Od ostatniej dekady widzimy, że procesory graficzne coraz częściej pojawiają się w takich dziedzinach jak HPC (High-Performance Computing) i najpopularniejsza dziedzina, czyli gry. Układy GPU poprawiały się z roku na rok i obecnie są w stanie wykonywać niewiarygodnie wspaniałe rzeczy, ale w ciągu ostatnich kilku lat przykuwają jeszcze większą uwagę ze względu na głębokie uczenie.

Jako że modele głębokiego uczenia spędzają dużą ilość czasu na szkoleniu, nawet potężne procesory centralne nie były wystarczająco wydajne, aby obsłużyć tak wiele obliczeń w danym czasie i jest to obszar, w którym układy GPU po prostu przewyższały procesory centralne dzięki swojej równoległości. Zanim jednak zagłębimy się w ten temat, pozwólmy sobie najpierw zrozumieć kilka rzeczy na temat GPU.
Co to jest GPU?
A GPU lub 'Graphics Processing Unit’ jest miniaturową wersją całego komputera, ale przeznaczoną tylko do wykonywania konkretnych zadań. W przeciwieństwie do jednostki centralnej (CPU), która wykonuje wiele zadań w tym samym czasie. GPU posiada swój własny procesor, który jest osadzony na własnej płycie głównej w połączeniu z v-ram lub video ramem, a także odpowiednią konstrukcję termiczną do wentylacji i chłodzenia.
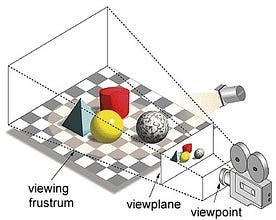
W pojęciu 'Graphics Processing Unit’, 'Graphics’ odnosi się do renderowania obrazu na określonych współrzędnych w przestrzeni 2D lub 3D. Rzutnia lub punkt widzenia to perspektywa patrzenia na obiekt przez widza, w zależności od rodzaju zastosowanej projekcji. Rasteryzacja i Ray-tracing są niektórymi ze sposobów renderowania scen 3d, obie te koncepcje oparte są na typie projekcji zwanej projekcją perspektywiczną. Co to jest rzut perspektywiczny?
W skrócie, jest to sposób, w jaki jak obraz jest tworzony na płaszczyźnie widoku lub płótnie, gdzie linie równoległe zbiegają się do punktu zbieżnego zwanego „centrum projekcji” również jako obiekt oddala się od punktu widzenia wydaje się być mniejszy, dokładnie tak, jak nasze oczy portretują w świecie rzeczywistym i to pomaga w zrozumieniu głębi w obrazie, jak również, to jest powód, dlaczego produkuje realistyczne obrazy.
Co więcej, procesory graficzne przetwarzają także złożoną geometrię, wektory, źródła światła lub iluminacje, tekstury, kształty, itp. Ponieważ teraz mamy podstawowe pojęcie o GPU, zrozummy, dlaczego jest on intensywnie wykorzystywany w głębokim uczeniu.
Dlaczego procesory graficzne są lepsze w głębokim uczeniu?
Jedną z najbardziej podziwianych cech GPU jest zdolność do równoległego obliczania procesów. Jest to punkt, w którym pojawia się pojęcie obliczeń równoległych. Procesor centralny generalnie wykonuje swoje zadania w sposób sekwencyjny. Procesor centralny może być podzielony na rdzenie, a każdy z nich wykonuje jedno zadanie w tym samym czasie. Załóżmy, że procesor ma 2 rdzenie. Następnie dwa różne procesy zadania mogą działać na tych dwóch rdzeniach, osiągając w ten sposób wielozadaniowość.
Ale nadal, procesy te wykonują się w sposób szeregowy.

Nie oznacza to, że procesory nie są wystarczająco dobre. W rzeczywistości, procesory są naprawdę dobre w obsłudze różnych zadań związanych z różnymi operacjami, takimi jak obsługa systemów operacyjnych, obsługa arkuszy kalkulacyjnych, odtwarzanie filmów HD, rozpakowywanie dużych plików zip, a wszystko to w tym samym czasie. Są to pewne rzeczy, których GPU po prostu nie potrafi zrobić.
Gdzie leży różnica?
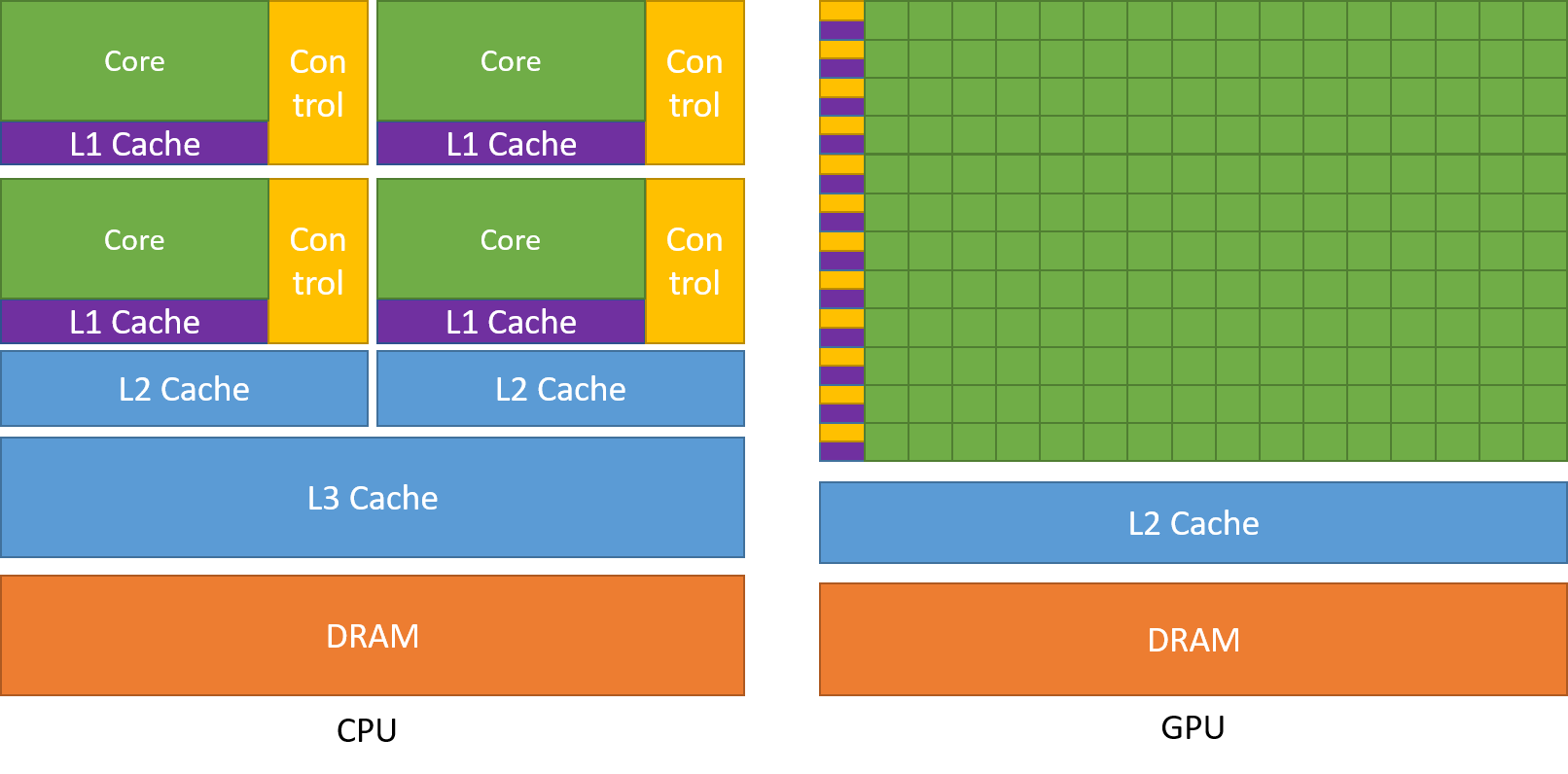
Jak omówiono wcześniej, procesor centralny jest podzielony na wiele rdzeni, dzięki czemu może wykonywać wiele zadań w tym samym czasie, podczas gdy procesor graficzny będzie posiadał setki i tysiące rdzeni, z których wszystkie są dedykowane pojedynczemu zadaniu. Są to proste obliczenia, które są wykonywane częściej i są od siebie niezależne. Obydwa układy przechowują często wymagane dane w pamięci podręcznej, stosując się tym samym do zasady „odniesienia do lokalizacji”.
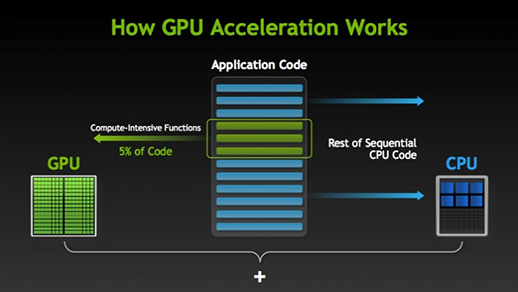
Istnieje wiele programów i gier, które mogą wykorzystać układy GPU do ich wykonania. Chodzi o to, aby niektóre części zadania lub kodu aplikacji były wykonywane równolegle, ale nie całe procesy. Dzieje się tak, ponieważ większość procesów w zadaniu musi być wykonywana wyłącznie w sposób sekwencyjny. Na przykład, logowanie do systemu lub aplikacji nie musi być wykonywane równolegle.
Gdy istnieje część wykonania, która może być wykonana równolegle, jest ona po prostu przenoszona do GPU w celu przetworzenia, gdzie w tym samym czasie sekwencyjne zadanie jest wykonywane przez CPU, a następnie obie części zadania są ponownie łączone razem.
Na rynku procesorów graficznych istnieją dwaj główni gracze, tj. AMD i Nvidia. Procesory graficzne Nvidia są szeroko wykorzystywane do głębokiego uczenia się, ponieważ mają szerokie wsparcie w oprogramowaniu forum, sterownikach, CUDA i cuDNN. Tak więc w zakresie AI i głębokiego uczenia się, Nvidia jest pionierem przez długi czas.
Sieci neuronowe są uważane za żenująco równoległe, co oznacza, że obliczenia w sieciach neuronowych mogą być wykonywane równolegle łatwo i są niezależne od siebie.
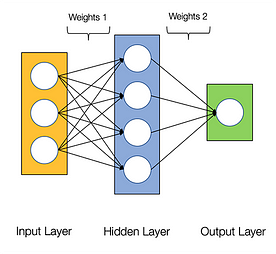
Niektóre obliczenia, takie jak obliczanie wag i funkcji aktywacji każdej warstwy, backpropagation mogą być wykonywane równolegle. Istnieje również wiele prac badawczych na ten temat.
Procesory graficzne firmy Nvidia wyposażone są w wyspecjalizowane rdzenie znane jako rdzenie CUDA, które pomagają w akceleracji głębokiego uczenia.
Co to jest CUDA?
CUDA to skrót od 'Compute Unified Device Architecture’, który został wprowadzony na rynek w 2007 roku. Jest to sposób, w jaki można osiągnąć obliczenia równoległe i wykorzystać moc GPU w zoptymalizowany sposób, co skutkuje znacznie lepszą wydajnością podczas wykonywania zadań.

Zestaw narzędziowy CUDA to kompletny pakiet składający się ze środowiska programistycznego, które służy do tworzenia aplikacji wykorzystujących procesory graficzne. Zestaw narzędziowy zawiera głównie kompilator c/c++, debugger i biblioteki. Ponadto, środowisko uruchomieniowe CUDA posiada swoje sterowniki, dzięki którym może komunikować się z procesorem graficznym. CUDA to także język programowania, który został stworzony specjalnie po to, by instruować GPU w zakresie wykonywania zadań. Jest również znany jako programowanie GPU.
Poniżej znajduje się prosty program hello world tylko po to, aby zorientować się, jak wygląda kod CUDA.
/* hello world program in cuda *\#include<stdio.h>#include<stdlib.h>#include<cuda.h>__global__ void demo() { printf("hello world!,my first cuda program");}int main() { printf("From main!\n"); demo<<<1,1>>>(); return 0;}

Co to jest cuDNN?

cuDNN jest biblioteką sieci neuronowych, która jest zoptymalizowana pod kątem GPU i może w pełni wykorzystać możliwości GPU Nvidia. Biblioteka ta składa się z implementacji konwolucji, propagacji w przód i w tył, funkcji aktywacji i łączenia. Jest to biblioteka obowiązkowa, bez której nie można używać GPU do szkolenia sieci neuronowych.
Wielki skok z rdzeniami Tensor!
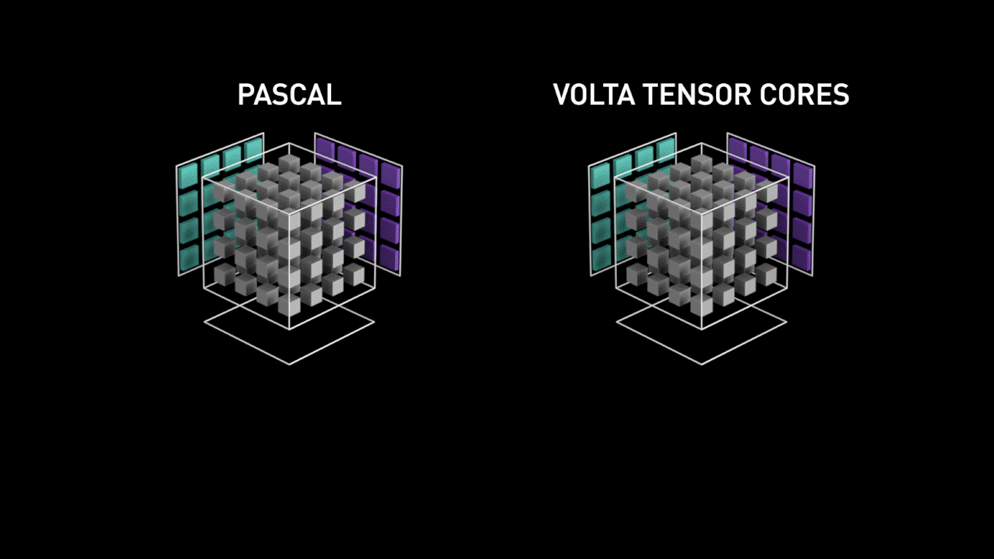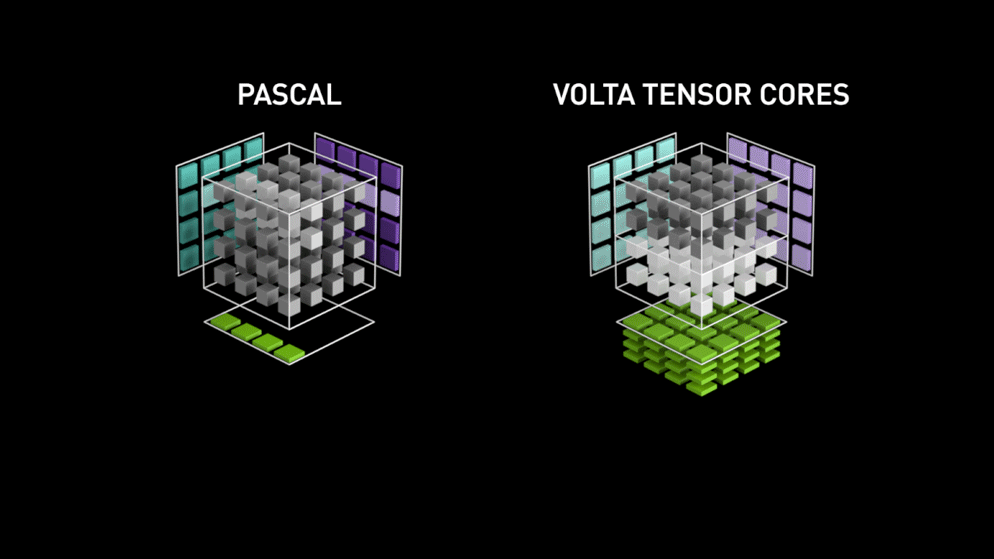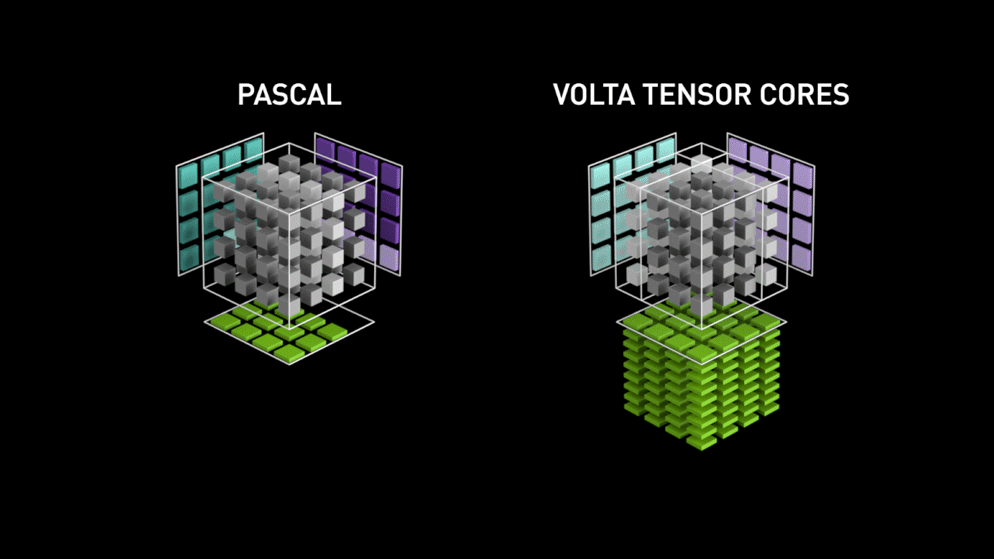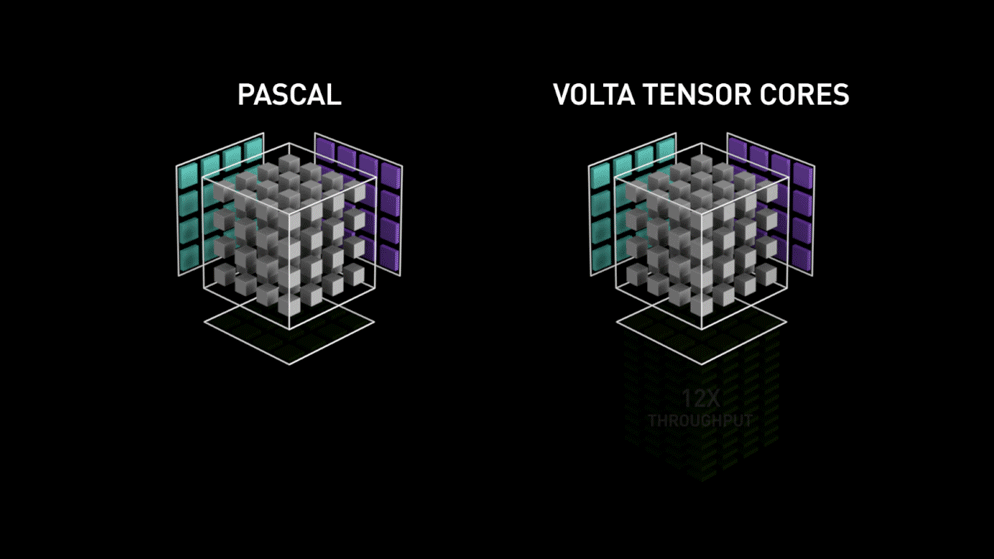
W roku 2018 firma Nvidia wprowadziła nową linię swoich procesorów graficznych tj. serię 2000. Nazywane również RTX, karty te pochodzą z rdzeniami tensorowymi, które są dedykowane do głębokiego uczenia się i oparte na architekturze Volta.

Rdzenie tensorowe są szczególnymi rdzeniami, które wykonują mnożenie macierzy 4 x 4 macierzy FP16 i dodawanie z 4 x 4 macierzy FP16 lub FP32 w pół-precyzji, wyjściem będzie wynik w postaci macierzy 4 x 4 FP16 lub FP32 z pełną precyzją.
Uwaga: 'FP’ oznacza zmiennoprzecinkową, aby zrozumieć więcej o zmiennoprzecinkowej i precyzji sprawdź ten blog.
Jak stwierdziła Nvidia, nowa generacja rdzeni tensorowych opartych na architekturze volta jest znacznie szybsza niż rdzenie CUDA oparte na architekturze Pascal. Dało to ogromny impuls dla głębokiego uczenia się.
W czasie pisania tego bloga, Nvidia ogłosiła najnowszą serię 3000 ich linii GPU, które pochodzą z architekturą Ampere. W tym, poprawili wydajność rdzeni tensorowych o 2x. Również przynosząc nowe wartości precyzji jak TF32 (tensor float 32), FP64 (floating point 64). TF32 działa tak samo jak FP32, ale z przyspieszeniem do 20x, w wyniku tego wszystkiego Nvidia twierdzi, że czas wnioskowania lub szkolenia modeli zostanie zredukowany z tygodni do godzin.
AMD vs Nvidia

AMD GPUs are decent for gaming but as soon as deep learning comes into the picture, then simply Nvidia is way ahead. Nie oznacza to, że procesory graficzne AMD są złe. Jest to spowodowane optymalizacją oprogramowania i sterowników, które nie są aktualizowane aktywnie, po stronie Nvidia mają lepsze sterowniki z częstymi aktualizacjami i na górze, że CUDA, cuDNN pomaga przyspieszyć obliczenia.
Niektóre znane biblioteki, takie jak Tensorflow, PyTorch wsparcie dla CUDA. Oznacza to, że można wykorzystać procesory graficzne klasy podstawowej z serii GTX 1000. Po stronie AMD, ma bardzo małe wsparcie programowe dla ich GPU. Po stronie sprzętowej, Nvidia wprowadziła dedykowane rdzenie tensorowe. AMD ma ROCm do akceleracji, ale nie jest on dobry jako rdzenie tensorowe, a wiele bibliotek głębokiego uczenia nie obsługuje ROCm. Przez ostatnie kilka lat nie zauważono dużego skoku pod względem wydajności.
Dzięki wszystkim tym punktom, Nvidia po prostu przoduje w głębokim uczeniu.
Podsumowanie
Aby podsumować wszystko, czego się dowiedzieliśmy, jasne jest, że jak na razie Nvidia jest liderem na rynku pod względem GPU, ale naprawdę mam nadzieję, że nawet AMD dogoni w przyszłości lub przynajmniej dokona kilku znaczących ulepszeń w nadchodzącej linii swoich GPU, ponieważ już wykonują świetną robotę w odniesieniu do swoich procesorów i.Seria Ryzen.
Zakres GPU w nadchodzących latach jest ogromny, ponieważ wprowadzamy nowe innowacje i przełomy w głębokim uczeniu, uczeniu maszynowym i HPC. Akceleracja GPU zawsze będzie przydatna dla wielu programistów i studentów, którzy chcą wejść w tę dziedzinę, ponieważ ich ceny stają się coraz bardziej przystępne. Podziękowania należą się również szerokiej społeczności, która również przyczynia się do rozwoju AI i HPC.
O autorze

Prathmesh Patil
entuzjastaML, Data Science, programista Python.
LinkedIn: https://www.linkedin.com/in/prathmesh