cores geïntroduceerd. AMD heeft ROCm voor versnelling, maar het is niet goed als tensor cores, en veel deep learning bibliotheken ondersteunen ROCm niet. De afgelopen jaren werd er geen grote sprong opgemerkt in termen van prestaties.
Door al deze punten blinkt Nvidia gewoon uit in deep learning.
Samenvatting
Tot slot van alles wat we hebben geleerd is het duidelijk dat Nvidia op dit moment de marktleider is op het gebied van GPU’s, maar ik hoop echt dat zelfs AMD in de toekomst zijn achterstand inhaalt of op zijn minst een aantal opmerkelijke verbeteringen aanbrengt in de komende line-up van hun GPU’s, aangezien ze al geweldig werk leveren met betrekking tot hun CPU’s, nl.De reikwijdte van GPU’s in de komende jaren is enorm als we nieuwe innovaties en doorbraken maken in deep learning, machine learning, en HPC. GPU-versnelling zal altijd van pas komen voor veel ontwikkelaars en studenten om zich op dit gebied te begeven, omdat hun prijzen ook betaalbaarder worden. Ook dank aan de brede gemeenschap die ook bijdraagt aan de ontwikkeling van AI en HPC.
Over de auteur

Prathmesh Patil
ML-liefhebber, Data Science, Python-ontwikkelaar.
LinkedIn: https://www.linkedin.com/in/prathmesh