Seit dem letzten Jahrzehnt haben wir gesehen, wie GPUs immer häufiger in Bereichen wie HPC (High-Performance Computing) und dem beliebtesten Bereich, dem Gaming, zum Einsatz kommen. GPUs haben sich Jahr für Jahr verbessert und sind nun in der Lage, einige unglaublich großartige Dinge zu tun, aber in den letzten Jahren haben sie aufgrund von Deep Learning noch mehr Aufmerksamkeit auf sich gezogen.

Da Deep-Learning-Modelle viel Zeit mit dem Training verbringen, waren selbst leistungsstarke CPUs nicht effizient genug, um so viele Berechnungen in einer bestimmten Zeit zu bewältigen, und dies ist der Bereich, in dem GPUs die CPUs aufgrund ihrer Parallelität einfach übertreffen. Doch bevor wir in die Tiefe gehen, sollten wir zunächst einige Dinge über GPUs verstehen.
Was ist eine GPU?
Eine GPU oder „Graphics Processing Unit“ ist eine Miniversion eines ganzen Computers, die nur für eine bestimmte Aufgabe zuständig ist. Sie unterscheidet sich von einer CPU, die mehrere Aufgaben gleichzeitig ausführt. Die GPU verfügt über einen eigenen Prozessor, der auf einer eigenen Hauptplatine zusammen mit V-Ram oder Video-Ram untergebracht ist, sowie über ein geeignetes thermisches Design für Belüftung und Kühlung.
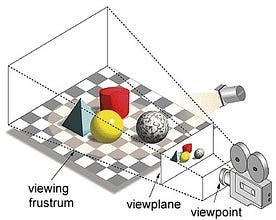
Unter dem Begriff „Graphics Processing Unit“ versteht man das Rendern eines Bildes an bestimmten Koordinaten in einem 2D- oder 3D-Raum. Ein Viewport oder Viewpoint ist der Blickwinkel des Betrachters auf ein Objekt, abhängig von der Art der Projektion. Rasterisierung und Ray-tracing sind einige der Möglichkeiten, 3D-Szenen zu rendern. Beide Konzepte basieren auf einer Art von Projektion, die als perspektivische Projektion bezeichnet wird. Was ist perspektivische Projektion?
Kurz gesagt, ist es die Art und Weise, wie ein Bild auf einer Ansichtsebene oder Leinwand geformt wird, wo die parallelen Linien zu einem konvergierenden Punkt konvergieren, der als „Zentrum der Projektion“ bezeichnet wird, und wenn sich das Objekt vom Blickpunkt entfernt, erscheint es kleiner, genau wie unsere Augen es in der realen Welt darstellen, und dies hilft auch beim Verständnis der Tiefe in einem Bild, weshalb realistische Bilder erzeugt werden.
Außerdem verarbeiten GPUs auch komplexe Geometrien, Vektoren, Lichtquellen oder Beleuchtungen, Texturen, Formen, usw. Da wir nun eine grundlegende Vorstellung von GPUs haben, wollen wir verstehen, warum sie so häufig für Deep Learning eingesetzt werden.
Warum sind GPUs besser für Deep Learning?
Eine der am meisten bewunderten Eigenschaften eines GPUs ist die Fähigkeit, Prozesse parallel zu berechnen. An diesem Punkt setzt das Konzept des parallelen Rechnens ein. Eine CPU erledigt ihre Aufgaben im Allgemeinen sequentiell. Eine CPU kann in Kerne unterteilt werden, wobei jeder Kern eine Aufgabe auf einmal übernimmt. Angenommen, eine CPU hat 2 Kerne. Dann können zwei verschiedene Aufgabenprozesse auf diesen beiden Kernen laufen, wodurch Multitasking erreicht wird.
Aber dennoch werden diese Prozesse seriell ausgeführt.

Das bedeutet nicht, dass CPUs nicht gut genug sind. In der Tat sind CPUs wirklich gut darin, verschiedene Aufgaben im Zusammenhang mit unterschiedlichen Operationen zu bewältigen, wie z. B. die Handhabung von Betriebssystemen, die Bearbeitung von Tabellenkalkulationen, die Wiedergabe von HD-Videos, das Extrahieren großer Zip-Dateien, und das alles zur gleichen Zeit. Dies sind einige Dinge, die ein Grafikprozessor einfach nicht kann.
Wo liegt der Unterschied?
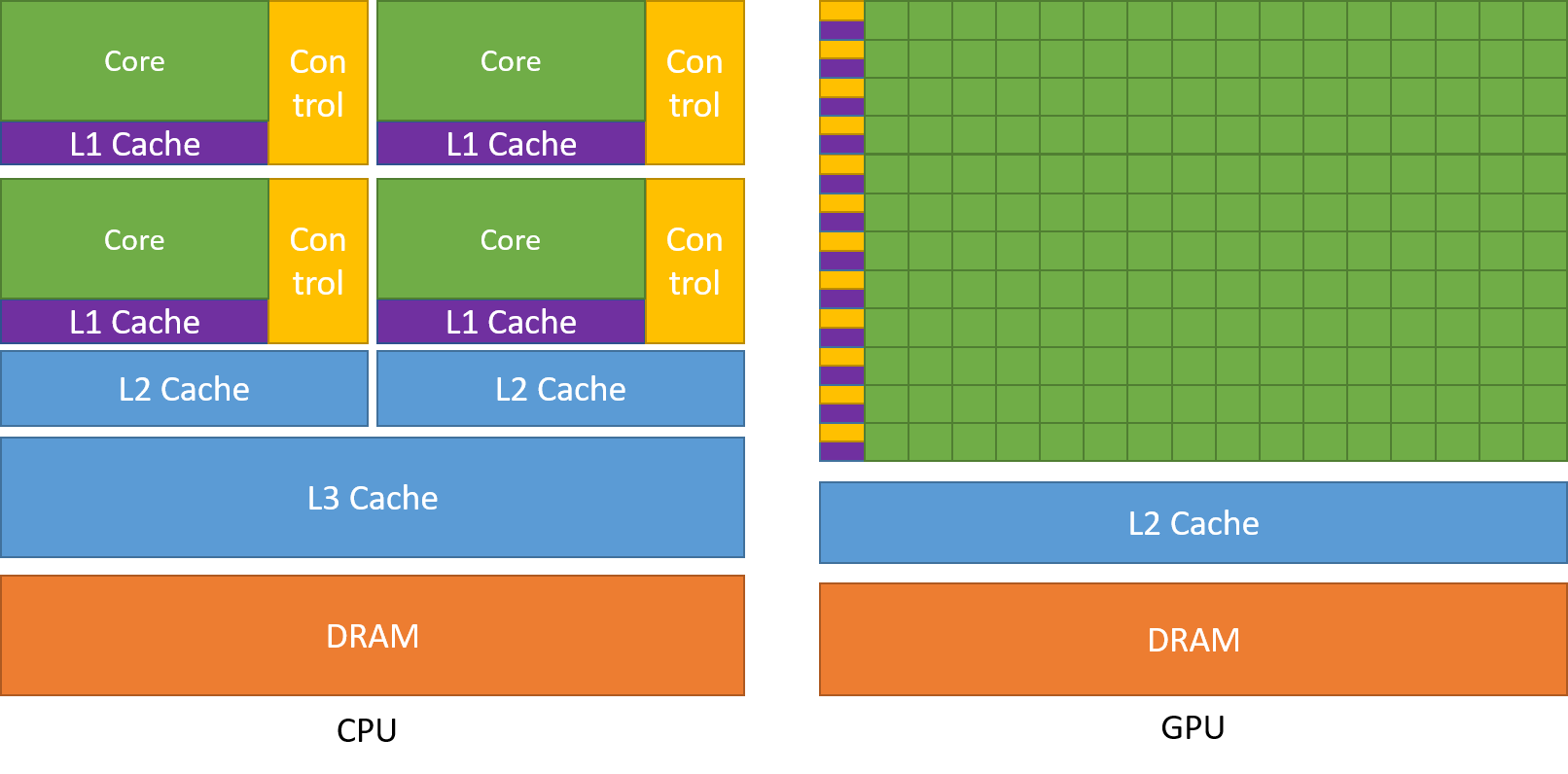
Wie bereits erwähnt, ist eine CPU in mehrere Kerne unterteilt, damit sie mehrere Aufgaben gleichzeitig übernehmen kann, Ein Grafikprozessor hingegen verfügt über Hunderte und Tausende von Kernen, die alle für eine einzige Aufgabe zuständig sind. Dabei handelt es sich um einfache Berechnungen, die häufiger durchgeführt werden und voneinander unabhängig sind. Und beide speichern häufig benötigte Daten in ihrem jeweiligen Cache-Speicher und folgen damit dem Prinzip des „Ortsbezugs“.
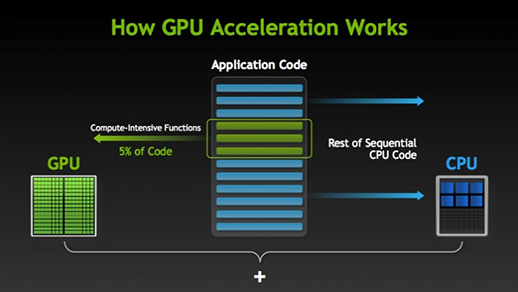
Es gibt viele Software und Spiele, die GPUs zur Ausführung nutzen können. Die Idee dahinter ist, einige Teile der Aufgabe oder des Anwendungscodes zu parallelisieren, aber nicht den gesamten Prozess. Der Grund dafür ist, dass die meisten Prozesse der Aufgabe nur sequentiell ausgeführt werden müssen. Zum Beispiel muss die Anmeldung bei einem System oder einer Anwendung nicht parallel erfolgen.
Wenn es einen Teil der Ausführung gibt, der parallel ausgeführt werden kann, wird er einfach zur Verarbeitung auf die GPU verlagert, wo zur gleichen Zeit eine sequenzielle Aufgabe in der CPU ausgeführt wird, und dann werden beide Teile der Aufgabe wieder miteinander kombiniert.
Auf dem GPU-Markt gibt es zwei Hauptakteure, nämlich AMD und Nvidia. Nvidia-GPUs werden häufig für Deep Learning verwendet, da sie umfangreiche Unterstützung in der Forumssoftware, den Treibern, CUDA und cuDNN haben. In Bezug auf KI und Deep Learning ist Nvidia also seit langem der Pionier.
Neuronale Netze gelten als peinlich parallel, was bedeutet, dass Berechnungen in neuronalen Netzen leicht parallel ausgeführt werden können und sie unabhängig voneinander sind.
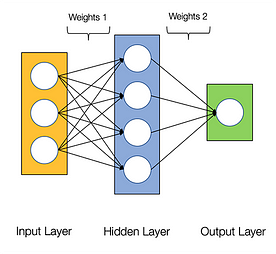
Einige Berechnungen wie die Berechnung der Gewichte und Aktivierungsfunktionen der einzelnen Schichten, Backpropagation können parallel ausgeführt werden.
Nvidia-GPUs sind mit speziellen Kernen ausgestattet, die als CUDA-Kerne bekannt sind und bei der Beschleunigung von Deep Learning helfen.
Was ist CUDA?
CUDA steht für „Compute Unified Device Architecture“, die im Jahr 2007 eingeführt wurde. Es ist eine Methode, mit der Sie paralleles Rechnen erreichen und die GPU-Leistung optimal nutzen können, was zu einer viel besseren Leistung bei der Ausführung von Aufgaben führt.

Das CUDA-Toolkit ist ein komplettes Paket, das aus einer Entwicklungsumgebung besteht, die zur Erstellung von Anwendungen verwendet wird, die von GPUs Gebrauch machen. Dieses Toolkit enthält hauptsächlich einen C/C++-Compiler, einen Debugger und Bibliotheken. Außerdem verfügt die CUDA-Laufzeitumgebung über eigene Treiber, um mit dem Grafikprozessor kommunizieren zu können. CUDA ist auch eine Programmiersprache, die speziell für die Anweisung an die GPU zur Ausführung einer Aufgabe entwickelt wurde. Es ist auch als GPU-Programmierung bekannt.
Unten ist ein einfaches Hallo-Welt-Programm, um eine Vorstellung davon zu bekommen, wie CUDA-Code aussieht.
/* hello world program in cuda *\#include<stdio.h>#include<stdlib.h>#include<cuda.h>__global__ void demo() { printf("hello world!,my first cuda program");}int main() { printf("From main!\n"); demo<<<1,1>>>(); return 0;}

Was ist cuDNN?

cuDNN ist eine Bibliothek für neuronale Netze, die GPU-optimiert ist und die Vorteile der Nvidia GPU voll ausschöpfen kann. Diese Bibliothek besteht aus der Implementierung von Faltung, Vorwärts- und Rückwärtspropagation, Aktivierungsfunktionen und Pooling. Es ist eine unverzichtbare Bibliothek, ohne die Sie GPU für das Training neuronaler Netze nicht verwenden können.
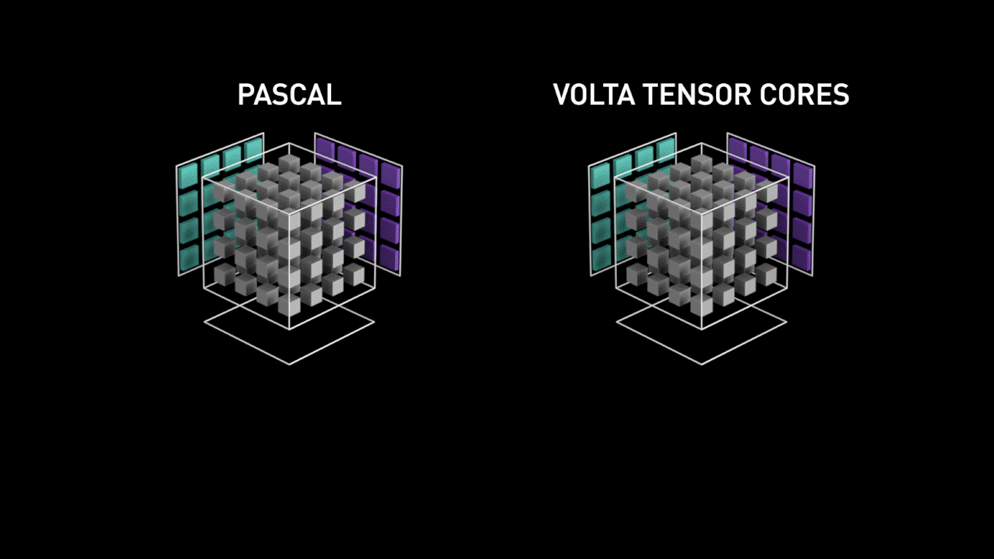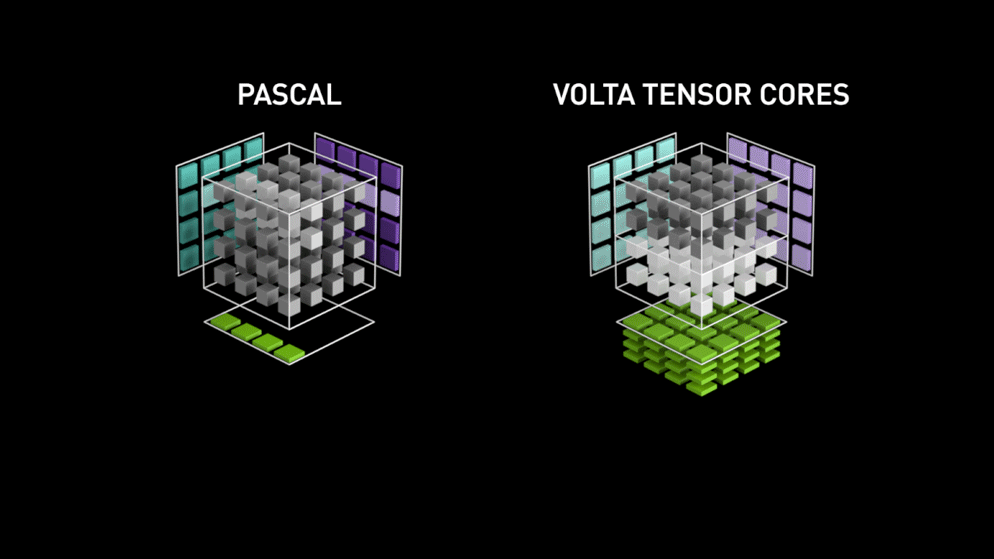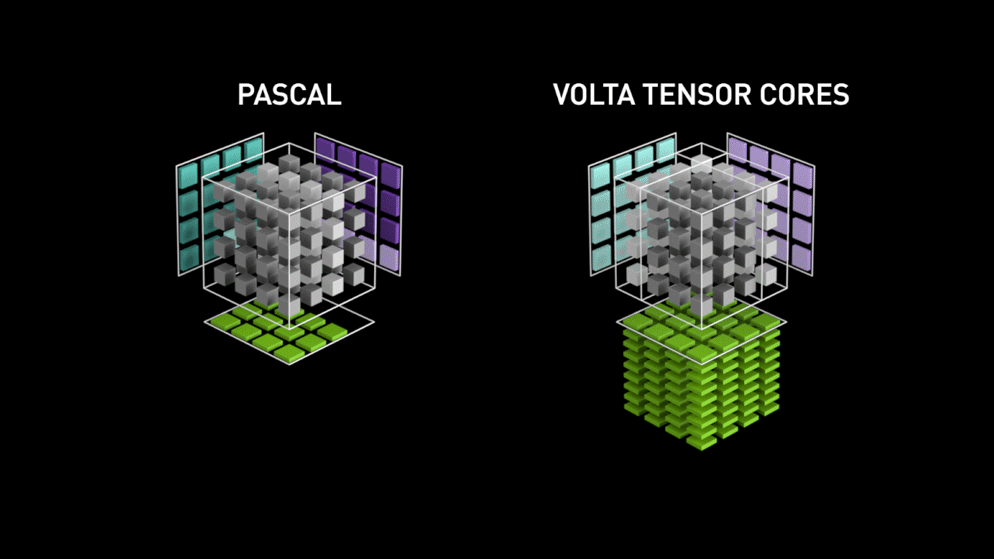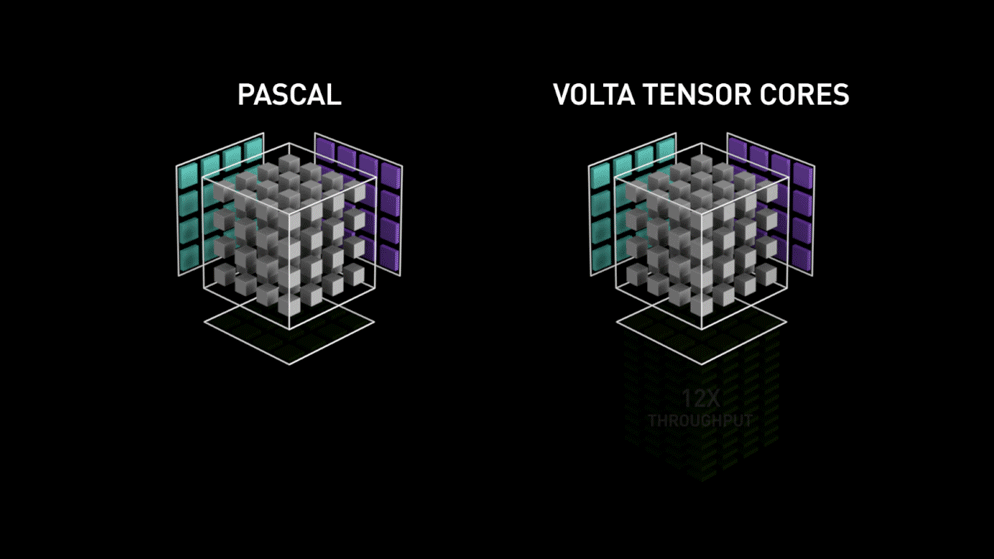
Ein großer Sprung mit Tensor-Kernen!
Im Jahr 2018 hat Nvidia eine neue Reihe seiner GPUs, die 2000-Serie, auf den Markt gebracht. Diese Karten, die auch RTX genannt werden, kommen mit Tensor-Kernen, die für Deep Learning bestimmt sind und auf der Volta-Architektur basieren.

Tensorkerne sind besondere Kerne, die eine Matrixmultiplikation mit einer 4 x 4 FP16-Matrix und eine Addition mit einer 4 x 4-Matrix FP16 oder FP32 in halber Genauigkeit durchführen, das Ergebnis ist eine 4 x 4 FP16- oder FP32-Matrix mit voller Genauigkeit.
Anmerkung: ‚FP‘ steht für Fließkomma, um mehr über Fließkomma und Präzision zu verstehen, lesen Sie diesen Blog.
Wie von Nvidia angegeben, ist die neue Generation von Tensor-Cores auf Basis der Volta-Architektur viel schneller als CUDA-Cores auf Basis der Pascal-Architektur. Dies gab dem Deep Learning einen enormen Schub.
Zum Zeitpunkt des Schreibens dieses Blogs kündigte Nvidia die neueste 3000er-Serie seines GPU-Lineups an, die mit der Ampere-Architektur kommt. Dabei wurde die Leistung der Tensor-Kerne um den Faktor 2 verbessert. Außerdem wurden neue Präzisionswerte wie TF32 (Tensor Float 32) und FP64 (Floating Point 64) eingeführt. Der TF32 arbeitet genauso wie FP32, aber mit einer Beschleunigung von bis zu 20x, als Ergebnis von all dem behauptet Nvidia, dass die Inferenz- oder Trainingszeit von Modellen von Wochen auf Stunden reduziert werden kann.
AMD vs Nvidia

AMD-GPUs sind für Spiele gut geeignet, aber sobald Deep Learning ins Spiel kommt, ist Nvidia einfach weit voraus. Das bedeutet nicht, dass AMD-GPUs schlecht sind. Es liegt an der Software-Optimierung und den Treibern, die nicht aktiv aktualisiert werden, auf der Nvidia-Seite haben sie bessere Treiber mit häufigen Updates und obendrein helfen CUDA, cuDNN dabei, die Berechnungen zu beschleunigen.
Einige bekannte Bibliotheken wie Tensorflow, PyTorch unterstützen CUDA. Das bedeutet, dass Einsteiger-GPUs der GTX 1000-Serie verwendet werden können. Auf der AMD-Seite gibt es nur sehr wenig Software-Unterstützung für ihre GPUs. Auf der Hardwareseite hat Nvidia dedizierte Tensorkerne eingeführt. AMD hat ROCm zur Beschleunigung, aber es ist nicht so gut wie Tensor-Cores, und viele Deep-Learning-Bibliotheken unterstützen ROCm nicht. In den letzten Jahren wurde kein großer Sprung in Bezug auf die Leistung festgestellt.
Aufgrund all dieser Punkte ist Nvidia im Deep Learning einfach überragend.
Zusammenfassung
Aus all dem, was wir gelernt haben, lässt sich schließen, dass Nvidia im Moment der Marktführer in Bezug auf GPUs ist, aber ich hoffe wirklich, dass sogar AMD in Zukunft aufholt oder zumindest einige bemerkenswerte Verbesserungen in der kommenden Reihe ihrer GPUs vornimmt, da sie in Bezug auf ihre CPUs, z. B. die Ryzen-Reihe, bereits einen großartigen Job machen.
Die Möglichkeiten von GPUs in den kommenden Jahren sind enorm, da wir neue Innovationen und Durchbrüche in den Bereichen Deep Learning, maschinelles Lernen und HPC erzielen. Die GPU-Beschleunigung wird vielen Entwicklern und Studenten den Einstieg in diesen Bereich erleichtern, da ihre Preise immer erschwinglicher werden. Auch dank der großen Gemeinschaft, die ebenfalls zur Entwicklung von KI und HPC beiträgt.
Über den Autor

Prathmesh Patil
ML-Enthusiast, Data Science, Python-Entwickler.
LinkedIn: https://www.linkedin.com/in/prathmesh