Din ultimul deceniu, am văzut GPU-ul intrând mai des în scenă în domenii precum HPC (High-Performance Computing) și cel mai popular domeniu, și anume jocurile. GPU-urile s-au îmbunătățit de la an la an și acum sunt capabile să facă lucruri incredibil de grozave, dar în ultimii câțiva ani, ele captează și mai multă atenție datorită învățării profunde.

Pentru că modelele de învățare profundă petrec o cantitate mare de timp în formare, chiar și CPU-urile puternice nu erau suficient de eficiente pentru a gestiona atât de multe calcule la un moment dat și acesta este domeniul în care GPU-urile au depășit pur și simplu CPU-urile datorită paralelismului lor. Dar înainte de a intra în profunzime, haideți mai întâi să înțelegem câteva lucruri despre GPU.
Ce este GPU?
Un GPU sau „unitate de procesare grafică” este o versiune mini a unui computer întreg, dar dedicat doar unei sarcini specifice. Spre deosebire de o unitate centrală de procesare care efectuează mai multe sarcini în același timp. GPU vine cu propriul procesor care este încorporat pe propria placă de bază, cuplat cu v-ram sau video ram, și, de asemenea, un design termic adecvat pentru ventilație și răcire.
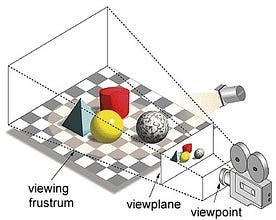
Pe scurt, este modul în care o imagine este formată pe un plan de vizualizare sau pe o pânză în care liniile paralele converg către un punct de convergență numit „centrul de proiecție”, de asemenea, pe măsură ce obiectul se îndepărtează de punctul de vedere, acesta pare mai mic, exact cum arată ochii noștri în lumea reală și acest lucru ajută la înțelegerea profunzimii într-o imagine, acesta fiind motivul pentru care produce imagini realiste.
În plus, GPU-urile procesează și geometrie complexă, vectori, surse de lumină sau iluminări, texturi, forme etc. Deoarece acum avem o idee de bază despre GPU, haideți să înțelegem de ce este foarte utilizat pentru învățarea profundă.
De ce GPU-urile sunt mai bune pentru învățarea profundă?
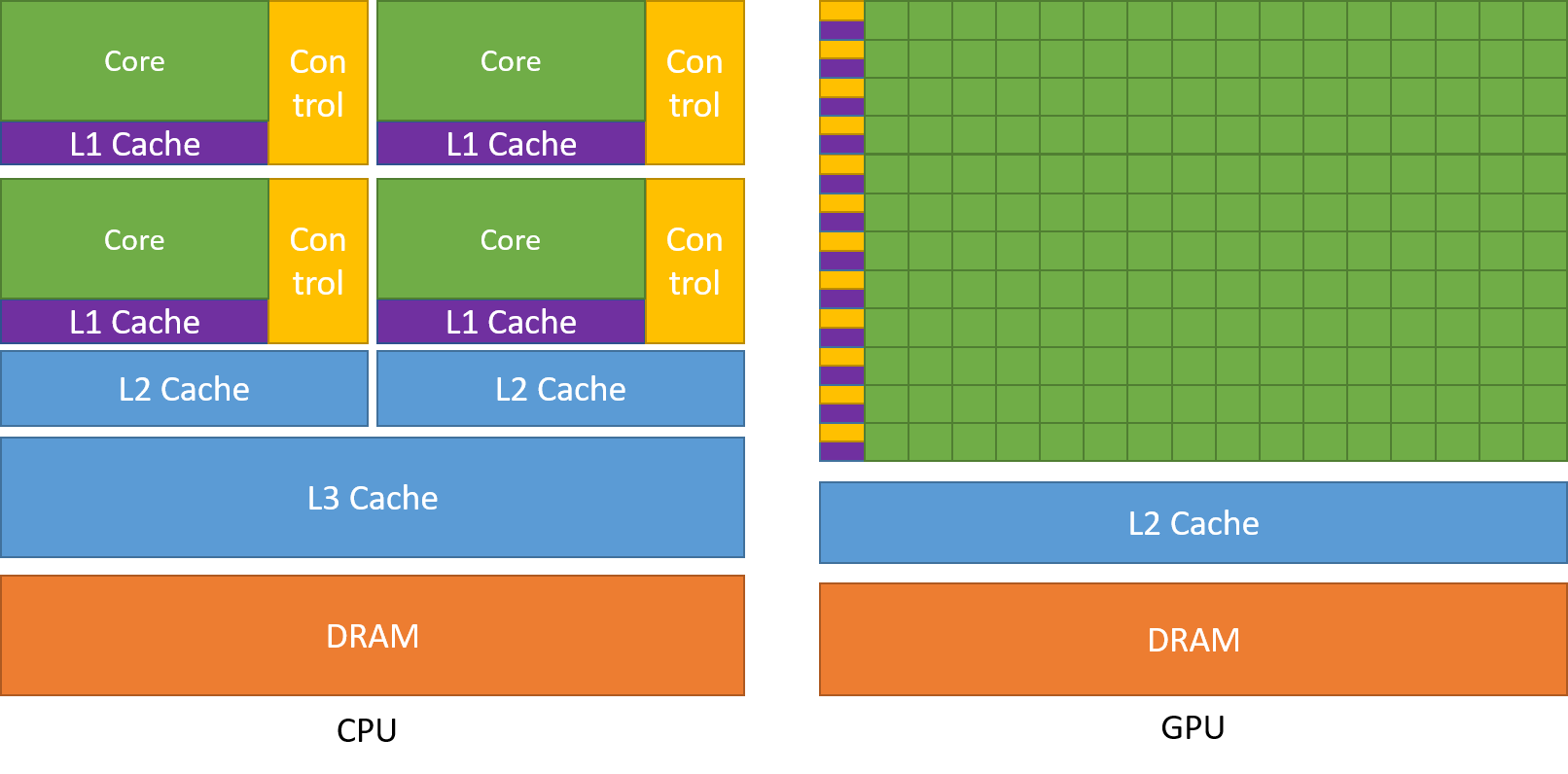
Una dintre cele mai admirate caracteristici ale unui GPU este capacitatea de a calcula procesele în paralel. Acesta este punctul în care intervine conceptul de calcul paralel. Un procesor, în general, își îndeplinește sarcina într-o manieră secvențială. O unitate centrală de procesare poate fi împărțită în nuclee și fiecare nucleu se ocupă de o sarcină la un moment dat. Să presupunem că un CPU are 2 nuclee. Atunci procesele a două sarcini diferite pot rula pe aceste două nuclee, realizând astfel multitasking.
Dar totuși, aceste procese se execută în mod serial.

Unde se află diferența?
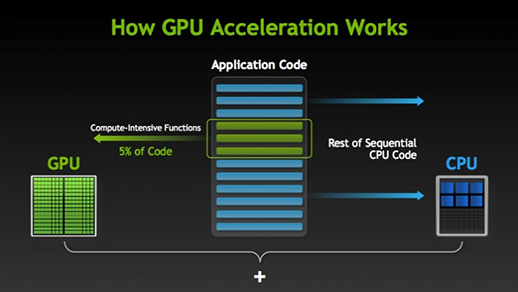
Există multe programe și jocuri care pot profita de GPU pentru execuție. Ideea din spatele acestui lucru este de a face ca unele părți ale sarcinii sau ale codului aplicației să fie paralele, dar nu și procesele întregi. Acest lucru se datorează faptului că majoritatea proceselor sarcinii trebuie să fie executate doar în mod secvențial. De exemplu, conectarea la un sistem sau la o aplicație nu trebuie să se facă în paralel.
Când există o parte a execuției care poate fi realizată în paralel, aceasta este pur și simplu transferată către GPU pentru procesare, unde, în același timp, sarcina secvențială este executată în CPU, apoi ambele părți ale sarcinii sunt din nou combinate împreună.
În piața GPU, există doi jucători principali, și anume AMD și Nvidia. GPU-urile Nvidia sunt utilizate pe scară largă pentru învățarea profundă, deoarece au un sprijin extins în software-ul forumului, drivere, CUDA și cuDNN. Deci, în ceea ce privește AI și învățarea profundă, Nvidia este pionierul de mult timp.
Se spune că rețelele neuronale sunt jenant de paralele, ceea ce înseamnă că calculele din rețelele neuronale pot fi executate în paralel cu ușurință și sunt independente unele de altele.
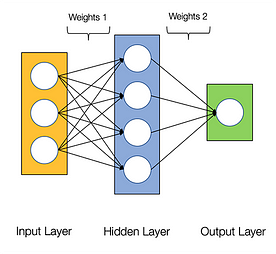
Câteva calcule, cum ar fi calculul ponderilor și al funcțiilor de activare ale fiecărui strat, backpropagarea pot fi efectuate în paralel. Există, de asemenea, multe lucrări de cercetare disponibile pe această temă.
GPU-urile NVIDIA vin cu nuclee specializate, cunoscute sub numele de nuclee CUDA, care ajută la accelerarea învățării profunde.
Ce este CUDA?
CUDA înseamnă „Compute Unified Device Architecture” (Arhitectura dispozitivelor unificate de calcul), care a fost lansată în anul 2007, este o modalitate prin care puteți obține calcul paralel și puteți obține cel mai mult din puterea GPU-ului într-un mod optimizat, ceea ce duce la o performanță mult mai bună în timpul executării sarcinilor.

Mai jos este un program simplu hello world doar pentru a avea o idee despre cum arată codul CUDA.
/* hello world program in cuda *\#include<stdio.h>#include<stdlib.h>#include<cuda.h>__global__ void demo() { printf("hello world!,my first cuda program");}int main() { printf("From main!\n"); demo<<<1,1>>>(); return 0;}

Ce este CUDNN?

cuDNN este o bibliotecă de rețele neuronale care este optimizată pentru GPU și poate profita din plin de Nvidia GPU. Această bibliotecă constă în implementarea convoluției, propagării înainte și înapoi, a funcțiilor de activare și a pooling-ului. Este o bibliotecă obligatorie fără de care nu puteți utiliza GPU pentru antrenarea rețelelor neuronale.
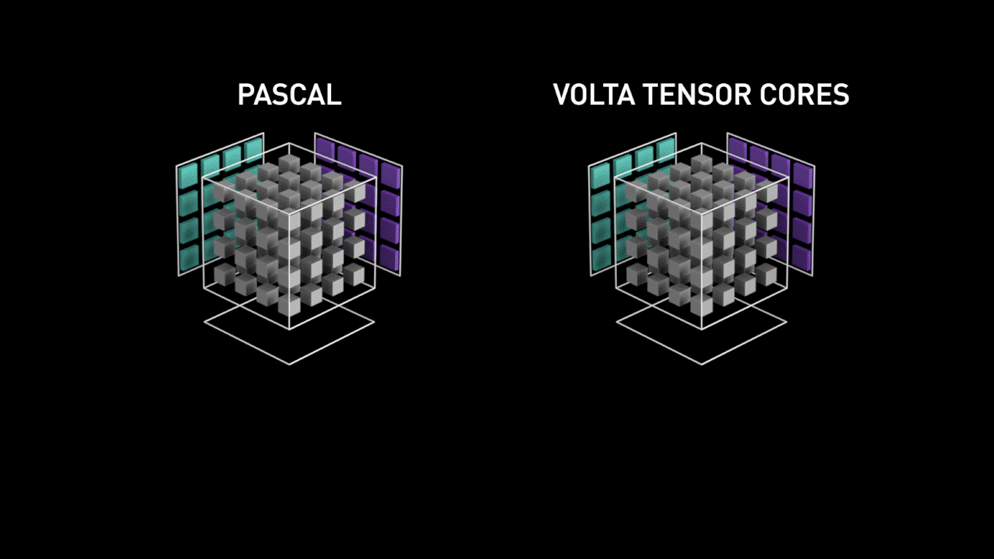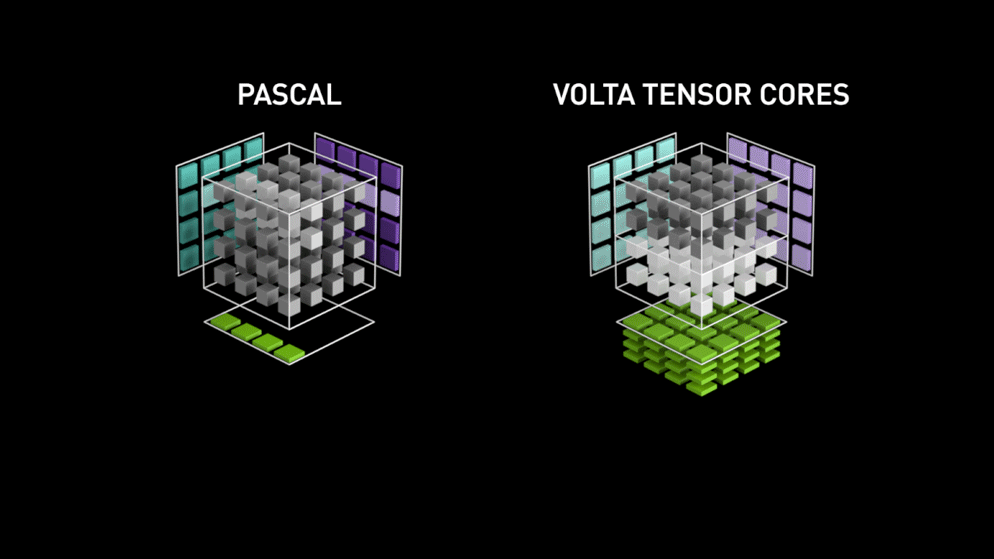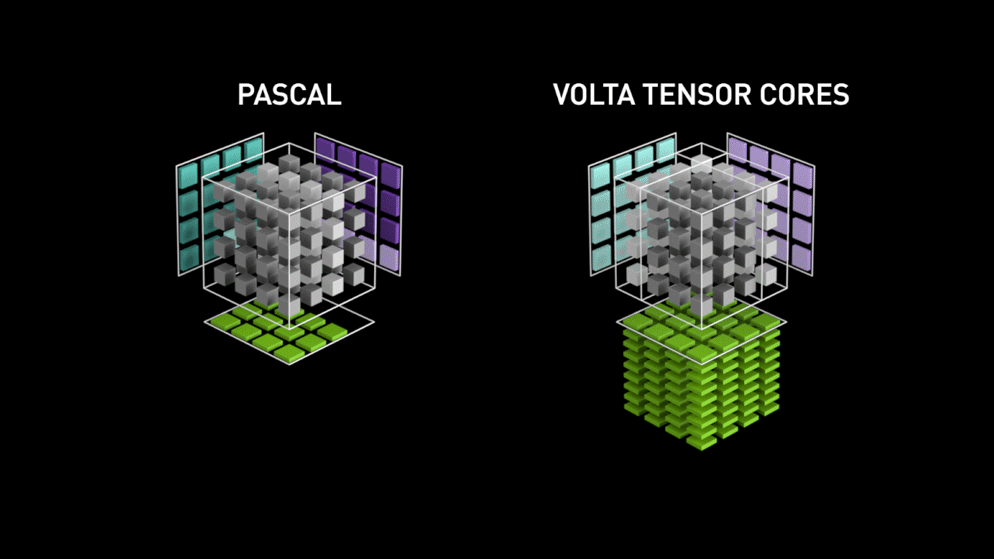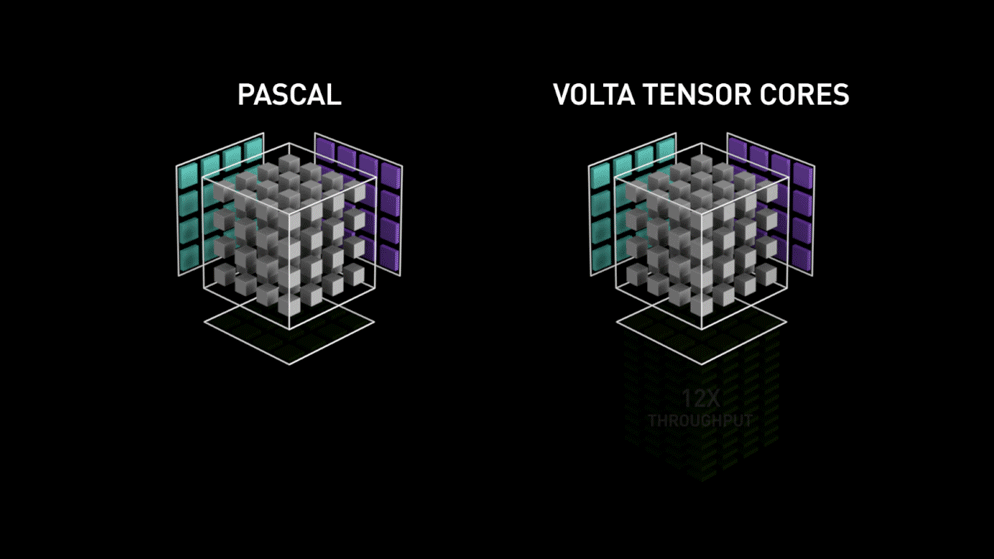
Un salt mare cu nucleele Tensor!
Înapoi în anul 2018, Nvidia a lansat o nouă gamă de GPU-uri ale sale, și anume seria 2000. Denumite și RTX, aceste plăci vin cu nuclee tensoriale care sunt dedicate învățării profunde și se bazează pe arhitectura Volta.

Nota: „FP” reprezintă virgulă mobilă pentru a înțelege mai multe despre virgulă mobilă și precizie, consultați acest blog.
După cum a declarat Nvidia, noua generație de nuclee tensoriale bazate pe arhitectura volta este mult mai rapidă decât nucleele CUDA bazate pe arhitectura Pascal. Acest lucru a dat un impuls uriaș învățării profunde.
În momentul scrierii acestui blog, Nvidia a anunțat cea mai recentă serie 3000 din gama lor de GPU-uri care vin cu arhitectura Ampere. În aceasta, au îmbunătățit performanța nucleelor tensoriale de 2 ori. De asemenea, aducând noi valori de precizie precum TF32(tensor float 32), FP64(floating point 64). TF32 funcționează la fel ca FP32, dar cu o creștere a vitezei de până la 20 de ori, ca urmare a acestui lucru, Nvidia susține că timpul de inferență sau de instruire a modelelor va fi redus de la săptămâni la ore.
AMD vs Nvidia

GPU-urile AMD sunt decente pentru jocuri, dar de îndată ce intră în scenă învățarea profundă, atunci pur și simplu Nvidia este cu mult în față. Aceasta nu înseamnă că GPU-urile AMD sunt rele. Este din cauza optimizării software-ului și a driverelor care nu sunt actualizate în mod activ, pe partea Nvidia au drivere mai bune cu actualizări frecvente și, în plus, CUDA, cuDNN ajută la accelerarea calculului.
Câteva biblioteci bine cunoscute, cum ar fi Tensorflow, PyTorch, susțin CUDA. Aceasta înseamnă că pot fi utilizate GPU-uri entry-level din seria GTX 1000. În ceea ce privește AMD, are foarte puțin suport software pentru GPU-urile lor. În ceea ce privește partea hardware, Nvidia a introdus nuclee tensoriale dedicate. AMD are ROCm pentru accelerare, dar nu este la fel de bun ca nucleele tensoriale, iar multe biblioteci de învățare profundă nu acceptă ROCm. În ultimii câțiva ani, nu s-a observat un salt mare în ceea ce privește performanța.
Datorită tuturor acestor puncte, Nvidia excelează pur și simplu în învățarea profundă.
Rezumat
În concluzie, din tot ceea ce am învățat, este clar că, deocamdată, Nvidia este lider de piață în ceea ce privește GPU, dar sper din tot sufletul ca și AMD să ne ajungă din urmă în viitor sau cel puțin să facă unele îmbunătățiri remarcabile în viitoarea gamă de GPU-uri, deoarece deja fac o treabă excelentă în ceea ce privește CPU-urile lor i.De exemplu, seria Ryzen.
Amplasamentul GPU-urilor în anii următori este uriaș, pe măsură ce vom face noi inovații și progrese în învățarea profundă, învățarea automată și HPC. Accelerarea GPU va fi întotdeauna utilă pentru mulți dezvoltatori și studenți pentru a intra în acest domeniu, deoarece prețurile lor sunt, de asemenea, din ce în ce mai accesibile. De asemenea, mulțumim comunității largi care contribuie, de asemenea, la dezvoltarea inteligenței artificiale și a HPC.
Despre autor

Prathmesh Patil
Prathmesh Patil
Antrionat de ML, Știința datelor, dezvoltator Python.
LinkedIn: https://www.linkedin.com/in/prathmesh