Siden det seneste årti har vi set GPU’er komme mere hyppigt ind i billedet inden for områder som HPC (High-Performance Computing) og det mest populære område, nemlig spil. GPU’er er blevet forbedret år efter år, og nu er de i stand til at gøre nogle utroligt gode ting, men i de seneste par år har de fået endnu mere opmærksomhed på grund af deep learning.
 Da deep learning-modeller bruger en stor mængde tid på træning, var selv kraftige CPU’er ikke effektive nok til at håndtere så mange beregninger på et givet tidspunkt, og det er det område, hvor GPU’er simpelthen udkonkurrerede CPU’er på grund af deres parallelisme. Men før vi går i dybden, skal vi først forstå nogle ting om GPU.
Da deep learning-modeller bruger en stor mængde tid på træning, var selv kraftige CPU’er ikke effektive nok til at håndtere så mange beregninger på et givet tidspunkt, og det er det område, hvor GPU’er simpelthen udkonkurrerede CPU’er på grund af deres parallelisme. Men før vi går i dybden, skal vi først forstå nogle ting om GPU.
Hvad er en GPU?
En GPU eller “Graphics Processing Unit” er en miniudgave af en hel computer, men kun dedikeret til en specifik opgave. Den er i modsætning til en CPU, der udfører flere opgaver på samme tid. GPU’en kommer med sin egen processor, som er indbygget på sit eget bundkort kombineret med v-ram eller video ram, og også et ordentligt termisk design til ventilation og køling.
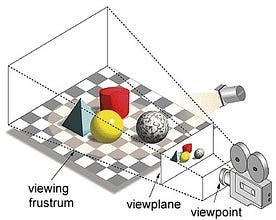
I udtrykket “Graphics Processing Unit” henviser “Graphics” til at gengive et billede ved bestemte koordinater i et 2d- eller 3d-rum. En viewport eller et viewpoint er en betragters perspektiv på et objekt, afhængigt af den anvendte projektionstype. Rasterisering og Ray-tracing er nogle af de måder at gengive 3d-scener på, og begge disse koncepter er baseret på en type projektion, der kaldes perspektivprojektion. Hvad er perspektivprojektion?
Kort sagt er det den måde, hvorpå et billede dannes på et visningsplan eller lærred, hvor de parallelle linjer konvergerer til et konvergerende punkt, der kaldes “projektionscentrum”, og når objektet bevæger sig væk fra udsigtspunktet, synes det at blive mindre, præcis som vores øjne skildrer i den virkelige verden, og det hjælper også med at forstå dybden i et billede, og det er grunden til, at det giver realistiske billeder.
Dertil kommer, at GPU’er også behandler kompleks geometri, vektorer, lyskilder eller belysninger, teksturer, figurer osv. Da vi nu har en grundlæggende idé om GPU’er, skal vi forstå, hvorfor den bruges meget til dyb læring.
Hvorfor GPU’er er bedre til dyb læring?
Et af de mest beundrede kendetegn ved en GPU er evnen til at beregne processer parallelt. Dette er det punkt, hvor begrebet parallelberegning træder i kraft. En CPU udfører generelt sin opgave på en sekventiel måde. En CPU kan opdeles i kerner, og hver kerne tager sig af en opgave ad gangen. Lad os antage, at en CPU har 2 kerner. Så kan to forskellige opgaveprocesser køre på disse to kerner og dermed opnå multitasking.
Men disse processer udføres stadig på en seriel måde.

Det betyder ikke, at CPU’er ikke er gode nok. Faktisk er CPU’er virkelig gode til at håndtere forskellige opgaver i forbindelse med forskellige operationer som f.eks. håndtering af operativsystemer, håndtering af regneark, afspilning af HD-videoer, udpakning af store zip-filer, alt sammen på samme tid. Det er nogle ting, som en GPU simpelthen ikke kan klare.
Hvor ligger forskellen?
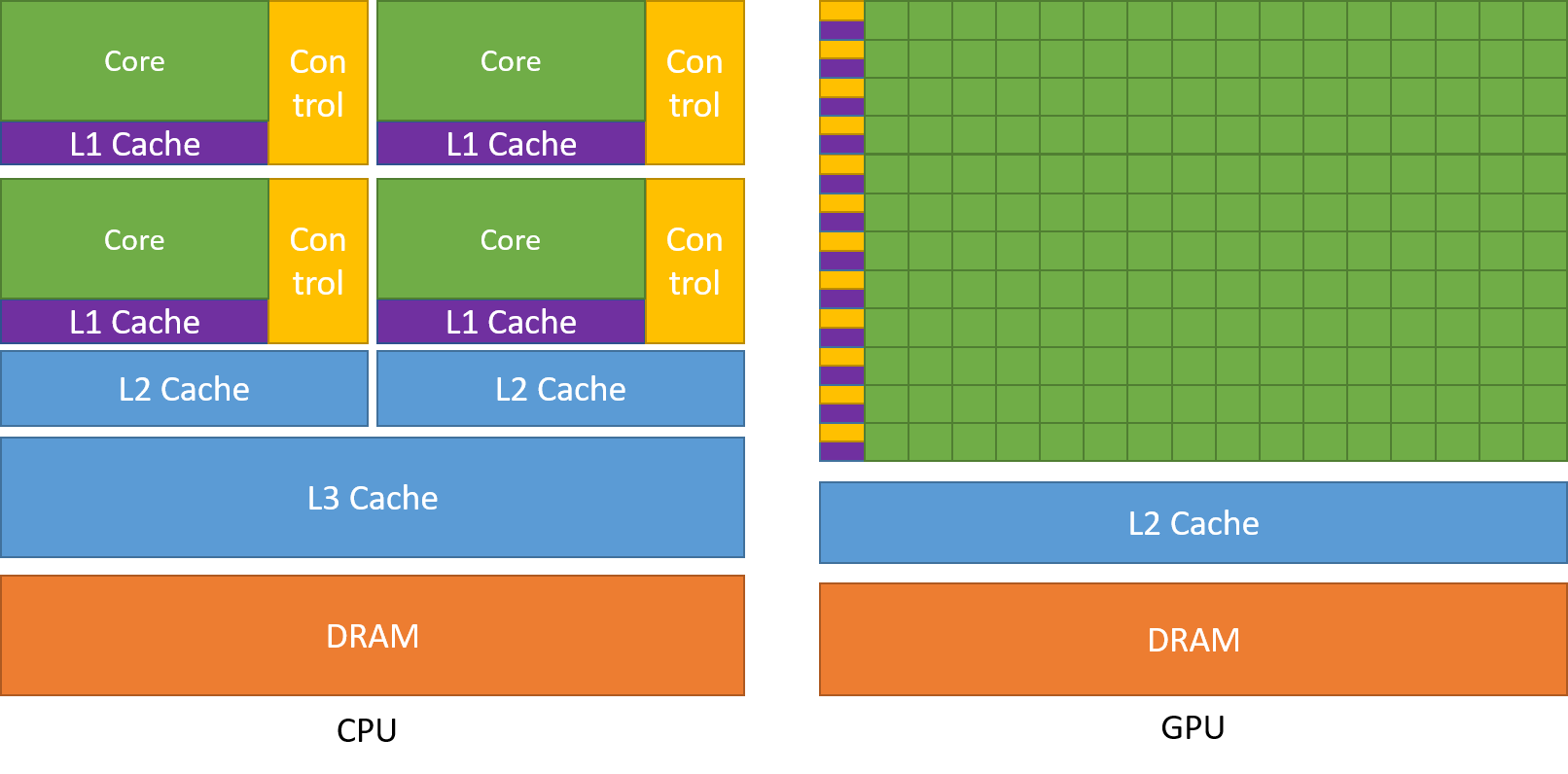
Som tidligere omtalt er en CPU opdelt i flere kerner, så de kan påtage sig flere opgaver på samme tid, hvorimod GPU’en vil have hundredvis og tusindvis af kerner, som alle er dedikeret til en enkelt opgave. Der er tale om simple beregninger, der udføres hyppigere og er uafhængige af hinanden. Og begge gemmer ofte nødvendige data i deres respektive cache-hukommelse og følger dermed princippet om “locality reference”.
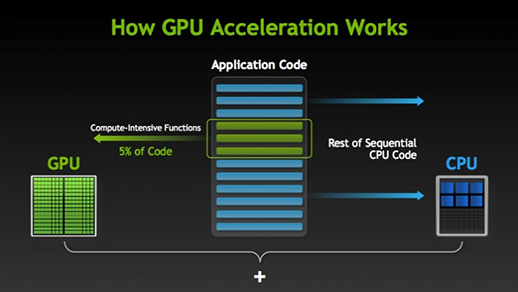
Der er mange programmer og spil, der kan drage fordel af GPU’er til eksekvering. Ideen bag dette er at gøre nogle dele af opgaven eller programkoden parallel, men ikke hele processerne. Dette skyldes, at de fleste af processerne i opgaven kun skal udføres sekventielt. F.eks. er det ikke nødvendigt at logge ind på et system eller en applikation, der skal gøres parallelt.
Når der er en del af udførelsen, der kan udføres parallelt, flyttes den simpelthen til GPU til behandling, hvor den sekventielle opgave på samme tid udføres i CPU, hvorefter begge dele af opgaven igen kombineres sammen. På GPU-markedet er der to hovedaktører, nemlig AMD og Nvidia. Nvidias GPU’er anvendes i vid udstrækning til deep learning, fordi de har omfattende støtte i forumsoftware, drivere, CUDA og cuDNN. Så når det gælder AI og deep learning, er Nvidia pioner i lang tid.
Neurale netværk siges at være pinligt parallelle, hvilket betyder, at beregninger i neurale netværk nemt kan udføres parallelt, og at de er uafhængige af hinanden.
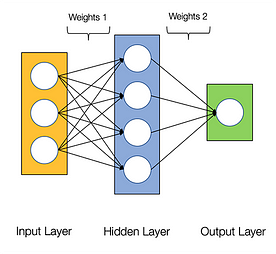
Nogle beregninger som f.eks. beregning af vægte og aktiveringsfunktioner for hvert lag, backpropagation kan udføres parallelt. Der findes også mange forskningsartikler om det.
Nvidia GPU’er leveres med specialiserede kerner kendt som CUDA-kerner, som hjælper med at accelerere deep learning.
Hvad er CUDA?
CUDA står for ‘Compute Unified Device Architecture’, som blev lanceret i 2007, og det er en måde, hvorpå du kan opnå parallel beregning og få mest muligt ud af din GPU-kraft på en optimeret måde, hvilket resulterer i meget bedre ydeevne, mens du udfører opgaver.

CUDA-værktøjssættet er en komplet pakke, der består af et udviklingsmiljø, som bruges til at bygge applikationer, der gør brug af GPU’er. Dette værktøjssæt indeholder hovedsageligt c/c++-kompiler, debugger og biblioteker. Desuden har CUDA-køringstiden sine drivere, så den kan kommunikere med GPU’en. CUDA er også et programmeringssprog, der er specielt lavet til at instruere GPU’en til at udføre en opgave. Det er også kendt som GPU-programmering.
Nedenfor er et simpelt hello world-program, bare for at få en idé om, hvordan CUDA-kode ser ud.
/* hello world program in cuda *\#include<stdio.h>#include<stdlib.h>#include<cuda.h>__global__ void demo() { printf("hello world!,my first cuda program");}int main() { printf("From main!\n"); demo<<<1,1>>>(); return 0;}

Hvad er cuDNN?

cuDNN er et neuralt netværksbibliotek, der er GPU-optimeret og kan udnytte Nvidia GPU fuldt ud. Dette bibliotek består af implementeringen af konvolution, fremadrettet og bagudrettet propagation, aktiveringsfunktioner og pooling. Det er et must-bibliotek, uden hvilket du ikke kan bruge GPU til træning af neurale netværk.
Et stort spring med Tensor cores!
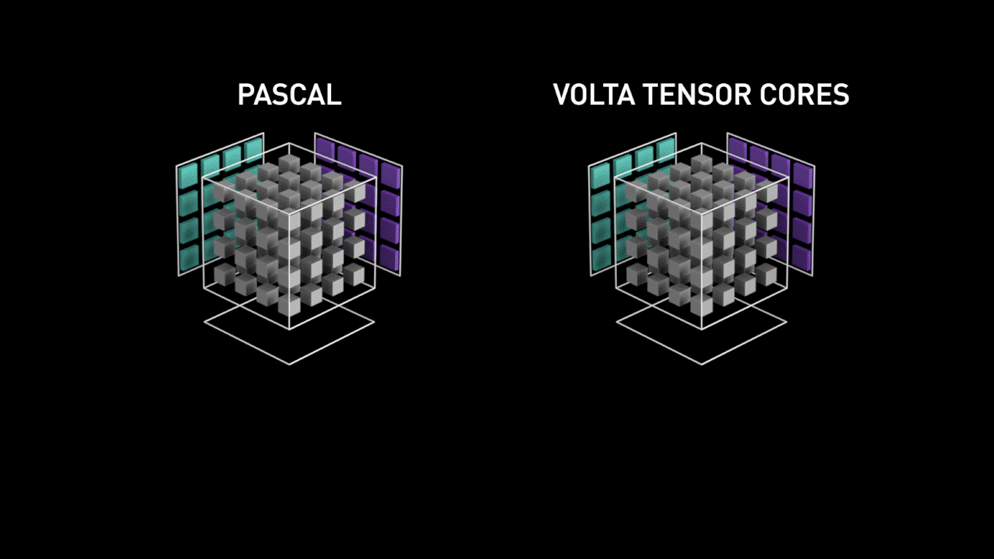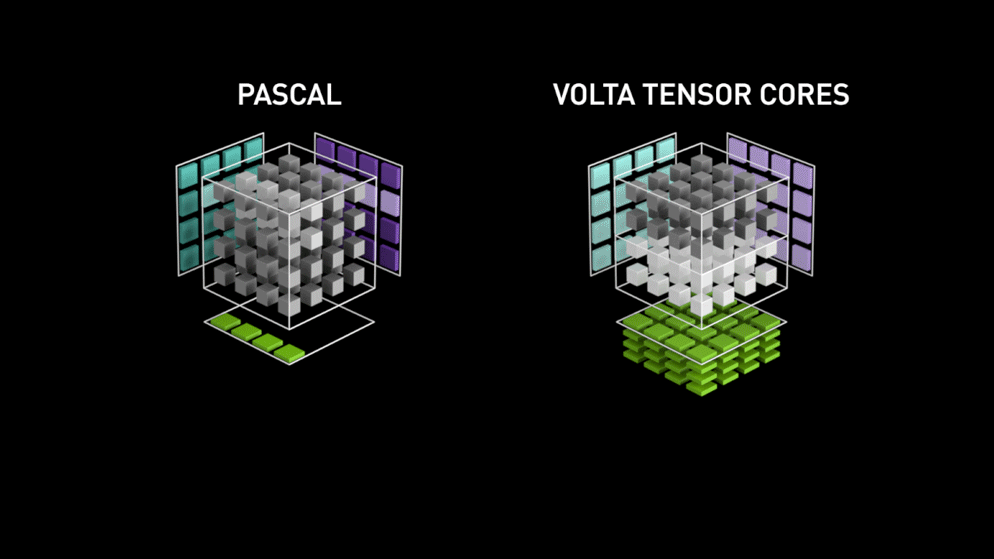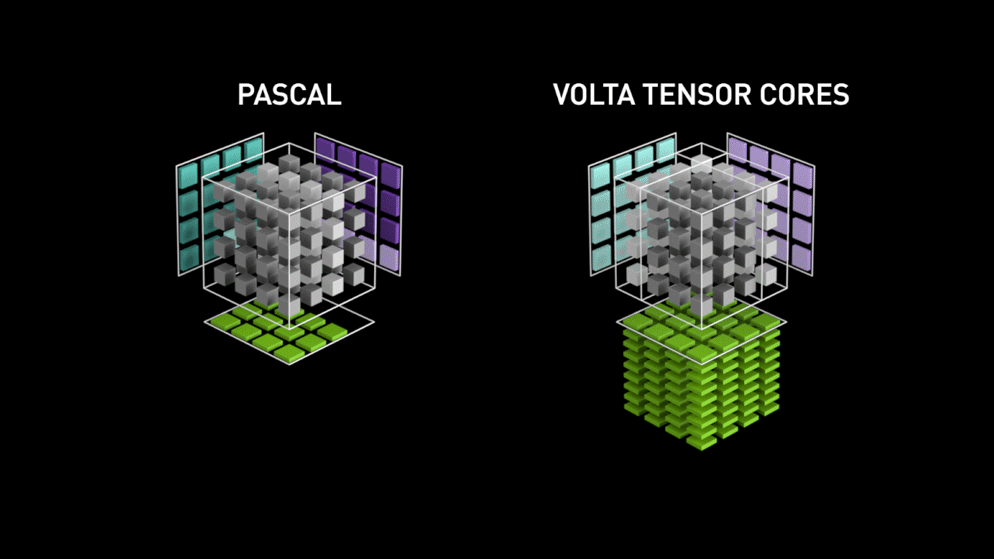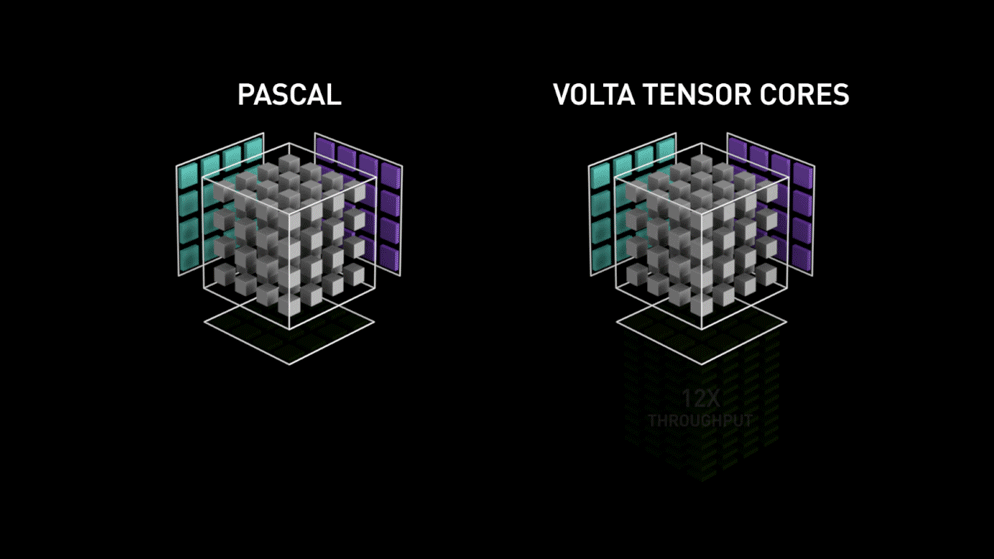
Bag i 2018 lancerede Nvidia et nyt lineup af deres GPU’er, nemlig 2000-serien. Disse kort, der også kaldes RTX, kommer med tensor-kerner, der er dedikeret til deep learning og er baseret på Volta-arkitekturen.

Tensorkerner er særlige kerner, der udfører matrixmultiplikation af 4 x 4 FP16-matrix og addition med 4 x 4 matrix FP16 eller FP32 i halvpræcision, resultatet vil være en 4 x 4 FP16- eller FP32-matrix med fuld præcision.
Bemærk: “FP” står for floating-point for at forstå mere om floating-point og præcision, se denne blog. Som anført af Nvidia er den nye generation af tensorkerner baseret på volta-arkitekturen meget hurtigere end CUDA-kerner baseret på Pascal-arkitekturen. Dette gav et kæmpe boost til deep learning.
På det tidspunkt, hvor denne blog blev skrevet, annoncerede Nvidia den seneste 3000-serie af deres GPU-lineup, som kommer med Ampere-arkitektur. I denne har de forbedret ydelsen af tensor cores med 2x. Også bringe nye præcisionsværdier som TF32(tensor float 32), FP64(floating point 64). TF32 fungerer på samme måde som FP32, men med en hastighedsforøgelse på op til 20x, og som følge af alt dette hævder Nvidia, at inferens- eller træningstiden for modeller vil blive reduceret fra uger til timer.
AMD vs Nvidia

AMD GPU’er er anstændige til spil, men så snart deep learning kommer ind i billedet, så er simpelthen Nvidia langt foran. Det betyder ikke, at AMD GPU’er er dårlige. Det skyldes softwareoptimering og drivere, som ikke bliver opdateret aktivt, på Nvidia-siden har de bedre drivere med hyppige opdateringer og oven i købet CUDA, cuDNNN hjælper med at fremskynde beregningen.
En del velkendte biblioteker som Tensorflow, PyTorch understøtter CUDA. Det betyder, at entry-level GPU’er i GTX 1000-serien kan bruges. På AMD-siden har det meget lidt softwareunderstøttelse til deres GPU’er. På hardwaresiden har Nvidia introduceret dedikerede tensor cores. AMD har ROCm til acceleration, men det er ikke godt som tensor cores, og mange deep learning biblioteker understøtter ikke ROCm. I de sidste par år har man ikke bemærket noget stort spring i ydeevne.
På grund af alle disse punkter udmærker Nvidia sig ganske enkelt inden for deep learning.
Summary
For at konkludere fra alt det, vi har lært, er det klart, at Nvidia fra nu af er markedsleder med hensyn til GPU’er, men jeg håber virkelig, at selv AMD indhenter dem i fremtiden eller i det mindste laver nogle bemærkelsesværdige forbedringer i det kommende lineup af deres GPU’er, da de allerede gør et godt stykke arbejde med hensyn til deres CPU’er i.e Ryzen-serien.
Den rækkevidde af GPU’er i de kommende år er enorm, da vi laver nye innovationer og gennembrud inden for deep learning, machine learning og HPC. GPU-acceleration vil altid være praktisk for mange udviklere og studerende for at komme ind på dette område, da deres priser også bliver mere overkommelige. Også tak til det brede fællesskab, der også bidrager til udviklingen af AI og HPC.
Om forfatteren

Prathmesh Patil
ML-entusiast, Data Science, Python-udvikler.
LinkedIn: https://www.linkedin.com/in/prathmesh