Az elmúlt évtized óta egyre gyakrabban látjuk, hogy a GPU egyre gyakrabban kerül a képbe olyan területeken, mint a HPC (High-Performance Computing) és a legnépszerűbb terület, azaz a játék. A GPU-k évről évre fejlődtek, és ma már hihetetlenül nagyszerű dolgokra képesek, de az elmúlt néhány évben még nagyobb figyelmet kaptak a mélytanulás miatt.

Mivel a mélytanulási modellek nagy mennyiségű időt töltenek a képzéssel, még az erős CPU-k sem voltak elég hatékonyak ahhoz, hogy soo sok számítást kezeljenek egy adott időben, és ez az a terület, ahol a GPU-k egyszerűen felülmúlták a CPU-kat a párhuzamosság miatt. De mielőtt belemerülnénk a mélységbe, először értsünk meg néhány dolgot a GPU-ról.
Mi a GPU?
A GPU vagy “grafikus feldolgozó egység” a teljes számítógép mini változata, de csak egy adott feladatra szánt. Ellentétben a CPU-val, amely egyszerre több feladatot is elvégez. A GPU saját processzorral rendelkezik, amely a saját alaplapjára van beágyazva, v-ram vagy video rammal párosítva, valamint megfelelő hőkialakítással a szellőzés és hűtés érdekében.
Röviden, ez az a mód, ahogyan egy kép kialakul egy nézetsíkon vagy vásznon, ahol a párhuzamos vonalak egy konvergáló pontba futnak össze, amelyet “vetítési középpontnak” neveznek, és ahogy a tárgy távolodik a nézőpontból, úgy tűnik, hogy kisebb, pontosan úgy, ahogyan a szemünk a valós világban ábrázolja, és ez segít a kép mélységének megértésében is, ez az oka annak, hogy valósághű képeket készít.
A GPU-k emellett komplex geometriát, vektorokat, fényforrásokat vagy megvilágításokat, textúrákat, alakzatokat stb. is feldolgoznak. Mivel most már van egy alapvető elképzelésünk a GPU-ról, értsük meg, miért használják nagymértékben a mélytanuláshoz.
Miért jobbak a GPU-k a mélytanuláshoz?
A GPU egyik legcsodáltabb tulajdonsága a párhuzamos folyamatok számításának képessége. Ez az a pont, ahol a párhuzamos számítás fogalma beindul. Egy CPU általában szekvenciális módon végzi el a feladatát. Egy CPU magokra osztható, és minden mag egyszerre egy-egy feladatot lát el. Tegyük fel, hogy a CPU-nak 2 magja van. Akkor két különböző feladat folyamata futhat ezen a két magon, ezáltal megvalósítva a multitaskingot.
Mégis ezek a folyamatok soros módon hajtódnak végre.

Ez nem azt jelenti, hogy a CPU-k nem elég jók. Valójában a CPU-k nagyon is jól kezelik a különböző műveletekhez kapcsolódó különböző feladatokat, például az operációs rendszerek kezelését, a táblázatkezelést, a HD-videók lejátszását, a nagyméretű zip-fájlok kicsomagolását, mindezt egyszerre. Ezek olyan dolgok, amelyekre egy GPU egyszerűen nem képes.
Hol a különbség?
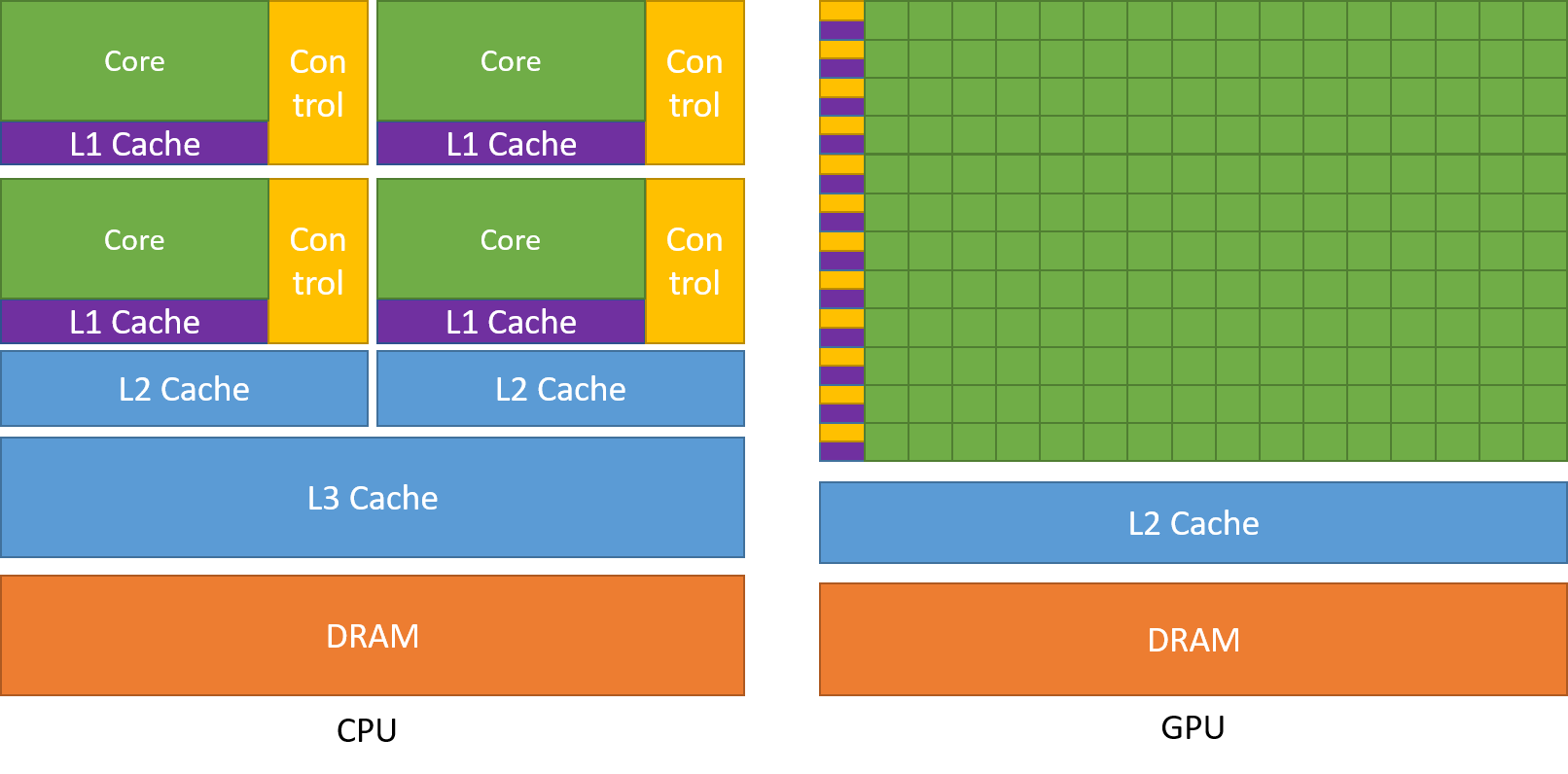
Amint korábban tárgyaltuk, egy CPU több magra van osztva, hogy egyszerre több feladatot is el tudjon látni, míg a GPU több száz és több ezer maggal rendelkezik, amelyek mindegyike egyetlen feladatra szolgál. Ezek egyszerű számítások, amelyeket gyakrabban végeznek el, és amelyek függetlenek egymástól. És mindkettő a gyakran szükséges adatokat a saját cache-memóriájába tárolja, így követve a “lokalitáshivatkozás” elvét.
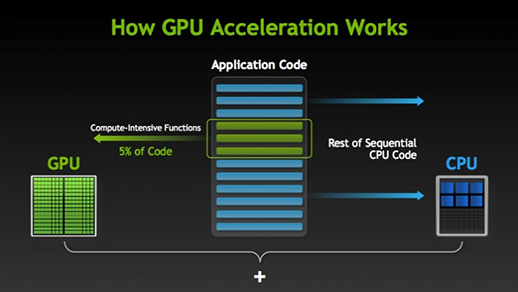
Egy csomó szoftver és játék képes kihasználni a GPU-kat a végrehajtáshoz. Ennek lényege, hogy a feladat vagy az alkalmazáskód egyes részeit párhuzamosítják, de nem a teljes folyamatokat. Ennek oka, hogy a feladat folyamatainak nagy részét csak szekvenciálisan kell végrehajtani. Például egy rendszerbe vagy alkalmazásba való bejelentkezést nem kell párhuzamosítani.
Ahol a végrehajtás egy része párhuzamosan elvégezhető, azt egyszerűen a GPU-ra helyezik át feldolgozásra, ahol ugyanakkor a szekvenciális feladatot a CPU-n hajtják végre, majd a feladat mindkét részét ismét egyesítik.
A GPU-piacon két fő szereplő van, az AMD és az Nvidia. Az Nvidia GPU-kat széles körben használják a mélytanuláshoz, mivel széles körű támogatással rendelkeznek a fórumszoftverekben, az illesztőprogramokban, a CUDA-ban és a cuDNN-ben. Tehát a mesterséges intelligencia és a mélytanulás tekintetében az Nvidia hosszú ideje úttörőnek számít.
A neurális hálózatokról azt mondják, hogy zavarba ejtően párhuzamosak, ami azt jelenti, hogy a neurális hálózatokban végzett számítások könnyen párhuzamosan végezhetők, és egymástól függetlenek.
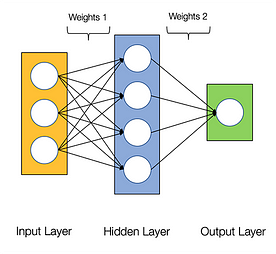
Egyes számítások, például az egyes rétegek súlyainak és aktivációs függvényeinek kiszámítása, a backpropagáció párhuzamosan végezhetők. Erről számos kutatási cikk is rendelkezésre áll.
A Nvidia GPU-k speciális magokkal, úgynevezett CUDA magokkal rendelkeznek, amelyek segítenek a mélytanulás felgyorsításában.
Mi az a CUDA?
A CUDA a ‘Compute Unified Device Architecture’ rövidítése, amelyet 2007-ben indítottak el, és egy olyan módszer, amellyel párhuzamos számítást érhet el, és optimalizált módon hozhatja ki a legtöbbet a GPU teljesítményéből, ami sokkal jobb teljesítményt eredményez a feladatok végrehajtása során.

A CUDA toolkit egy teljes csomag, amely egy olyan fejlesztői környezetből áll, amelyet a GPU-kat kihasználó alkalmazások készítéséhez használnak. Ez az eszközkészlet elsősorban c/c++ fordítót, debuggert és könyvtárakat tartalmaz. Emellett a CUDA futtatóprogramnak is megvannak az illesztőprogramjai, hogy kommunikálni tudjon a GPU-val. A CUDA egy olyan programozási nyelv is, amely kifejezetten a GPU utasítására készült egy feladat elvégzésére. GPU-programozásnak is nevezik.
Az alábbiakban egy egyszerű hello world programot mutatunk be, csak hogy képet kapjunk arról, hogyan néz ki a CUDA kód.
/* hello world program in cuda *\#include<stdio.h>#include<stdlib.h>#include<cuda.h>__global__ void demo() { printf("hello world!,my first cuda program");}int main() { printf("From main!\n"); demo<<<1,1>>>(); return 0;}

Mi a cuDNN?

a cuDNN egy neurális hálózati könyvtár, amely GPU optimalizált és teljes mértékben ki tudja használni az Nvidia GPU előnyeit. Ez a könyvtár a konvolúció, az előre és hátrafelé terjedés, az aktiválási függvények és a pooling megvalósításából áll. Ez egy kötelező könyvtár, amely nélkül nem lehet GPU-t használni neurális hálózatok képzésére.
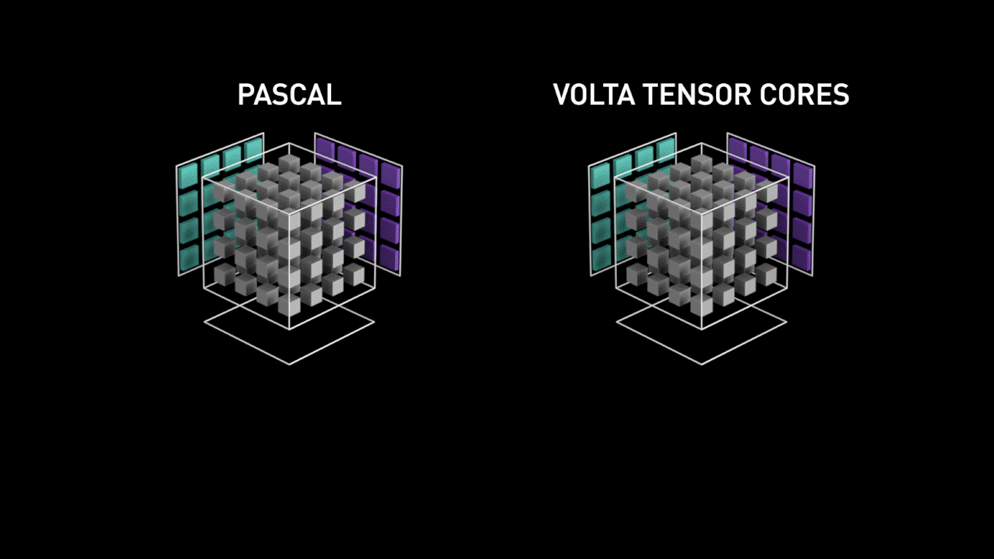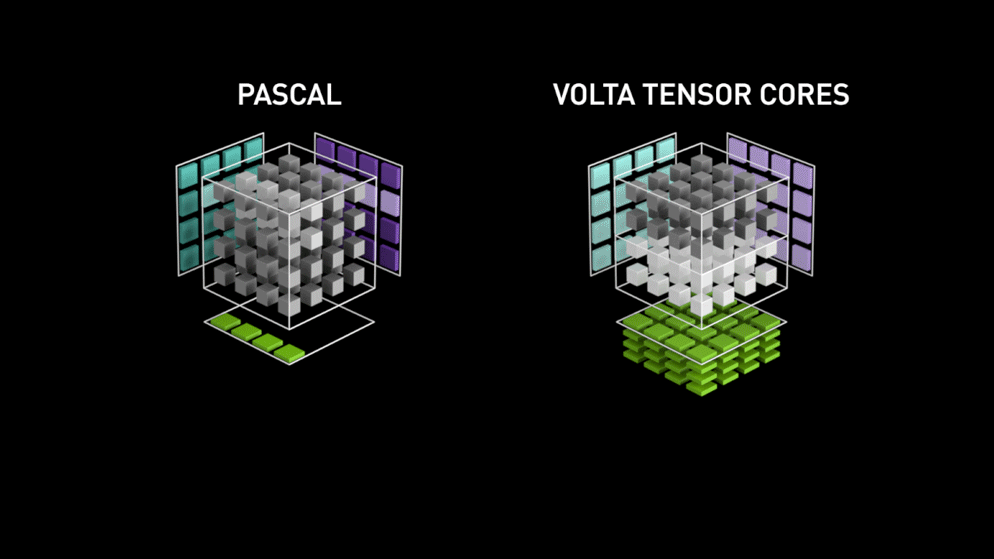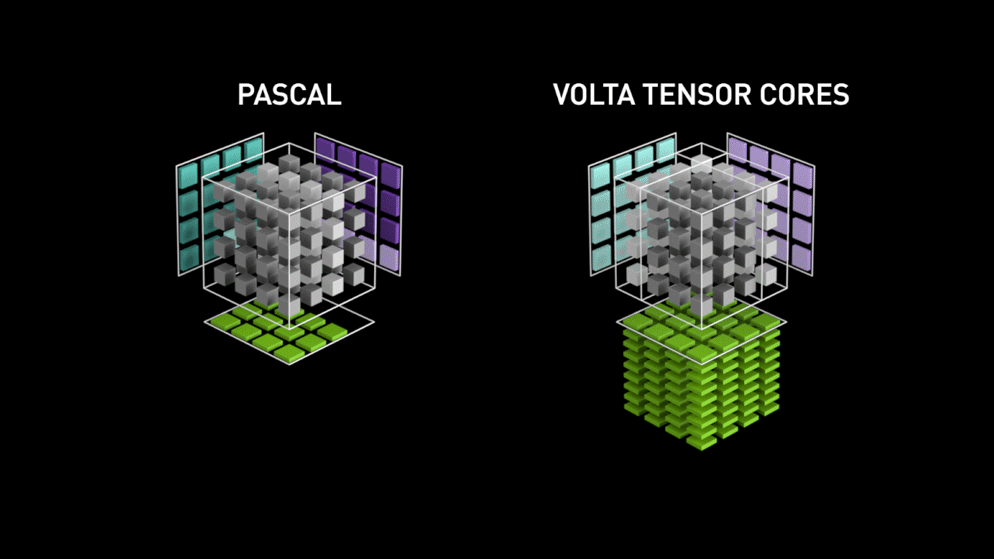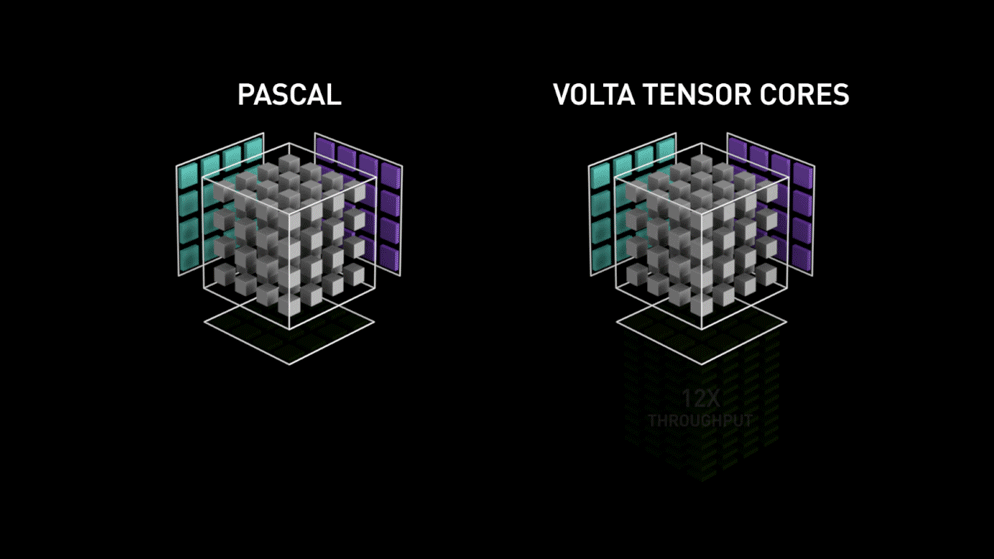
Nagy ugrás a Tensor magokkal!
Még 2018-ban az Nvidia elindította GPU-ik új termékcsaládját, azaz a 2000-es sorozatot. Ezek az RTX-nek is nevezett kártyák a mélytanulásra szánt, Volta architektúrán alapuló tenzormagokkal érkeznek.

A tenzormagok olyan speciális magok, amelyek 4 x 4 FP16-os mátrix szorzását és 4 x 4 FP16-os vagy FP32-es mátrixú összeadást végeznek félpontossággal, a kimenet 4 x 4 FP16 vagy FP32 mátrix lesz teljes pontossággal.
Megjegyzés: Az “FP” a lebegőpontos lebegőpontot jelenti, ha többet szeretne megtudni a lebegőpontról és a pontosságról, nézze meg ezt a blogot.
Az Nvidia állítása szerint a volta architektúrán alapuló új generációs tenzormagok sokkal gyorsabbak, mint a Pascal architektúrán alapuló CUDA magok. Ez hatalmas lökést adott a mélytanulásnak.
A blog írásakor az Nvidia bejelentette GPU-családjának legújabb, 3000-es sorozatát, amely Ampere architektúrával érkezik. Ebben kétszeresére javították a tenzormagok teljesítményét. Emellett új pontossági értékeket is hoztak, mint a TF32(tensor float 32), FP64(floating point 64). A TF32 ugyanúgy működik, mint az FP32, de akár 20-szoros sebességnövekedéssel, mindezek eredményeként az Nvidia állítása szerint a modellek következtetési vagy képzési ideje hetekről órákra csökken.
AMD vs Nvidia

AMD GPU-k tisztességesek játékhoz, de amint a mélytanulás kerül a képbe, akkor egyszerűen az Nvidia messze vezet. Ez nem azt jelenti, hogy az AMD GPU-k rosszak. Ez a szoftveroptimalizálás és a driverek miatt van, amit nem frissítenek aktívan, az Nvidia oldalán jobb driverek vannak gyakori frissítésekkel és ezen felül a CUDA, cuDNN segít felgyorsítani a számításokat.
Néhány ismert könyvtár, mint a Tensorflow, PyTorch támogatja a CUDA-t. Ez azt jelenti, hogy a GTX 1000 sorozatú belépő szintű GPU-k is használhatók. Az AMD oldalán nagyon kevés szoftveres támogatás van a GPU-jaikhoz. Hardveres oldalon az Nvidia dedikált tenzormagokat vezetett be. Az AMD-nek van ROCm gyorsításra, de ez nem olyan jó, mint a tenzormagok, és sok deep learning könyvtár nem támogatja a ROCm-et. Az elmúlt néhány évben nem volt észrevehető nagy ugrás a teljesítmény tekintetében.
Mindezen pontok miatt az Nvidia egyszerűen kiemelkedik a mélytanulásban.
Összefoglaló
Az eddigiek alapján egyértelmű, hogy jelenleg az Nvidia a piacvezető a GPU-k tekintetében, de nagyon remélem, hogy a jövőben még az AMD is felzárkózik, vagy legalábbis figyelemre méltó fejlesztéseket hajt végre a következő GPU-k sorában, mivel a CPU-k tekintetében már most is remek munkát végeznek i.pl. a Ryzen sorozat.
A GPU-k hatóköre a következő években hatalmas, mivel új innovációkat és áttöréseket teszünk a mélytanulás, a gépi tanulás és a HPC területén. A GPU-gyorsítás mindig jól fog jönni sok fejlesztőnek és diáknak, hogy bejusson erre a területre, mivel az áraik is egyre megfizethetőbbé válnak. Köszönet a széles közösségnek is, amely szintén hozzájárul az AI és a HPC fejlődéséhez.
A szerzőről

Prathmesh Patil
ML rajongó, Data Science, Python fejlesztő.
LinkedIn: https://www.linkedin.com/in/prathmesh