Dallo scorso decennio, abbiamo visto le GPU entrare in scena più frequentemente in campi come l’HPC (High-Performance Computing) e il campo più popolare, cioè il gioco. Le GPU sono migliorate anno dopo anno e ora sono in grado di fare alcune cose incredibilmente grandi, ma negli ultimi anni, stanno catturando ancora più attenzione a causa del deep learning.

Come i modelli di deep learning spendono una grande quantità di tempo in formazione, anche le potenti CPU non erano abbastanza efficienti per gestire così tanti calcoli in un dato momento e questa è l’area in cui le GPU hanno semplicemente superato le CPU grazie al loro parallelismo. Ma prima di tuffarci in profondità, cerchiamo di capire alcune cose sulla GPU.
Che cos’è la GPU?
Una GPU o ‘Graphics Processing Unit’ è una versione mini di un intero computer ma dedicata solo a un compito specifico. È diverso da una CPU che svolge più compiti allo stesso tempo. La GPU è dotata di un proprio processore che è incorporato sulla propria scheda madre accoppiato con v-ram o video ram, e anche un design termico adeguato per la ventilazione e il raffreddamento.
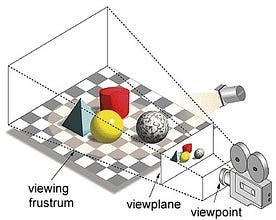
Nel termine ‘Graphics Processing Unit’, ‘Graphics’ si riferisce al rendering di un’immagine su coordinate specifiche in uno spazio 2d o 3d. Una viewport o viewpoint è la prospettiva dello spettatore che guarda un oggetto, a seconda del tipo di proiezione usata. Rasterizzazione e Ray-tracing sono alcuni dei modi di rendere le scene 3d, entrambi questi concetti sono basati su un tipo di proiezione chiamata proiezione prospettica. Cos’è la proiezione prospettica?
In breve, è il modo in cui un’immagine è formata su un piano di vista o tela dove le linee parallele convergono verso un punto convergente chiamato “centro di proiezione”, inoltre come l’oggetto si allontana dal punto di vista sembra essere più piccolo, esattamente come i nostri occhi ritraggono nel mondo reale e questo aiuta nella comprensione della profondità in un’immagine, questa è la ragione per cui produce immagini realistiche.
Inoltre le GPU elaborano anche geometrie complesse, vettori, fonti di luce o illuminazioni, texture, forme, ecc. Poiché ora abbiamo un’idea di base sulla GPU, cerchiamo di capire perché è pesantemente utilizzata per l’apprendimento profondo.
Perché le GPU sono migliori per l’apprendimento profondo?
Una delle caratteristiche più ammirate di una GPU è la capacità di calcolare processi in parallelo. Questo è il punto in cui entra in gioco il concetto di calcolo parallelo. Una CPU in generale completa il suo compito in modo sequenziale. Una CPU può essere divisa in core e ogni core svolge un compito alla volta. Supponiamo che una CPU abbia 2 core. Allora due processi di compiti diversi possono essere eseguiti su questi due core ottenendo così il multitasking.
Ma ancora, questi processi vengono eseguiti in modo seriale.

Questo non significa che le CPU non siano abbastanza buone. Infatti, le CPU sono davvero brave a gestire diversi compiti relativi a diverse operazioni come gestire sistemi operativi, gestire fogli di calcolo, riprodurre video HD, estrarre grandi file zip, tutto allo stesso tempo. Queste sono alcune cose che una GPU semplicemente non può fare.
Dove sta la differenza?
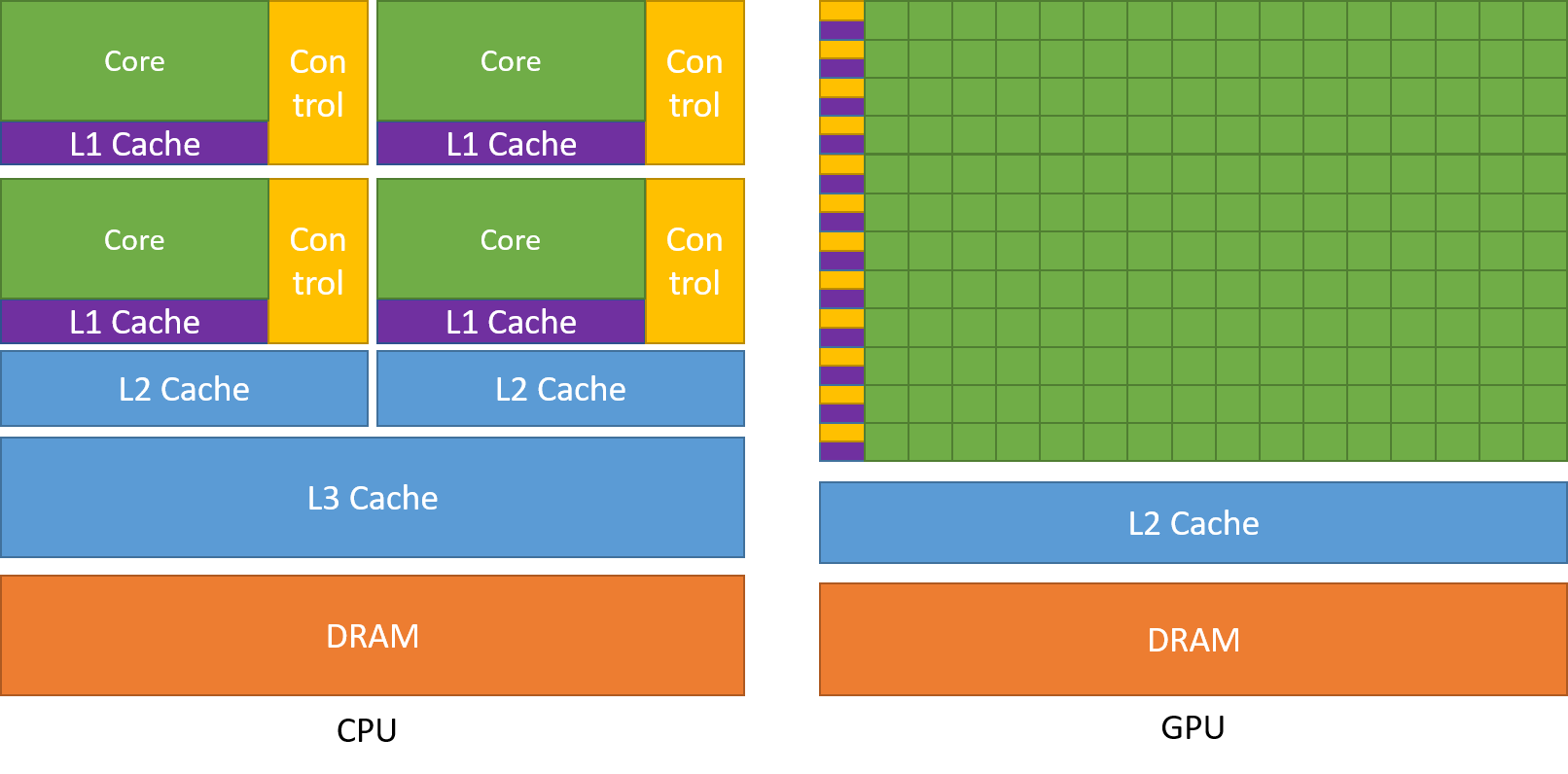
Come discusso in precedenza una CPU è divisa in più core in modo che possano occuparsi di più compiti contemporaneamente, mentre la GPU avrà centinaia e migliaia di core, tutti dedicati a un singolo compito. Si tratta di calcoli semplici che vengono eseguiti più frequentemente e sono indipendenti l’uno dall’altro. Ed entrambi memorizzano i dati frequentemente richiesti nella rispettiva memoria cache, seguendo così il principio del ‘riferimento alla località’.
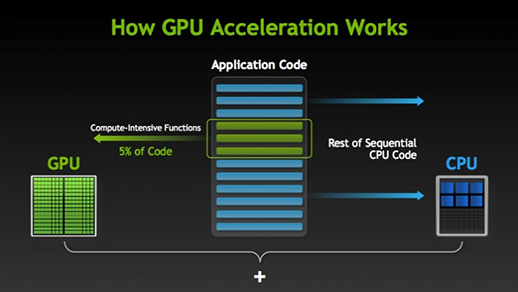
Ci sono molti software e giochi che possono trarre vantaggio dalle GPU per l’esecuzione. L’idea alla base di questo è di rendere alcune parti del compito o del codice dell’applicazione in parallelo, ma non gli interi processi. Questo perché la maggior parte dei processi del compito devono essere eseguiti solo in modo sequenziale. Per esempio, l’accesso a un sistema o un’applicazione non ha bisogno di fare in parallelo.
Quando c’è una parte di esecuzione che può essere fatta in parallelo viene semplicemente spostata alla GPU per l’elaborazione dove allo stesso tempo il compito sequenziale viene eseguito nella CPU, poi entrambe le parti del compito vengono nuovamente combinate insieme.
Nel mercato delle GPU, ci sono due attori principali cioè AMD e Nvidia. Le GPU Nvidia sono ampiamente utilizzate per l’apprendimento profondo perché hanno un ampio supporto nel software del forum, i driver, CUDA e cuDNN. Quindi, in termini di IA e apprendimento profondo, Nvidia è il pioniere per molto tempo.
Si dice che le reti neurali sono imbarazzantemente parallele, il che significa che i calcoli nelle reti neurali possono essere eseguiti in parallelo facilmente e sono indipendenti gli uni dagli altri.
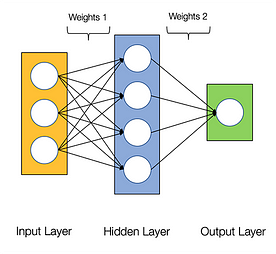
Alcuni calcoli come il calcolo dei pesi e delle funzioni di attivazione di ogni strato, backpropagation possono essere eseguiti in parallelo. Ci sono molte ricerche disponibili anche su di esso.
Le GPU NVIDIA sono dotate di core specializzati conosciuti come core CUDA che aiutano ad accelerare l’apprendimento profondo.
Che cos’è CUDA?
CUDA sta per ‘Compute Unified Device Architecture’ che è stato lanciato nel 2007, è un modo in cui è possibile ottenere il calcolo parallelo e ottenere il massimo dalla potenza della GPU in un modo ottimizzato, che si traduce in prestazioni molto migliori durante l’esecuzione dei compiti.

Il CUDA toolkit è un pacchetto completo che consiste in un ambiente di sviluppo utilizzato per costruire applicazioni che fanno uso delle GPU. Questo toolkit contiene principalmente compilatore c/c++, debugger e librerie. Inoltre, il runtime CUDA ha i suoi driver in modo da poter comunicare con la GPU. CUDA è anche un linguaggio di programmazione che è specificamente fatto per istruire la GPU ad eseguire un compito. È anche conosciuto come programmazione GPU.
Di seguito è riportato un semplice programma hello world solo per avere un’idea di come appare il codice CUDA.
/* hello world program in cuda *\#include<stdio.h>#include<stdlib.h>#include<cuda.h>__global__ void demo() { printf("hello world!,my first cuda program");}int main() { printf("From main!\n"); demo<<<1,1>>>(); return 0;}

Cos’è cuDNN?

cuDNN è una libreria di reti neurali che è ottimizzata per la GPU e può trarre pieno vantaggio dalla GPU Nvidia. Questa libreria consiste nell’implementazione di convoluzione, propagazione avanti e indietro, funzioni di attivazione e pooling. È una libreria indispensabile senza la quale non è possibile utilizzare la GPU per l’addestramento delle reti neurali.
Un grande salto con i core Tensor!
Nel 2018, Nvidia ha lanciato una nuova linea delle sue GPU, ovvero la serie 2000. Chiamate anche RTX, queste schede sono dotate di tensor cores dedicati al deep learning e basati sull’architettura Volta.

I tensor core sono particolari core che eseguono la moltiplicazione di matrici 4 x 4 FP16 e l’addizione con matrici 4 x 4 FP16 o FP32 in mezza precisione, l’output sarà risultante in una matrice 4 x 4 FP16 o FP32 con piena precisione.
Nota: ‘FP’ sta per floating-point per capire di più su floating-point e precisione controlla questo blog.
Come dichiarato da Nvidia, la nuova generazione di tensor core basati su architettura Volta è molto più veloce dei core CUDA basati su architettura Pascal. Questo ha dato una spinta enorme al deep learning.
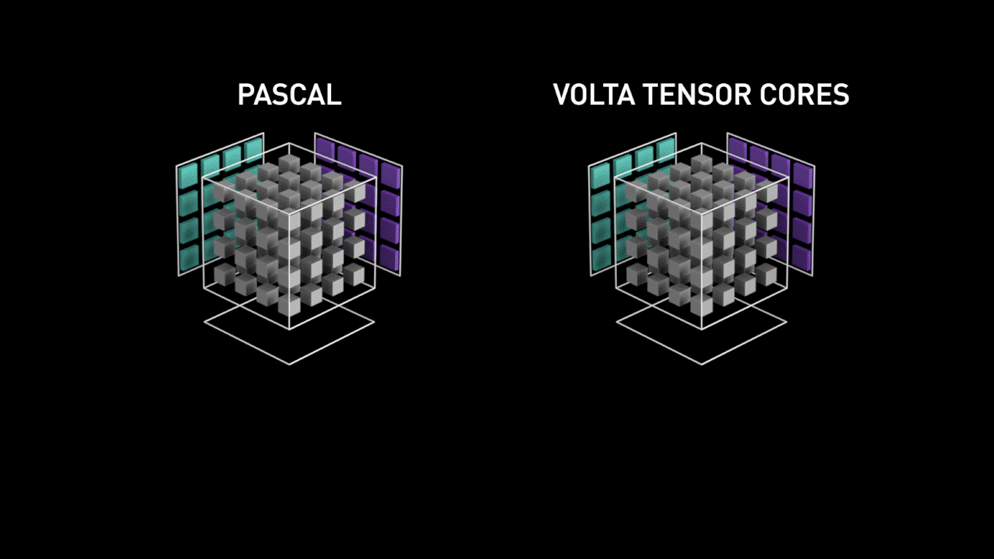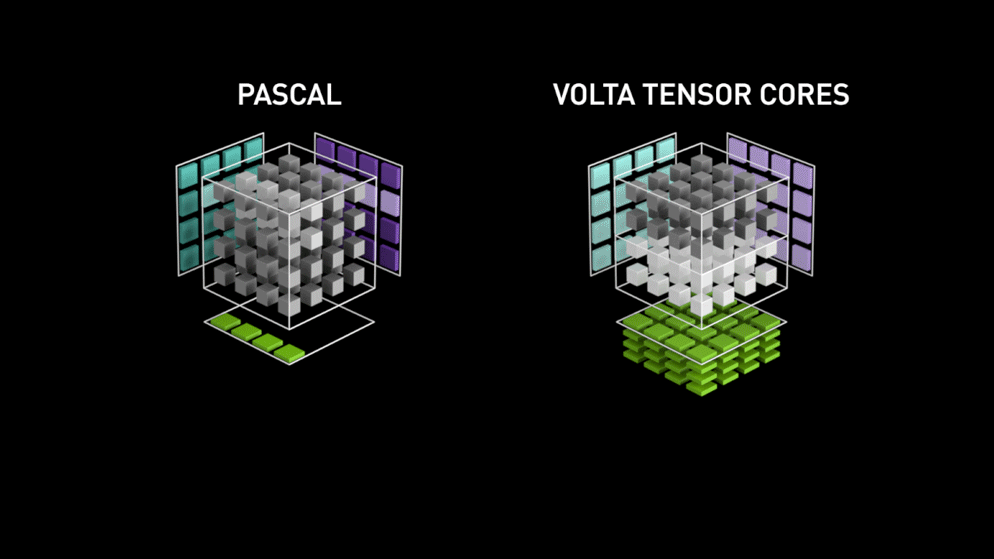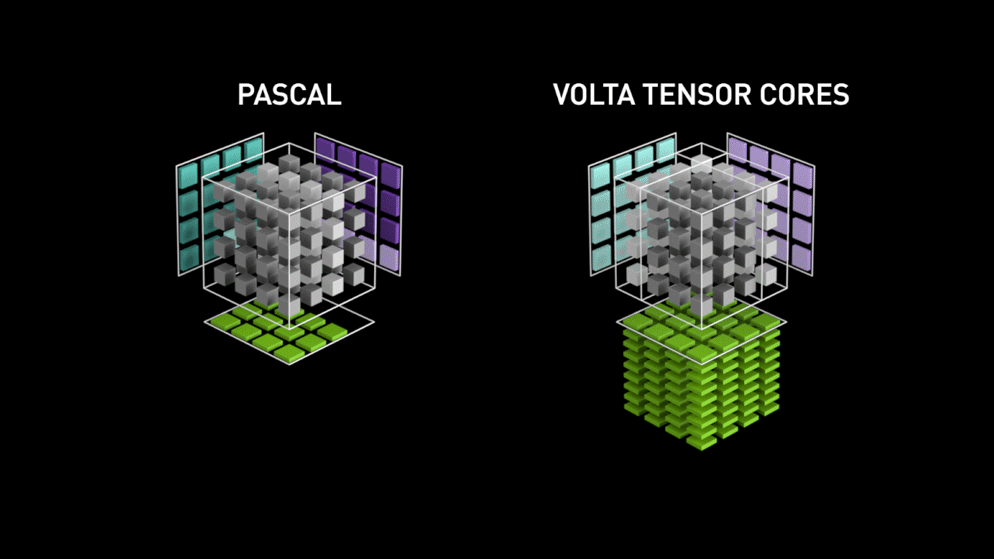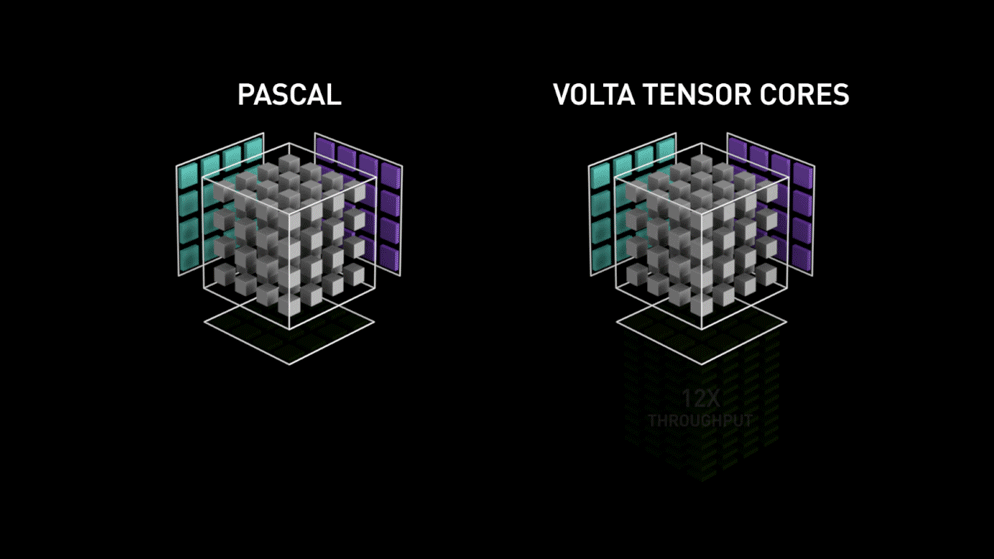
Al momento di scrivere questo blog, Nvidia ha annunciato l’ultima serie 3000 della loro linea di GPU che sono dotate di architettura Volta. In questo, hanno migliorato le prestazioni dei core tensori di 2x. Anche portando nuovi valori di precisione come TF32 (tensor float 32), FP64 (floating point 64). Il TF32 funziona allo stesso modo di FP32 ma con una velocità fino a 20x, come risultato di tutto questo Nvidia, sostiene che il tempo di inferenza o formazione dei modelli sarà ridotto da settimane a ore.
AMD vs Nvidia

Le GPU AMD sono decenti per il gaming ma appena il deep learning entra in gioco, allora semplicemente Nvidia è molto avanti. Non significa che le GPU AMD siano cattive. È dovuto all’ottimizzazione del software e ai driver che non vengono aggiornati attivamente, sul lato Nvidia hanno driver migliori con aggiornamenti frequenti e in cima a quello CUDA, cuDNN aiuta ad accelerare il calcolo.
Alcune librerie ben note come Tensorflow, supporto PyTorch per CUDA. Significa che le GPU entry-level della serie GTX 1000 possono essere utilizzate. Sul lato AMD, ha pochissimo supporto software per le loro GPU. Sul lato hardware, Nvidia ha introdotto core tensoriali dedicati. AMD ha ROCm per l’accelerazione, ma non è buono come i tensor core, e molte librerie di deep learning non supportano ROCm. Negli ultimi anni, non è stato notato nessun grande salto in termini di prestazioni.
A causa di tutti questi punti, Nvidia semplicemente eccelle nel deep learning.
Sommario
Per concludere da tutto ciò che abbiamo imparato è chiaro che al momento Nvidia è il leader del mercato in termini di GPU, ma spero davvero che anche AMD raggiunga in futuro o almeno faccia alcuni miglioramenti notevoli nella prossima linea delle loro GPU come già stanno facendo un ottimo lavoro rispetto alle loro CPU i.e la serie Ryzen.
La portata delle GPU nei prossimi anni è enorme come facciamo nuove innovazioni e scoperte nel deep learning, machine learning e HPC. L’accelerazione GPU sarà sempre utile a molti sviluppatori e studenti per entrare in questo campo, dato che i loro prezzi stanno diventando sempre più accessibili. Grazie anche all’ampia comunità che contribuisce allo sviluppo dell’IA e dell’HPC.
Informazioni sull’autore

Prathmesh Patil
Appassionato diML, Data Science, sviluppatore Python.
LinkedIn: https://www.linkedin.com/in/prathmesh