Viime vuosikymmenen aikana olemme nähneet GPU:n tulevan yhä useammin kuvaan sellaisilla aloilla kuin HPC (High-Performance Computing) ja suosituimmalla alalla eli pelaamisessa. Grafiikkasuorittimet ovat parantuneet vuosi vuodelta, ja nyt ne pystyvät tekemään uskomattoman hienoja asioita, mutta viime vuosina ne ovat saaneet vieläkin enemmän huomiota syväoppimisen ansiosta.

Koska syväoppimismallit viettävät paljon aikaa harjoittelussa, edes tehokkaat suorittimet eivät olleet tarpeeksi tehokkaita käsittelemään soo monia laskutoimituksia kerrallaan, ja tällä alalla grafiikkasuorittimet yksinkertaisesti päihittivät suoritinyksiköt rinnakkaisuutensa vuoksi. Mutta ennen kuin sukellamme syvemmälle, ymmärtäkäämme ensin muutamia asioita GPU:sta.
Mikä on GPU?
GPU eli ’Graphics Processing Unit’ on koko tietokoneen miniversio, mutta se on omistettu vain tiettyyn tehtävään. Se eroaa suorittimesta, joka suorittaa useita tehtäviä samanaikaisesti. GPU:lla on oma prosessori, joka on upotettu omalle emolevylle yhdessä v-ram- tai videomuistin kanssa, sekä asianmukainen lämpösuunnittelu ilmanvaihtoa ja jäähdytystä varten.
Lyhyesti sanottuna se on tapa, jolla kuva muodostetaan näkymätasolle tai kankaalle, jossa samansuuntaiset viivat lähenevät toisiaan konvergoituvaan pisteeseen, jota kutsutaan nimellä ”projisointikeskipiste”, ja kun objekti siirtyy poispäin näkymäkohdasta, se näyttää pienemmältä, juuri niin kuin silmämme kuvaavat reaalimaailmassa, ja tämä auttaa ymmärtämään kuvan syvyyttä, minkä vuoksi se tuottaa realistisia kuvia.
Lisäksi GPU:t käsittelevät myös monimutkaista geometriaa, vektoreita, valonlähteitä tai valaistusta, tekstuureja, muotoja jne. Koska meillä on nyt peruskäsitys GPU:sta, ymmärtäkäämme, miksi sitä käytetään voimakkaasti syväoppimiseen.
Miksi GPU:t ovat parempia syväoppimiseen?
Yksi GPU:n ihailluimmista ominaisuuksista on kyky laskea prosesseja rinnakkain. Tässä kohtaa rinnakkaislaskennan käsite astuu kuvaan. Suoritin suorittaa tehtävänsä yleensä peräkkäin. Suoritin voidaan jakaa ytimiin, ja kukin ydin suorittaa yhden tehtävän kerrallaan. Oletetaan, että suorittimessa on 2 ydintä. Silloin näillä kahdella ytimellä voidaan suorittaa kaksi eri tehtäväprosessia, jolloin saavutetaan monitehtäväisyys.
Mutta silti nämä prosessit suoritetaan sarjamuodossa.

Tämä ei tarkoita, etteivätkö suorittimet olisi tarpeeksi hyviä. Itse asiassa suorittimet ovat todella hyviä hoitamaan eri toimintoihin liittyviä tehtäviä, kuten käyttöjärjestelmien käsittelyä, taulukkolaskentataulukoiden käsittelyä, HD-videoiden toistoa ja suurten zip-tiedostojen purkamista, kaikki samaan aikaan. Nämä ovat joitakin asioita, joita näytönohjain ei yksinkertaisesti pysty tekemään.
Missä ero on?
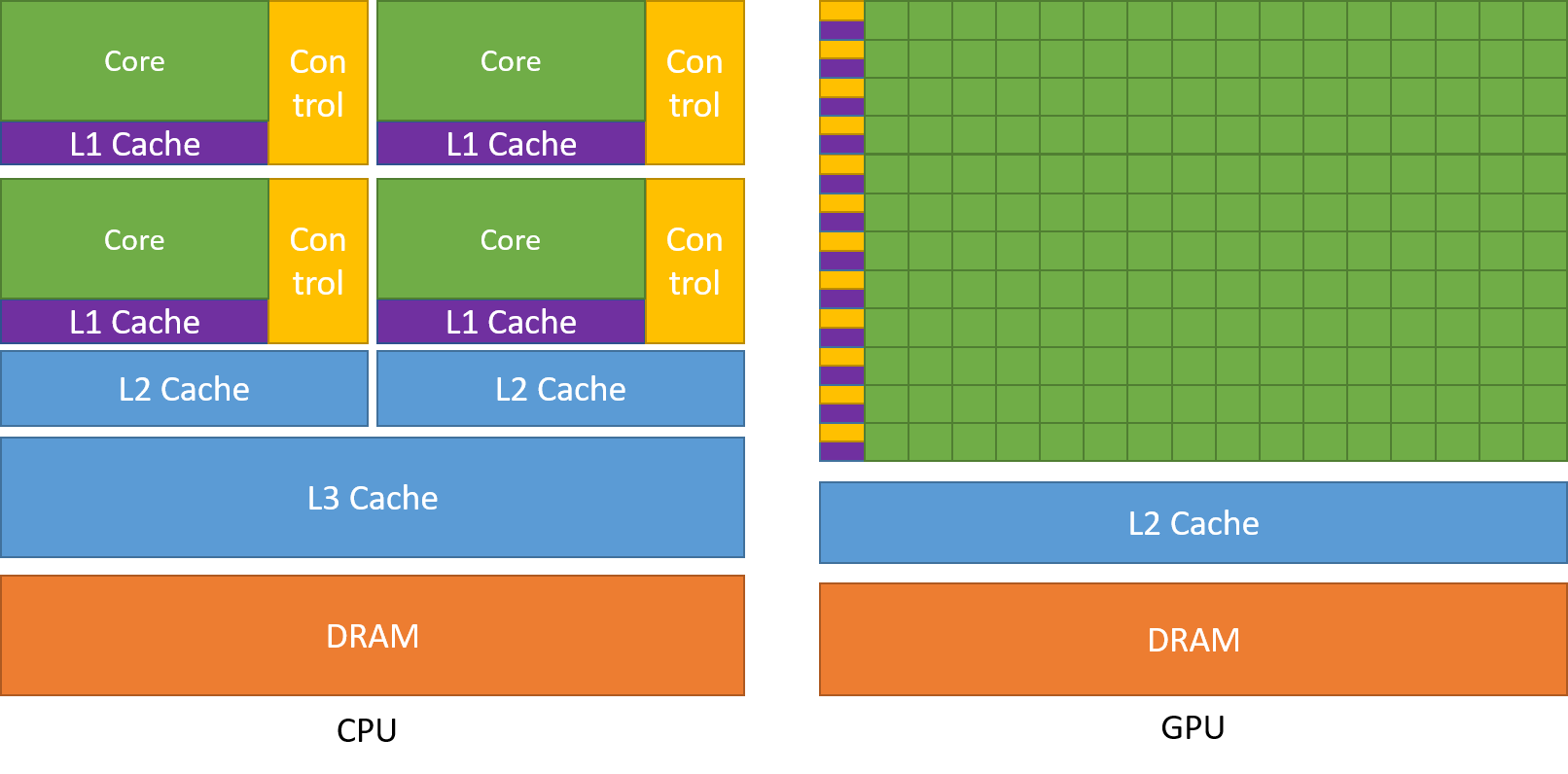
Kuten aiemmin on käsitelty, suorittimen prosessori on jaettu useisiin ytimiin niin, että ne pystyvät hoitamaan useampia tehtäviä samaan aikaan, kun taas grafiikkasuorittimessa on satoja ja tuhansia ytimiä, jotka kaikki keskittyvät yhteen tehtävään. Nämä ovat yksinkertaisia laskutoimituksia, joita suoritetaan useammin ja jotka ovat toisistaan riippumattomia. Ja molemmat tallentavat usein tarvittavia tietoja omiin välimuisteihinsa, jolloin noudatetaan ”locality reference” -periaatetta.
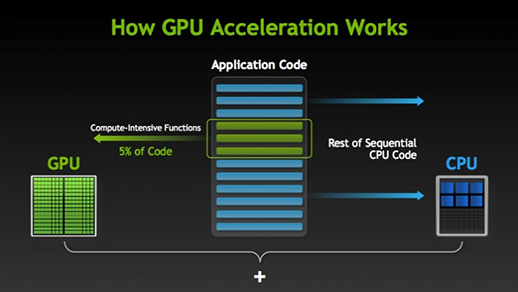
On olemassa monia ohjelmistoja ja pelejä, jotka pystyvät hyötymään grafiikkasuorittimista suorituksessa. Ajatuksena on tehdä joistakin tehtävä- tai sovelluskoodin osista rinnakkaisia, mutta ei koko prosesseista. Tämä johtuu siitä, että suurin osa tehtävän prosesseista on suoritettava vain peräkkäin. Esimerkiksi kirjautumista järjestelmään tai sovellukseen ei tarvitse tehdä rinnakkain.
Kun osa suorituksesta voidaan tehdä rinnakkain, se yksinkertaisesti siirretään GPU:lle prosessoitavaksi, jolloin samaan aikaan peräkkäinen tehtävä suoritetaan CPU:lla, minkä jälkeen tehtävän molemmat osat yhdistetään jälleen yhteen.
Grafiikkasuorittimien markkinoilla on kaksi tärkeintä toimijaa eli AMD ja Nvidia. Nvidian näytönohjaimia käytetään laajalti syväoppimiseen, koska niillä on laaja tuki foorumiohjelmistoissa, ajureissa, CUDA:ssa ja cuDNN:ssä. Nvidia on siis tekoälyn ja syväoppimisen suhteen edelläkävijä jo pitkään.
Neuraaliverkkojen sanotaan olevan kiusallisen rinnakkaisia, mikä tarkoittaa, että neuroverkoissa tehtävät laskutoimitukset voidaan suorittaa rinnakkain helposti ja ne ovat toisistaan riippumattomia.
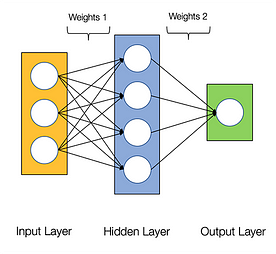
Joitakin laskutoimituksia, kuten kunkin kerroksen painojen ja aktivointifunktioiden laskeminen, backpropagointi, voidaan suorittaa rinnakkain. Siitä on saatavilla myös monia tutkimuspapereita.
Nvidian näytönohjaimissa on erikoistuneita ytimiä, joita kutsutaan CUDA-ytimiksi ja jotka auttavat syväoppimisen kiihdyttämisessä.
Mikä on CUDA?
CUDA on lyhenne sanoista ’Compute Unified Device Architecture’ (yhtenäinen laskentalaitearkkitehtuuri), joka lanseerattiin vuonna 2007, ja se on keino, jolla rinnakkaislaskenta saadaan aikaan ja jolla GPU:n teho voidaan hyödyntää parhaalla mahdollisella tavalla optimoidussa muodossa, mikä johtaa paljon parempaan suorituskykyyn tehtävien suorittamisen aikana.

CUDA-työkalupakki on täydellinen paketti, joka koostuu kehitysympäristöstä, jota käytetään näytönohjaimia hyödyntävien sovellusten rakentamiseen. Tämä työkalupakki sisältää pääasiassa c/c++-kääntäjän, debuggerin ja kirjastoja. Lisäksi CUDA-runtime sisältää ajurit, jotta se voi kommunikoida GPU:n kanssa. CUDA on myös ohjelmointikieli, joka on erityisesti tehty GPU:n ohjeistamiseen tehtävän suorittamiseksi. Se tunnetaan myös nimellä GPU-ohjelmointi.
Alhaalla on yksinkertainen hello world -ohjelma vain saadaksemme käsityksen siitä, miltä CUDA-koodi näyttää.
/* hello world program in cuda *\#include<stdio.h>#include<stdlib.h>#include<cuda.h>__global__ void demo() { printf("hello world!,my first cuda program");}int main() { printf("From main!\n"); demo<<<1,1>>>(); return 0;}

Mikä on cuDNN?

cuDNN on neuroverkkokirjasto, joka on optimoitu GPU:lle ja joka pystyy hyödyntämään Nvidian GPU:ta täysin. Tämä kirjasto koostuu konvoluution, eteen- ja taaksepäin etenemisen, aktivointifunktioiden ja poolingin toteutuksesta. Se on välttämätön kirjasto, jota ilman et voi käyttää GPU:ta neuroverkkojen harjoitteluun.
Suuri harppaus Tensor-ytimillä!
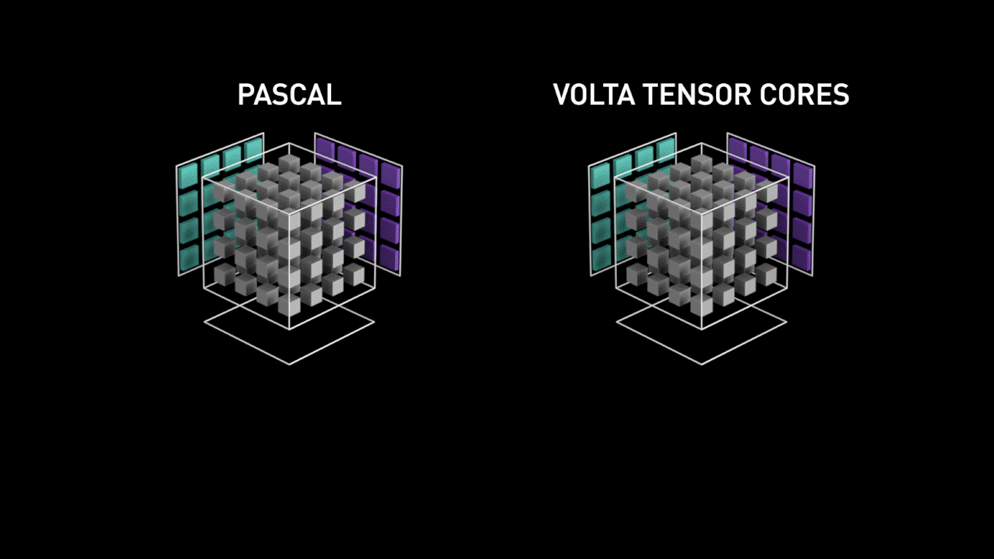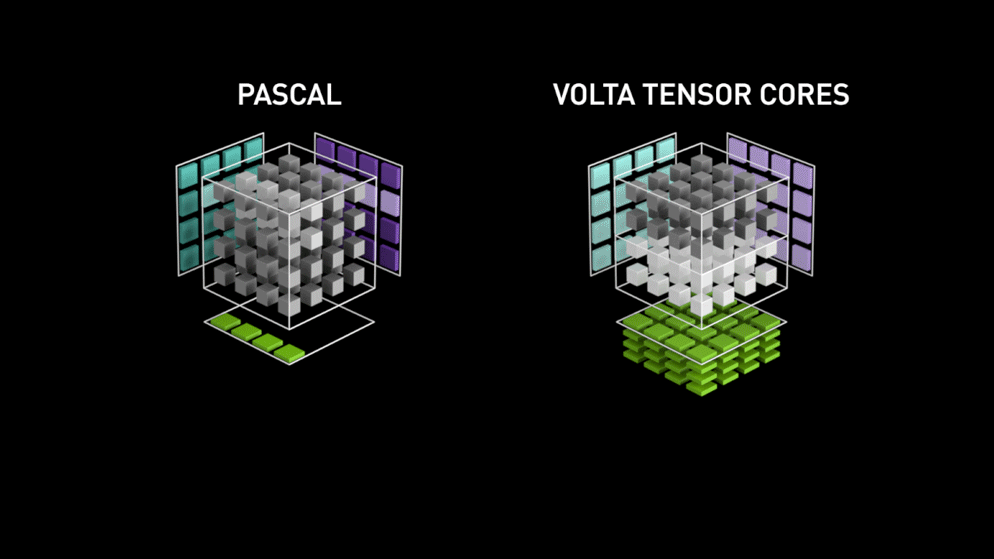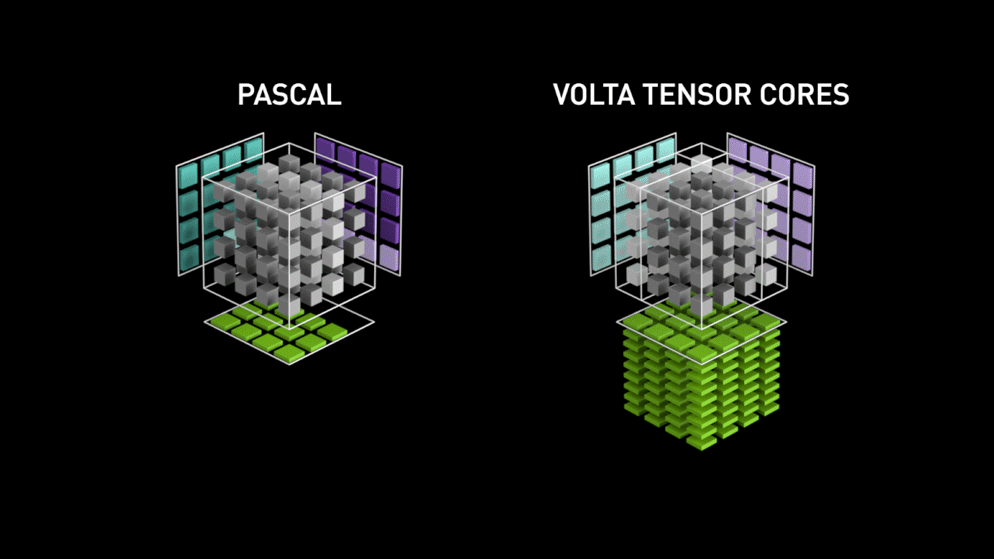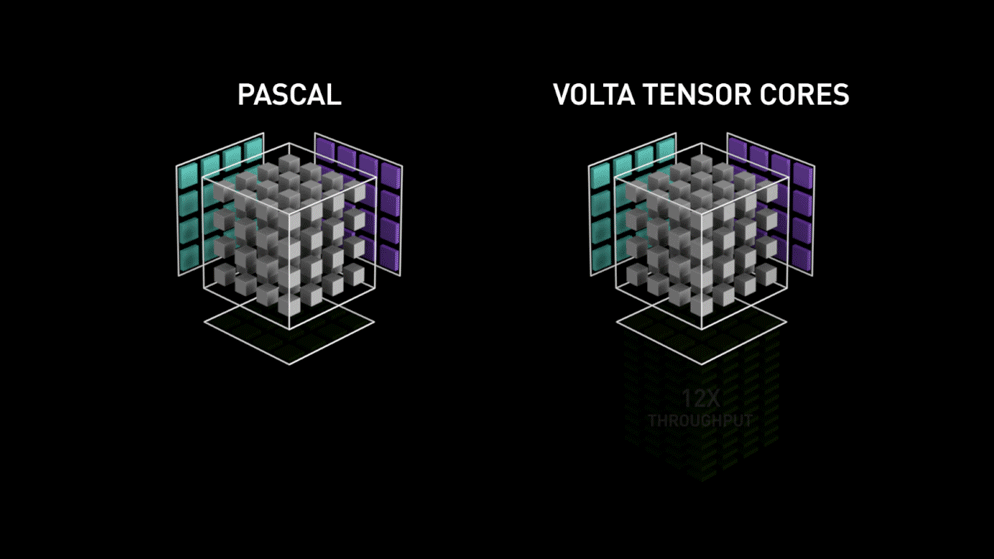
Takana vuonna 2018 Nvidia lanseerasi uuden GPU-malliston eli 2000-sarjan. Nämä myös RTX:ksi kutsutut kortit tulevat tensor-ytimillä, jotka on omistettu syväoppimiselle ja jotka perustuvat Volta-arkkitehtuuriin.

Tensorisydämet ovat erityisiä ytimiä, jotka suorittavat matriisien kertolaskun 4 x 4 FP16-matriisilla ja yhteenlaskun 4 x 4 FP16- tai FP32-matriisin kanssa puolitarkkuudella, tuloksena saadaan 4 x 4 FP16- tai FP32-matriisi täydellä tarkkuudella.
Huomautus: ’FP’ tarkoittaa liukulukua, jos haluat ymmärtää enemmän liukuluvusta ja tarkkuudesta, katso tämä blogi.
Kuten Nvidia on todennut, Volta-arkkitehtuuriin perustuvat uuden sukupolven tensorisydämet ovat paljon nopeampia kuin Pascal-arkkitehtuuriin perustuvat CUDA-ytimet. Tämä antoi valtavan sysäyksen syväoppimiselle.
Tätä blogia kirjoittaessa Nvidia julkisti uusimmat 3000-sarjan näytönohjaimensa, jotka tulevat Ampere-arkkitehtuurilla. Tässä he paransivat tensor-ytimien suorituskykyä 2x. Toivat myös uusia tarkkuusarvoja kuten TF32(tensor float 32), FP64(floating point 64). TF32 toimii samoin kuin FP32, mutta sen nopeus on jopa 20-kertainen, ja Nvidia väittää, että mallien päättely- tai harjoitteluaika lyhenee viikoista tunteihin.
AMD vs Nvidia

Jotkut tunnetut kirjastot kuten Tensorflow, PyTorch tukevat CUDA:ta. Se tarkoittaa, että GTX 1000 -sarjan lähtötason näytönohjaimia voi käyttää. AMD:n puolella on hyvin vähän ohjelmistotukea heidän näytönohjaimilleen. Laitteistopuolella Nvidia on ottanut käyttöön dedikoituja tensorisydämiä. AMD:llä on ROCm kiihdytykseen, mutta se ei ole yhtä hyvä kuin tensorisydämet, ja monet syväoppimiskirjastot eivät tue ROCm:ää. Viime vuosina suorituskyvyssä ei ole havaittu suurta harppausta.
Kaikkien näiden seikkojen vuoksi Nvidia yksinkertaisesti loistaa syväoppimisessa.
Yhteenveto
Johtopäätöksenä kaikesta oppimastamme on selvää, että tällä hetkellä Nvidia on markkinajohtaja näytönohjainten osalta, mutta toivon todella, että jopa AMD ottaa tulevaisuudessa kiinni tai ainakin tekee joitain merkittäviä parannuksia tulevassa näytönohjaintensa mallistossa, koska he tekevät jo nyt erinomaista työtä CPU:nsa osalta i.e Ryzen-sarja.
Näytönohjainten merkitys tulevina vuosina on valtava, kun teemme uusia innovaatioita ja läpimurtoja syväoppimisessa, koneoppimisessa ja HPC:ssä. GPU-kiihdytys tulee aina olemaan kätevä monille kehittäjille ja opiskelijoille, jotta he pääsevät tälle alalle, koska niiden hinnat ovat myös entistä edullisempia. Kiitos myös laajalle yhteisölle, joka myös edistää tekoälyn ja HPC:n kehitystä.
Tekijästä

Prathmesh Patil
ML-harrastaja, Data Science, Python-kehittäjä.
LinkedIn: https://www.linkedin.com/in/prathmesh