Sedan det senaste decenniet har vi sett GPU:er komma in i bilden allt oftare inom områden som HPC (High-Performance Computing) och det mest populära området, dvs. spel. GPU:er har förbättrats år efter år och nu kan de göra otroligt bra saker, men under de senaste åren har de fått ännu mer uppmärksamhet på grund av djupinlärning.
 Eftersom modeller för djupinlärning spenderar mycket tid på träning var inte ens kraftfulla CPU:er tillräckligt effektiva för att hantera så många beräkningar samtidigt, och det är på detta område som GPU:erna helt enkelt överträffade CPU:erna på grund av sin parallellism. Men innan vi går in på djupet kan vi först förstå några saker om GPU.
Eftersom modeller för djupinlärning spenderar mycket tid på träning var inte ens kraftfulla CPU:er tillräckligt effektiva för att hantera så många beräkningar samtidigt, och det är på detta område som GPU:erna helt enkelt överträffade CPU:erna på grund av sin parallellism. Men innan vi går in på djupet kan vi först förstå några saker om GPU.
Vad är GPU?
En GPU eller ”Graphics Processing Unit” är en miniversion av en hel dator, men endast avsedd för en specifik uppgift. Den är till skillnad från en CPU som utför flera uppgifter samtidigt. GPU:n har en egen processor som är inbyggd på ett eget moderkort tillsammans med v-ram eller videoram och även en ordentlig termisk konstruktion för ventilation och kylning.
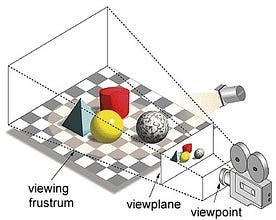
I begreppet ”Graphics Processing Unit”, ”Graphics” hänvisar till att återge en bild vid specificerade koordinater i ett 2d- eller 3d-rum. En viewport eller viewpoint är en betraktares perspektiv på ett objekt beroende på vilken typ av projektion som används. Rasterisering och strålspårning är några av sätten att återge 3D-scener, och båda dessa begrepp bygger på en typ av projektion som kallas perspektivprojektion. Vad är perspektivprojektion?
Kort sagt, det är det sätt på vilket en bild bild bildas på ett bildplan eller en duk där de parallella linjerna konvergerar till en konvergerande punkt som kallas ”projektionscentrum”, och när objektet rör sig bort från synvinkeln verkar det bli mindre, precis som våra ögon avbildar i verkligheten, och detta hjälper oss att förstå djupet i en bild, vilket är anledningen till att det ger realistiska bilder.
För övrigt bearbetar GPU:er även komplex geometri, vektorer, ljuskällor eller belysningar, texturer, former osv. Eftersom vi nu har en grundläggande uppfattning om GPU:er, låt oss förstå varför de används flitigt för djupinlärning.
Varför är GPU:er bättre för djupinlärning?
En av de mest beundrade egenskaperna hos en GPU är förmågan att beräkna processer parallellt. Det är här som begreppet parallell beräkning kommer in i bilden. En CPU slutför i allmänhet sin uppgift på ett sekventiellt sätt. En CPU kan delas in i kärnor och varje kärna tar sig an en uppgift i taget. Antag att en CPU har två kärnor. Då kan två olika uppgiftsprocesser köras på dessa två kärnor och därmed uppnås multitasking.
Men fortfarande utförs dessa processer på ett seriellt sätt.

Detta betyder inte att CPU:er inte är tillräckligt bra. Faktum är att processorer är riktigt bra på att hantera olika uppgifter i samband med olika operationer som att hantera operativsystem, hantera kalkylblad, spela upp HD-videor, extrahera stora zip-filer, allt på samma gång. Detta är några saker som en GPU helt enkelt inte kan göra.
Var ligger skillnaden?
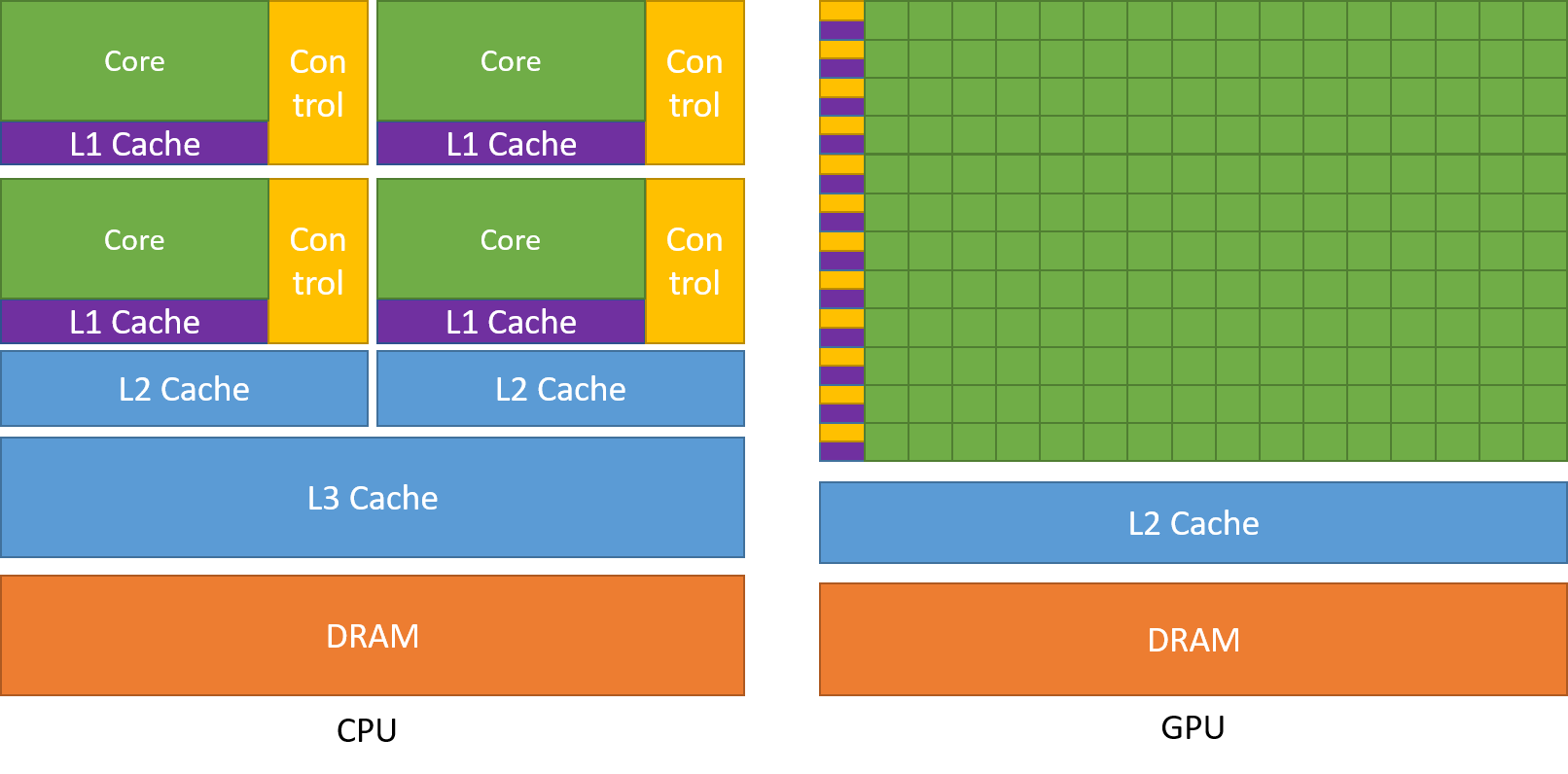
Som vi diskuterat tidigare är en CPU uppdelad i flera kärnor så att de kan ta sig an flera uppgifter samtidigt, medan GPU:n kommer att ha hundratals och tusentals kärnor som alla är dedikerade till en enda uppgift. Detta är enkla beräkningar som utförs oftare och är oberoende av varandra. Och båda lagrar ofta nödvändiga data i sina respektive cacheminnen och följer därmed principen om ”lokalitetsreferens”.
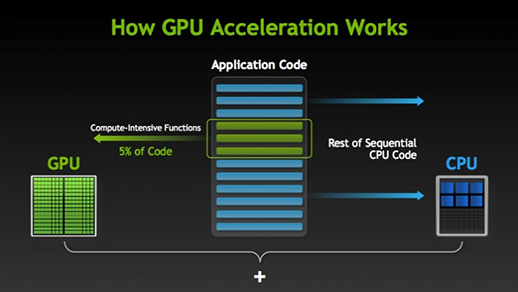
Det finns många programvaror och spel som kan dra nytta av GPU:er för utförande. Tanken bakom detta är att göra vissa delar av uppgiften eller programkoden parallell men inte hela processerna. Detta beror på att de flesta av uppgiftens processer endast måste exekveras sekventiellt. Till exempel behöver inloggning i ett system eller program inte göras parallellt.
När det finns en del av utförandet som kan göras parallellt flyttas den helt enkelt till GPU:n för bearbetning, där den sekventiella uppgiften samtidigt utförs i CPU:n, varefter båda delarna av uppgiften återigen kombineras tillsammans. På GPU-marknaden finns det två huvudaktörer, dvs. AMD och Nvidia. Nvidias GPU:er används i stor utsträckning för djupinlärning eftersom de har ett omfattande stöd i forumprogramvaran, drivrutiner, CUDA och cuDNN. Så när det gäller AI och djupinlärning är Nvidia pionjär sedan länge.
Neurala nätverk sägs vara pinsamt parallella, vilket innebär att beräkningar i neurala nätverk lätt kan utföras parallellt och att de är oberoende av varandra.
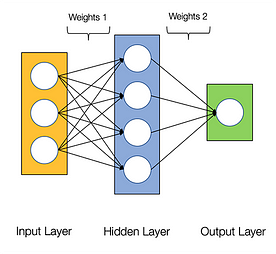
Vissa beräkningar som beräkning av vikter och aktiveringsfunktioner för varje lager, backpropagation kan utföras parallellt. Det finns många forskningsrapporter tillgängliga om det också.
Nvidias GPU:er har specialiserade kärnor som kallas CUDA-kärnor som hjälper till att påskynda djupinlärning.
Vad är CUDA?
CUDA står för ”Compute Unified Device Architecture” som lanserades 2007, det är ett sätt att uppnå parallellberäkning och få ut det mesta av GPU-kraften på ett optimerat sätt, vilket resulterar i mycket bättre prestanda vid utförandet av uppgifter.

Cuda-verktygslådan är ett komplett paket som består av en utvecklingsmiljö som används för att bygga tillämpningar som utnyttjar GPU:er. Verktygslådan innehåller huvudsakligen c/c++-kompilator, felsökare och bibliotek. Dessutom har CUDA runtime sina drivrutiner så att den kan kommunicera med GPU:n. CUDA är också ett programmeringsspråk som är särskilt gjort för att instruera GPU:n att utföra en uppgift. Det är också känt som GPU-programmering.
Nedan följer ett enkelt hello world-program bara för att få en uppfattning om hur CUDA-kod ser ut.
/* hello world program in cuda *\#include<stdio.h>#include<stdlib.h>#include<cuda.h>__global__ void demo() { printf("hello world!,my first cuda program");}int main() { printf("From main!\n"); demo<<<1,1>>>(); return 0;}

Vad är cuDNN?

cuDNN är ett neuralt nätverksbibliotek som är GPU-optimerat och kan dra full nytta av Nvidias GPU. Biblioteket består av implementering av konvolution, framåt- och bakåtpropagation, aktiveringsfunktioner och pooling. Det är ett bibliotek utan vilket du inte kan använda GPU för att träna neurala nätverk.
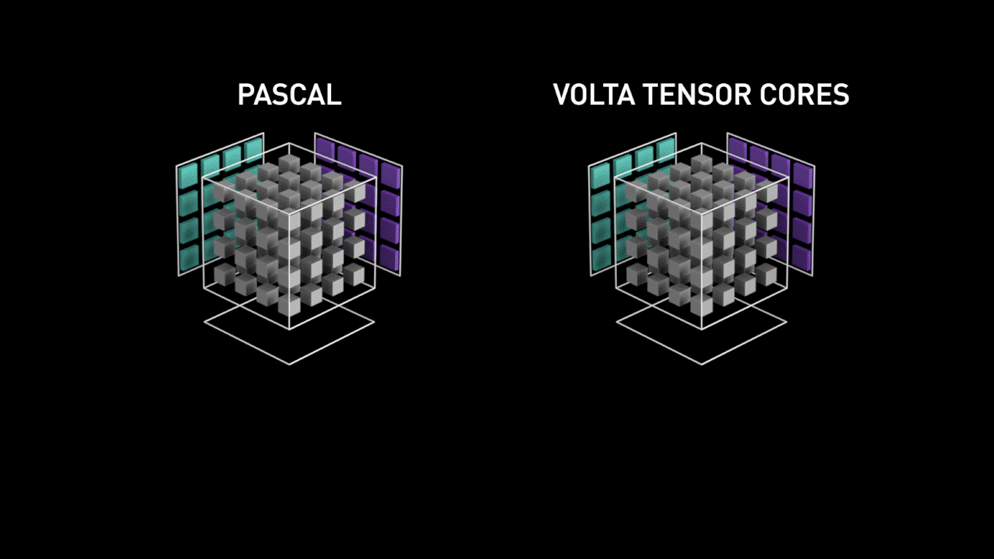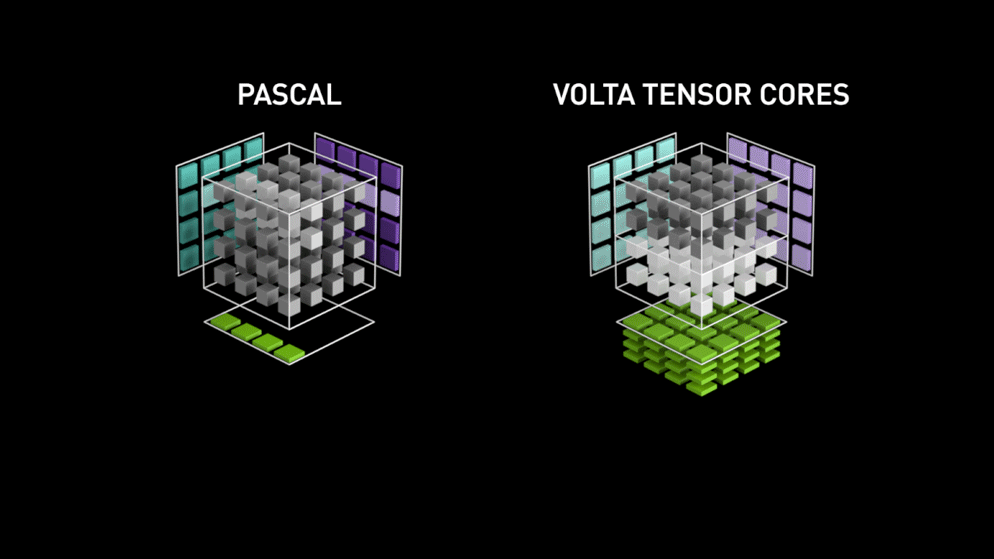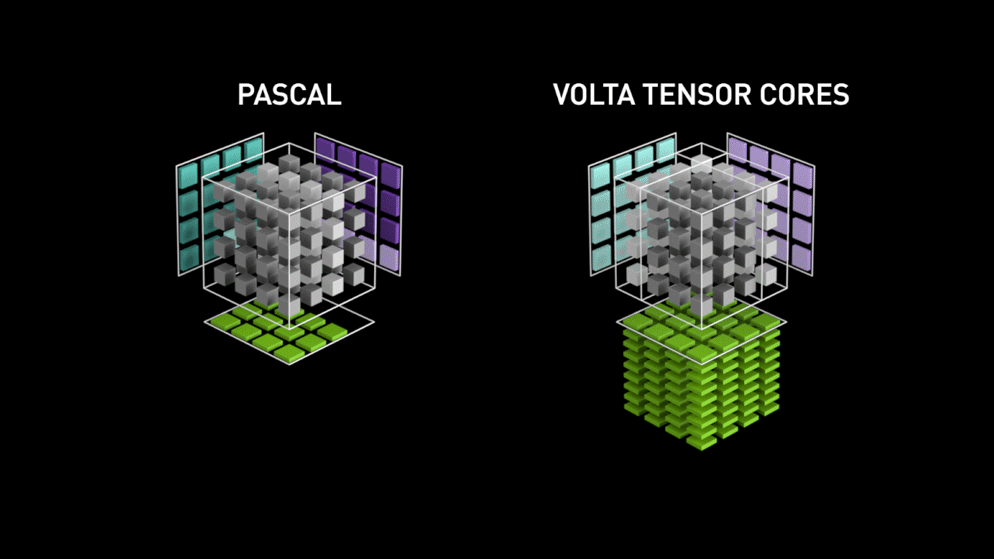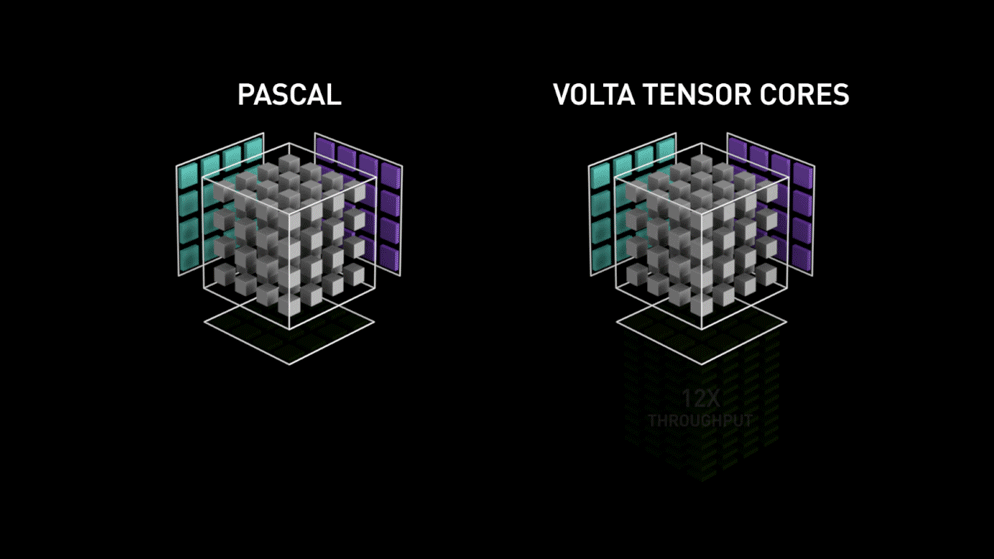
Ett stort steg med sensorkärnor!
Redan år 2018 lanserade Nvidia en ny serie av sina GPU:er, dvs. 2000-serien. Dessa kort, som även kallas RTX, kommer med sensorkärnor som är dedikerade till djupinlärning och baserade på Volta-arkitekturen.

Tensorkärnor är särskilda kärnor som utför matrismultiplikation av 4 x 4 FP16-matriser och addition med 4 x 4 matriser FP16 eller FP32 med halvprecision, utgången kommer att resultera i en 4 x 4 FP16- eller FP32-matris med full precision.
Note: ”FP” står för floating-point för att förstå mer om floating-point och precision, se den här bloggen.
Som Nvidia uppger är den nya generationens tensorkärnor baserade på volta-arkitekturen mycket snabbare än CUDA-kärnor baserade på Pascal-arkitekturen. Detta gav ett enormt uppsving för djupinlärning.
I samband med att den här bloggen skrevs meddelade Nvidia att de senaste 3000-serierna i sitt GPU-utbud kommer med Ampere-arkitektur. I denna har de förbättrat prestandan hos sensorkärnorna med 2x. De har också tagit med sig nya precisionsvärden som TF32(tensor float 32), FP64(floating point 64). TF32 fungerar på samma sätt som FP32 men med en hastighetsökning på upp till 20x. Som ett resultat av allt detta hävdar Nvidia att inferens- eller träningstiden för modeller kommer att minskas från veckor till timmar.
AMD vs Nvidia

AMD:s GPU:er är anständiga för spel, men så snart som djupinlärning kommer in i bilden, då ligger helt enkelt Nvidia långt före. Det betyder inte att AMD:s GPU:er är dåliga. Det beror på mjukvaruoptimering och drivrutiner som inte uppdateras aktivt, på Nvidias sida har de bättre drivrutiner med frekventa uppdateringar och dessutom hjälper CUDA, cuDNNN till att påskynda beräkningarna.
Vissa välkända bibliotek som Tensorflow, PyTorch har stöd för CUDA. Det innebär att GPU:er på instegsnivå i GTX 1000-serien kan användas. På AMD:s sida finns det mycket lite mjukvarustöd för deras GPU:er. På hårdvarusidan har Nvidia infört dedikerade sensorkärnor. AMD har ROCm för acceleration, men det är inte lika bra som tensor-kärnor, och många bibliotek för djupinlärning har inte stöd för ROCm. Under de senaste åren har man inte märkt något stort språng när det gäller prestanda.
På grund av alla dessa punkter utmärker sig Nvidia helt enkelt inom djupinlärning.
Sammanfattning
För att dra en slutsats av allt vi har lärt oss är det tydligt att Nvidia i dagsläget är marknadsledande när det gäller GPU:er, men jag hoppas verkligen att även AMD kommer ikapp i framtiden eller åtminstone gör några anmärkningsvärda förbättringar i den kommande serien av deras GPU:er eftersom de redan gör ett bra jobb när det gäller deras CPU:er i.
Den omfattning som GPU:erna har under de kommande åren är enorm eftersom vi gör nya innovationer och genombrott inom djupinlärning, maskininlärning och HPC. GPU-acceleration kommer alltid att vara till nytta för många utvecklare och studenter för att komma in på detta område eftersom deras priser också blir mer överkomliga. Tack också till det breda samhället som också bidrar till utvecklingen av AI och HPC.
Om författaren

Prathmesh Patil
ML-entusiast, datavetenskap, Python-utvecklare.
LinkedIn: https://www.linkedin.com/in/prathmesh